
字节跳动推出一个基于DiT模型的人类图像动画框架DreamActor-M1,实现整体性(holistic)、表现力(expressive)和鲁棒性(robust)的人类图像动画生成。该框架通过混合引导信号(hybrid guidance)来解决现有图像动画方法在细粒度整体可控性、多尺度适应性和长期时间连贯性方面的不足,从而实现更自然、更逼真的人类动画效果。
例如,有一个单张人物肖像图像,DreamActor-M1可以将其动画化,使人物能够进行各种复杂的动作,如眨眼、微笑、转身甚至跳舞,同时保持人物的身份特征和表情细节。此外,该框架还可以处理从半身像到全身像的不同尺度输入,并在长视频生成中保持连贯性,即使在参考图像中未显示的区域(如背部衣物)也能保持一致。

主要功能
- 细粒度整体控制:能够精确控制面部表情(如眨眼、微笑)和身体动作(如转身、跳舞)。
- 多尺度适应性:支持从肖像到全身像的多种输入尺度,并生成高质量的动画。
- 长期时间连贯性:在长视频生成中保持连贯性,尤其是在参考图像中未显示的区域。
- 身份保持:在动画生成过程中保持人物的身份特征,避免出现身份混淆或失真的问题。
- 可扩展性:支持多种输入方式,包括视频驱动和音频驱动(如通过语音信号控制面部表情)。
主要特点
- 混合引导信号(Hybrid Guidance):结合隐式面部表示、3D头部球体和3D身体骨架,实现对人物动画的精细控制。
- 互补外观引导(Complementary Appearance Guidance):通过生成伪参考图像来填补未见区域的信息,增强长期连贯性。
- 渐进式训练策略(Progressive Training Strategy):通过分阶段训练,逐步引入不同控制信号,提高模型的稳定性和适应性。
- 鲁棒性:在多尺度输入和复杂动作下保持稳定,避免信息丢失和连贯性问题。
- 高表现力:能够生成逼真的面部表情和身体动作,同时保持人物的身份特征。
工作原理
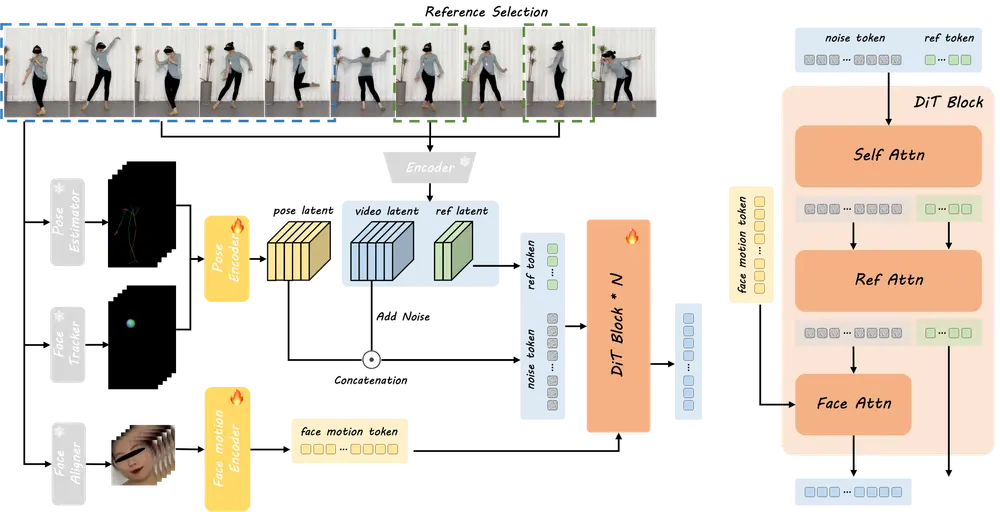
DreamActor-M1的核心是基于扩散变换器(DiT)的框架,通过以下关键步骤实现其功能:
- 混合控制信号:
- 隐式面部表示:通过预训练的面部运动编码器提取面部表情特征,避免使用传统的面部关键点,从而更好地捕捉细微表情变化。
- 3D头部球体:独立控制头部姿态,通过渲染一个与头部姿态相关的3D球体来提供头部位置和旋转信息。
- 3D身体骨架:通过估计身体和手部参数,生成2D投影的骨架图,用于控制身体动作。
- 互补外观引导:在训练阶段,选择关键帧作为参考图像,提供不同视角和局部细节的信息。在推理阶段,通过生成伪参考图像来填补未见区域的信息,增强长期连贯性。
- 渐进式训练:分三个阶段训练模型:
- 第一阶段:仅使用3D身体骨架和3D头部球体进行训练。
- 第二阶段:引入隐式面部表示,训练面部运动编码器。
- 第三阶段:解冻所有参数,进行联合优化。
- 生成过程:在推理阶段,将混合控制信号和参考图像输入到DiT模型中,生成动画视频。对于长视频生成,使用上一段的最后一个潜在特征作为下一段的初始特征,确保连贯性。
应用场景
- 影视制作:用于生成虚拟角色的动画,减少手工建模和动画制作的时间和成本。
- 广告行业:创建动态的人物广告,使人物能够进行各种动作和表情,增强广告的吸引力。
- 视频游戏:生成游戏中的角色动画,提高游戏的沉浸感和真实感。
- 虚拟主播:为虚拟主播提供更自然、更逼真的动画效果,增强观众的观看体验。
- 教育与培训:创建动态的教学视频,使人物能够进行各种动作和表情,提高教学效果。
- 社交媒体:生成个性化的动态头像或短视频,增强用户的互动性和趣味性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











