视频生成是AI研究的一个热点领域,特别是在生成时间上一致、高保真的视频方面。这一领域涉及创建在帧之间保持视觉连贯性并在时间上保留细节的视频序列。近年来,机器学习模型,尤其是扩散变换器(DiTs),已成为这些任务的强大工具,其生成质量远超以往的 GAN 和 VAE 方法。然而,随着模型复杂度的增加,生成高分辨率视频的计算成本和延迟成为了一个重大挑战。研究人员现在专注于提高这些模型的效率,以实现更快的实时视频生成,同时保持高质量标准。
当前挑战
1、资源密集型特性:
生成复杂、视觉上吸引人的视频需要大量的处理能力,特别是对于处理更长、高分辨率视频序列的大型模型。 这些需求减慢了推理过程,使得实时生成变得困难。 许多视频应用需要能够在快速处理数据的同时提供高保真度的模型。
2、速度与质量的权衡:
更快的生成速度通常会牺牲细节,而高质量的方法往往计算量大且缓慢。 找到处理速度和输出质量之间的最佳平衡是当前的一个关键问题。
优化方法
为了应对这些挑战,研究人员已经引入了多种优化方法,包括:
步骤蒸馏:通过将复杂任务简化为更简单的形式来减少实现质量所需的步骤数量。 潜在扩散:旨在提高整体质量与延迟的比率。 缓存技术:存储先前计算的步骤以避免重复计算。
然而,这些方法在处理复杂性、运动和纹理差异很大的视频时,适应性较差,导致效率低下。
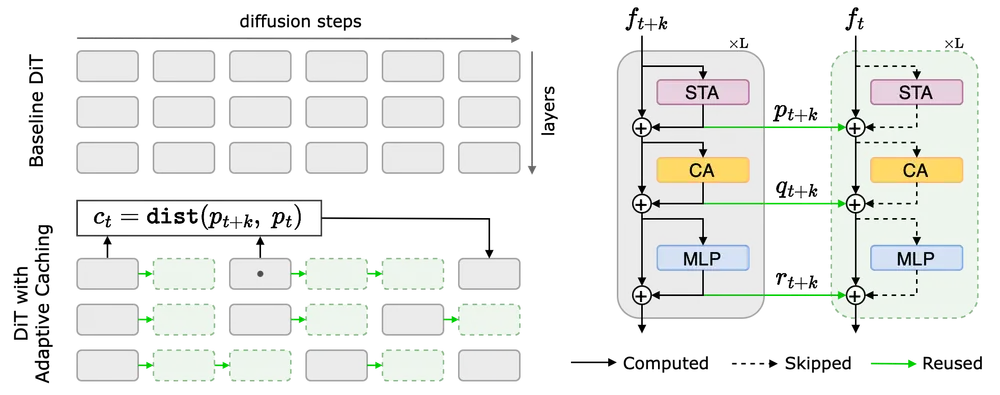
自适应缓存(AdaCache)
来自 Meta AI 和石溪大学的研究人员提出了一种名为自适应缓存(AdaCache)的创新解决方案,旨在在不进行额外训练的情况下加速视频扩散变换器(Diffusion Transformers,简称DiTs)。AdaCache 是一种无需训练的技术,可以集成到各种视频 DiT 模型中,通过动态缓存计算来简化处理时间。这项技术特别针对生成高保真度、时间一致性视频的计算成本高昂的问题,尤其是在处理长时间跨度的视频时。
例如,我们要生成一段720p分辨率、2秒长的视频。传统的DiTs可能需要大量的计算步骤和资源来生成高质量的视频。而AdaCache技术可以减少这些计算步骤,同时保持视频质量,从而显著加快视频生成的速度。

主要功能:
加速视频DiTs的推理过程:通过缓存和重用计算结果,减少不必要的重复计算。 内容依赖的缓存调度:根据视频内容的复杂性动态调整缓存策略,以实现最佳的质量-延迟权衡。
主要特点
1、动态缓存:
AdaCache 通过缓存变换器架构中的某些残差计算来运行,允许这些计算在多个步骤中重复使用。 该方法特别高效,因为它避免了重复处理步骤,这是视频生成任务中的常见瓶颈。
2、自适应缓存计划:
AdaCache 使用为每个视频量身定制的缓存计划来确定重新计算或重复使用残差数据的最佳点。 缓存计划基于评估帧间数据变化率的指标,确保在最有效的位置分配计算资源。
3、运动正则化(MoReg):
MoReg 机制将更多计算资源分配给需要更细致关注细节的高运动场景。 通过使用轻量级距离度量和基于运动的正则化因子,AdaCache 在速度和质量之间取得平衡,根据视频的运动内容调整计算焦点。
实验结果
研究团队进行了一系列测试来评估 AdaCache 的性能。结果显示:
显著提升速度:在涉及 Open-Sora 的 720p 2 秒视频生成的测试中,AdaCache 记录的速度比之前的方法快 4.7 倍,同时保持了可比的视频质量。 灵活的变体:AdaCache 提供了多种变体,如“AdaCache-fast”和“AdaCache-slow”,可以根据速度或质量需求进行选择。 增强的质量:通过 MoReg,AdaCache 展示了增强的质量,与人类在视觉评估中的偏好高度一致,并优于传统缓存方法。 广泛的适用性:不同 DiT 模型的速度基准测试也证实了 AdaCache 的优越性,速度提升范围从 1.46 倍到 4.7 倍不等,具体取决于配置和质量要求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











