
清华大学和腾讯的研究人员推出 Video-T1,在视频生成任务中引入测试时扩展(Test-Time Scaling, TTS)技术,以提升生成视频的质量和与文本提示的一致性。通过在推理阶段增加计算资源,该方法能够在不重新训练或扩大模型规模的情况下,显著提升视频生成的效果。
例如,给定一个文本提示:“一只熊猫在巴黎的咖啡馆里喝咖啡。” 使用传统的视频生成方法,生成的视频可能在动作连贯性、场景细节或与文本的对齐方面存在不足。而通过 Video-T1 的测试时扩展技术,模型可以在推理阶段通过多次采样和优化,生成更高质量、更符合文本描述的视频,例如熊猫的动作更加自然,咖啡馆的细节更加丰富,场景与文本描述更加匹配。

主要功能
Video-T1 的主要功能是通过测试时扩展技术提升视频生成的质量和与文本提示的一致性。具体功能包括:
- 提升视频质量:通过增加测试时的计算资源,生成更高质量的视频,包括更清晰的画面、更自然的动作和更丰富的细节。
- 增强文本对齐:确保生成的视频更准确地反映文本提示的内容,提高语义一致性。
- 优化计算资源:通过高效的搜索算法(如 Tree-of-Frames, ToF),在增加计算资源的同时,保持高效的推理过程。
主要特点
- 测试时扩展(Test-Time Scaling, TTS):通过在推理阶段增加计算资源,探索更优的生成路径,而无需重新训练或扩大模型规模。
- 高效的搜索算法:
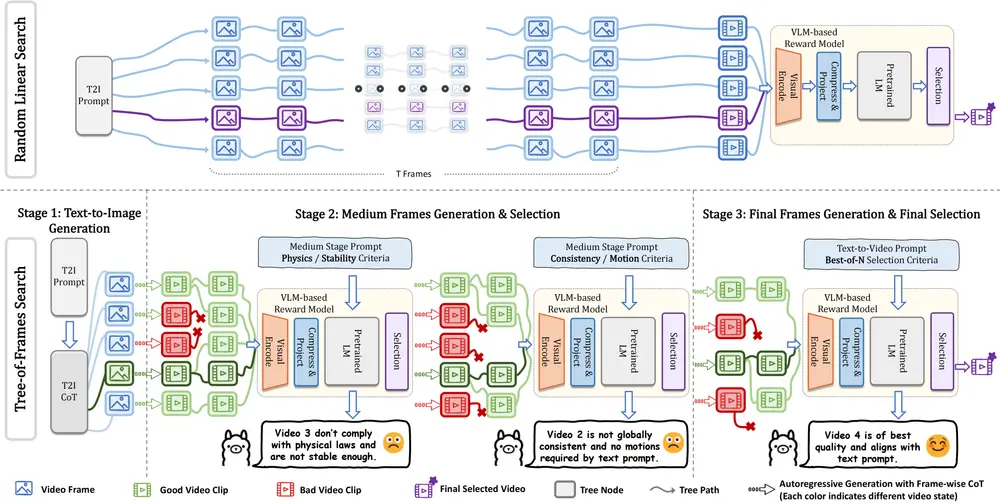
- 随机线性搜索(Random Linear Search):通过并行采样多个噪声样本,生成多个视频候选,并选择评分最高的视频。
- 帧树搜索(Tree-of-Frames, ToF):通过自回归的方式动态扩展和剪枝视频分支,平衡计算成本和生成质量。
- 多模态验证器(Multi-Verifiers):使用多个验证器评估生成视频的质量,提供更全面的反馈,进一步提升生成效果。
工作原理
Video-T1 将视频生成的测试时扩展重新定义为一个搜索问题,目标是从高斯噪声空间中找到更好的轨迹,生成更高质量的视频。具体工作原理如下:
- 测试时验证器(Test Verifiers):提供生成视频的质量反馈,评估视频与文本提示的一致性。
- 启发式搜索算法(Heuristic Search Algorithms):利用验证器的反馈,引导搜索过程,找到更优的生成路径。
- 随机线性搜索:
- 并行采样多个噪声样本,生成完整的视频序列。
- 通过验证器评估每个视频的质量,选择评分最高的视频。
- 帧树搜索(Tree-of-Frames, ToF):
- 将视频生成过程分为多个阶段,每个阶段对应视频的不同部分。
- 在每个阶段动态扩展和剪枝视频分支,通过验证器评估每个分支的质量,选择最优路径。
- 通过自回归的方式逐步生成视频,平衡计算成本和生成质量。
应用场景
- 文本到视频生成(Text-to-Video Generation):
- 应用场景:根据用户输入的文本描述生成高质量的视频,例如动画制作、广告设计、虚拟现实内容等。
- 优势:Video-T1 能够显著提升生成视频的质量和与文本描述的一致性,减少生成过程中的误差。
- 视频修复和增强:
- 应用场景:对低质量的视频进行修复和增强,例如修复老视频、增强模糊视频等。
- 优势:通过测试时扩展技术,Video-T1 能够生成更高质量的视频内容,提升视觉效果。
- 虚拟场景生成:
- 应用场景:生成虚拟场景用于游戏、电影或虚拟现实应用。
- 优势:Video-T1 能够生成更逼真的场景,同时减少生成过程中的误差,提升用户体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











