
快手和新加坡国立大学的研究人员推出新型框架 Any2Caption ,通过将多样化的输入条件(如文本、图像、视频、人体姿态、相机运动等)转化为结构化的详细字幕,从而实现可控的视频生成。这一框架的核心思想是将条件解释(理解用户输入的各种条件)与视频合成(生成视频)这两个任务解耦,利用多模态大语言模型(MLLMs)来处理复杂的输入条件,并生成能够指导视频生成器的详细字幕。
例如,用户希望生成一个视频,描述的场景是“一个穿着时尚的女性在繁忙的城市中行走,背景是高楼大厦和繁忙的街道”。用户可以提供以下输入条件:
- 文本描述:“时尚女性在城市中行走”
- 深度图:显示场景的深度信息
- 人体姿态序列:显示女性的行走姿态
- 相机运动轨迹:描述相机如何跟随女性移动
Any2Caption 将这些条件转化为一个详细的结构化字幕,例如:
- 密集字幕:一个穿着时尚的女性在繁忙的城市街道上行走,周围是高楼大厦。
- 主要对象字幕:女性穿着黑色夹克,背着一个包。
- 背景字幕:背景是繁忙的城市街道,有高楼大厦和行人。
- 相机字幕:相机从侧面跟随女性,逐渐拉远镜头。
- 风格字幕:视频风格现代、明亮且充满活力。
- 动作字幕:女性自信地行走,偶尔调整她的包。
这个结构化字幕随后被输入到任何现有的视频生成器中,生成符合用户期望的视频。
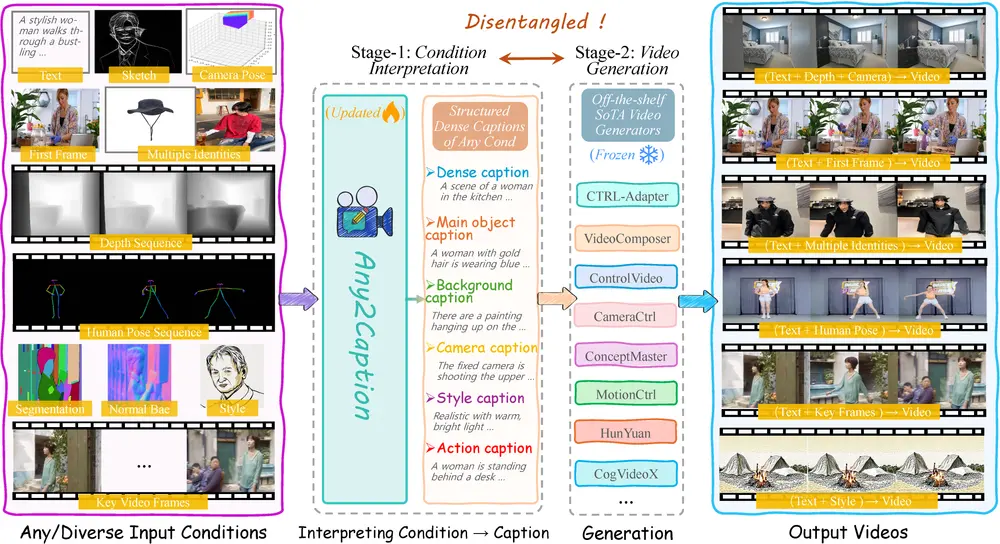
主要功能
- 条件解释:将多样化的输入条件(如文本、图像、视频、人体姿态、相机运动等)转化为详细的结构化字幕。
- 视频生成:将生成的结构化字幕输入到现有的视频生成器中,生成高质量、可控的视频。
- 数据集支持:提供了一个大规模数据集 Any2CapIns,包含 337K 视频实例和 407K 条条件标注,用于训练和评估条件到字幕的转换任务。
主要特点
- 多模态输入支持:能够处理文本、图像、视频、人体姿态、相机运动等多种输入条件。
- 结构化输出:生成详细的结构化字幕,包含场景的多个方面(如主要对象、背景、相机运动、风格等)。
- 与现有视频生成器无缝集成:无需对现有视频生成器进行额外的微调,即可直接使用生成的字幕进行视频生成。
- 高可控性:通过详细的字幕,用户可以更精确地控制视频生成的内容,包括场景布局、对象动作、相机运动等。
工作原理
- 条件输入:用户提供多样化的输入条件,如文本描述、图像、视频、人体姿态、相机运动等。
- 条件解释:Any2Caption 使用多模态大语言模型(MLLMs)对输入条件进行解释,提取关键信息。
- 字幕生成:根据输入条件生成详细的结构化字幕,包含多个方面的描述(如密集字幕、主要对象字幕、背景字幕等)。
- 视频生成:将生成的结构化字幕输入到现有的视频生成器中,生成符合用户期望的视频。
应用场景
- 影视制作:通过提供详细的场景描述和相机运动轨迹,帮助生成高质量的视频片段,减少拍摄成本。
- 动画制作:利用人体姿态和风格描述,生成符合特定风格的动画视频。
- 虚拟现实和增强现实:根据用户的输入条件生成沉浸式的虚拟场景。
- 广告和营销:快速生成符合特定主题和风格的视频广告。
- 教育和培训:生成用于教学的视频内容,如模拟实验、历史场景重现等。
通过 Any2Caption,用户可以更灵活地控制视频生成的内容,提高视频生成的质量和可控性,适用于多种需要高质量视频生成的场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











