
Little Language Lessons
谷歌推出了三项基于其多模态大模型 Gemini 的 AI 实验项目,旨在通过更加个性化、情境化的方式帮助人们提升口语表达能力。些 AI 实验工具为语言学习者提供了全新的视角和方法。无论是通过“微型课程”快速掌握实用短语,还是通过“俚语交流”学习更自然的表达,亦或是利用“单词相机”在实际场景中学习新单词,这些工具都旨在帮助用户更高效地学习新语言。
在科研、学习和工作中,处理复杂文档格式一直是一个让人头疼的问题。无论是科技文献中的公式、表格,还是多语言扫描版PDF,传统工具往往难以满足高效、精准的解析需求。
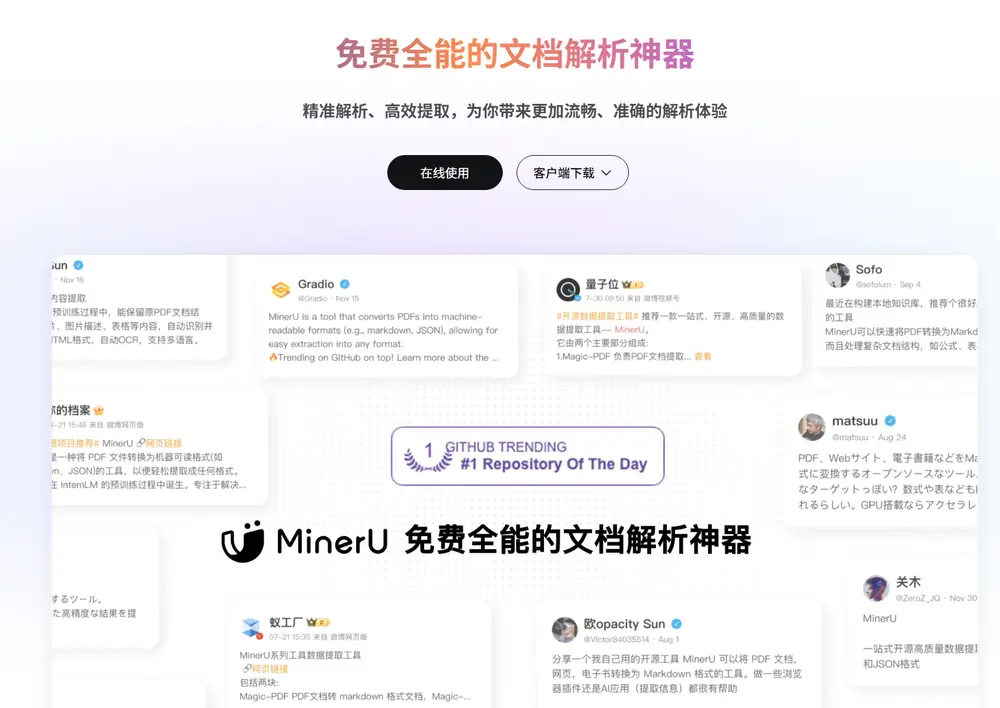
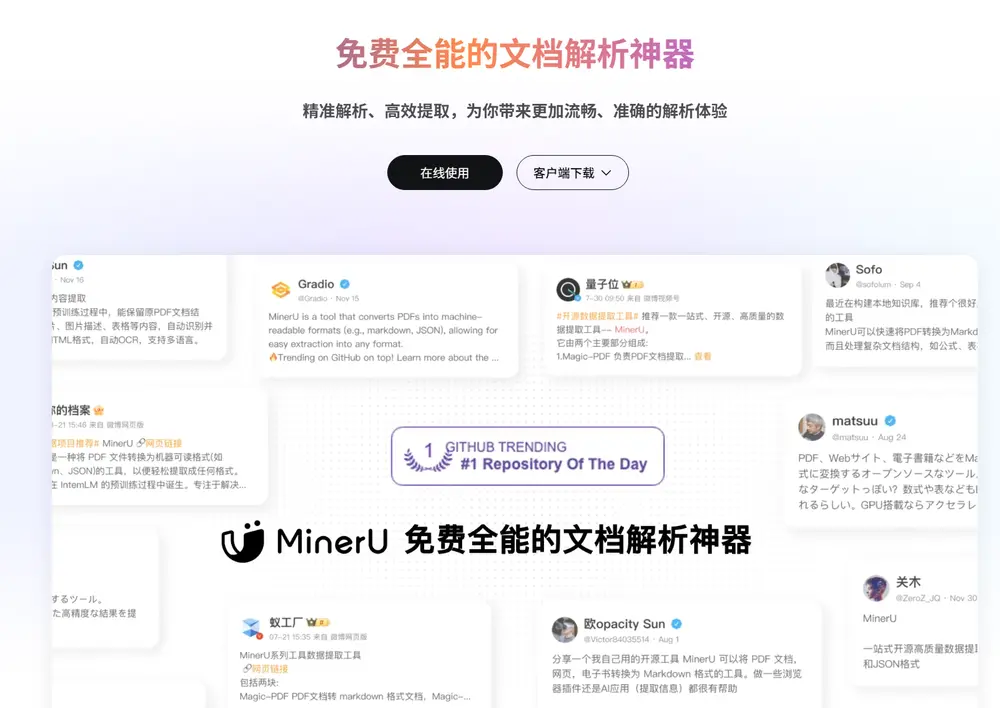
而今天要介绍的MinerU,正是一款专为解决这些问题而生的免费文档解析神器。它不仅能精准提取复杂元素,还支持多种格式一键转换,适用于从机器学习到大模型语料生产的多种场景。(相关:MinerU:一站式开源高质量数据提取工具,支持PDF/网页/多格式电子书提取)
MinerU 的一大亮点是其强大的格式兼容性。无论你的文档是 PDF、Word、PPT 还是图片,MinerU 都能轻松应对。通过简单的拖拽、截图或批量上传,你就可以快速将文件导入工具中,无需繁琐的操作。

对于科技文献、学术论文等包含复杂排版的文档,MinerU 表现尤为出色。它能够精准定位并提取图表、公式等复杂元素,确保内容完整且语义连贯。
MinerU 不仅擅长解析文档,还提供了丰富的输出格式选择,满足不同场景的需求。无论是用于机器学习训练、大模型语料生产,还是构建 RAG(检索增强生成)系统,MinerU 都能提供高效的解决方案。

MinerU 在技术层面同样表现出色,兼顾了易用性与性能优化:
MinerU 的核心功能覆盖了文档解析的方方面面,帮助用户高效完成复杂的文档处理任务:
MinerU 的设计初衷是为了服务于科研和技术发展,但它的应用范围远不止于此。以下是一些典型的应用场景:
相比其他文档解析工具,MinerU 的优势在于其全面性和精准性。它不仅能够处理各种复杂文档,还能根据用户需求输出多样化的结果。更重要的是,MinerU 完全免费,且持续优化以解决科技文献中的符号转化问题,为大模型时代的技术进步贡献力量。