
来自谷歌的研究人员推出视频编码器VideoPrism,它是一个通用的视频理解模型,能够处理多种视频理解任务,如分类、定位、检索、字幕生成和问答(QA)。VideoPrism通过在一个单一的冻结模型上进行预训练,实现了在多个视频理解基准测试中的最先进性能。
VideoPrism是一个强大的视频理解工具,它通过大规模预训练和精心设计的模型架构,能够在多种视频理解任务上实现高效和准确的性能。

主要功能:
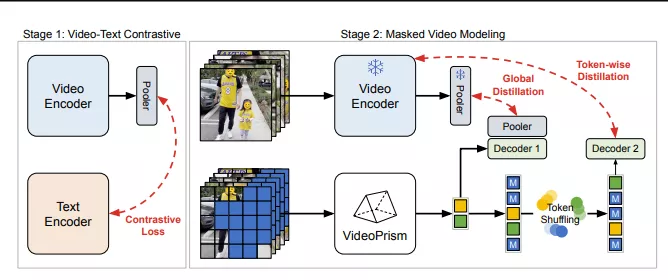
它的主要功能是使用单一的冻结模型来处理各种各样的视频理解任务。这个编码器在预训练阶段使用了包含3600万个高质量视频-字幕对和5.82亿个带有噪声的并行文本(例如,自动语音识别转录)的异构语料库。这种预训练方法改进了基于掩码的自动编码,通过全局-本地语义视频嵌入的蒸馏和令牌洗牌方案,使VideoPrism主要关注视频模态。
- 提供一个通用的视频编码器,能够处理多种视频理解任务。
- 在视频分类、定位、检索和字幕生成等任务上实现最先进的性能。
- 通过预训练,VideoPrism能够从视频数据中学习到丰富的视觉语义信息。
主要特点:
- 大规模预训练数据集: VideoPrism使用了包含3600万个高质量视频-字幕对和5.82亿个视频片段的预训练数据集,这些数据集包含了丰富的视频内容和相关的文本描述。
- 两阶段预训练策略: 第一阶段通过视频-文本对比学习来训练视频和文本编码器,第二阶段则通过改进的遮蔽视频建模来进一步训练视频编码器,同时利用全局和局部蒸馏损失来保留第一阶段的知识。
- 鲁棒性: VideoPrism在多种视频理解任务上表现出色,无论是基于外观的任务还是基于运动的任务。
工作原理:
- 第一阶段(视频-文本对比训练): 使用所有视频-文本对进行对比学习,通过最小化相似性分数的对称交叉熵损失来训练视频和文本编码器,从而学习丰富的视觉语义。
- 第二阶段(遮蔽视频建模): 在视频-only数据上继续训练视频编码器,通过预测视频的全局语义嵌入和基于未遮蔽输入视频块的token-wise嵌入,同时应用随机token洗牌和全局蒸馏损失来避免学习捷径并有效利用第一阶段的知识。
具体应用场景:
- 视频分类和定位: 在视频分类(如Kinetics-400)和定位任务(如ActivityNet)上,VideoPrism能够识别视频中的动作和对象。
- 视频-文本检索: VideoPrism能够实现零样本(zero-shot)视频-文本检索,即在没有额外训练的情况下,根据文本描述找到相关视频。
- 视频字幕和问答: VideoPrism可以与语言模型结合,生成视频字幕或回答关于视频内容的问题。
- 科学视频分析: VideoPrism在科学领域的视频数据集上也表现出色,如动物行为分析,这表明它在科学研究中的应用潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











