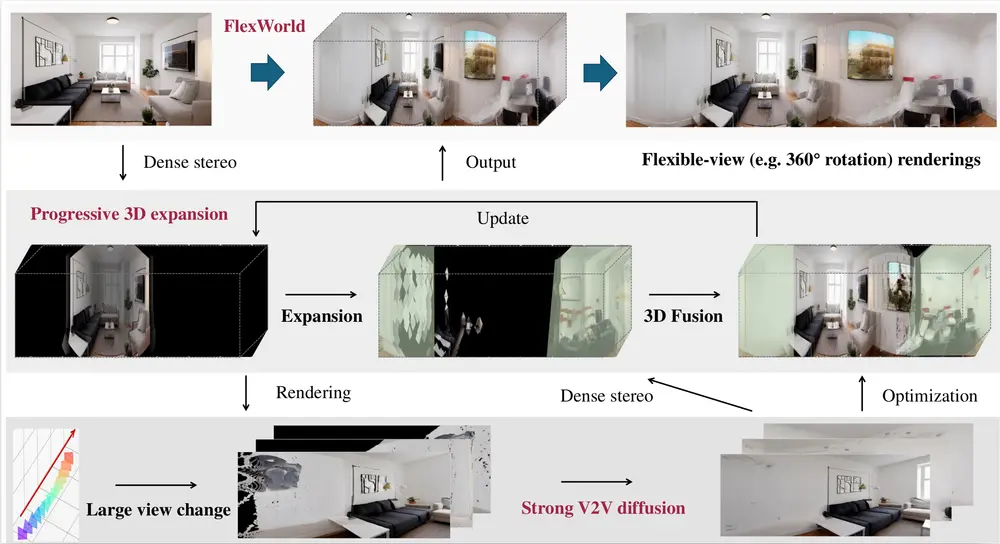
中国人民大学、北京市大数据重点实验室、清华大学、北京师范大学和字节跳动的研究人员推出一种用于从单张图像生成灵活视角 3D 场景的框架FlexWorld,从单张图像生成具有灵活视角(如 360° 旋转和缩放)的高质量 3D 场景。该框架通过结合强大的视频到视频(V2V)扩散模型和逐步扩展的 3D 场景生成过程,解决了从单张图像生成 3D 场景时视角灵活性不足的问题。
- 项目主页:https://ml-gsai.github.io/FlexWorld
- GitHub:https://github.com/ML-GSAI/FlexWorld
- 模型:https://huggingface.co/GSAI-ML/FlexWorld
例如,给定一张建筑物的单张图像,FlexWorld 可以生成该建筑物的 360° 旋转视频,用户可以自由地从不同角度和距离观察建筑物。这一任务在考古保护和自动驾驶等领域具有重要意义,因为直接获取 3D 数据往往成本高昂或不切实际。

主要功能
- 高质量新视角视频生成:通过 V2V 扩散模型,从粗略场景渲染的不完整输入中生成高质量的新视角视频。
- 逐步扩展 3D 场景:通过几何感知的场景融合,将新生成的 3D 内容逐步整合到全局场景中,最终生成详细的 3D 场景。
- 灵活视角合成:支持 360° 旋转、缩放等灵活视角操作,生成高保真度的 3D 场景。
主要特点
- 强大的 V2V 扩散模型:基于先进的预训练视频模型,能够在大范围相机姿态变化下生成高质量内容。
- 几何感知场景融合:通过精确的深度估计和优化,确保新生成的 3D 内容与现有场景的一致性。
- 逐步场景扩展:通过规划相机轨迹、场景整合和优化,逐步构建完整的 3D 场景。
- 高质量视觉效果:在多个基准数据集上,FlexWorld 在视觉质量和视角灵活性方面优于现有方法。
工作原理
- V2V 扩散模型:
- 视频条件化:使用 3D-VAE 编码器将条件视频压缩到潜在空间,然后与噪声潜在向量拼接,训练模型以生成高质量视频。
- 训练数据构建:通过 3DGS 重建生成更精确的深度估计,确保生成的训练对与真实数据对齐。
- 逐步 3D 场景扩展:
- 相机轨迹规划:从初始粗略场景开始,通过缩放和旋转相机逐步扩展场景。
- 场景整合:从生成的视频中提取 3D 内容,并将其整合到全局场景中。
- 优化过程:通过多视角图像渲染和优化,进一步提升生成场景的视觉质量。
应用场景
- 虚拟现实内容创作:FlexWorld 可以从单张图像生成高质量的 360° 旋转和缩放视频,为虚拟现实应用提供丰富的视觉体验。
- 3D 旅游:用户可以通过 FlexWorld 生成的 3D 场景,从不同角度和距离探索旅游景点。
- 考古保护:在考古遗址的数字化保护中,FlexWorld 可以从有限的图像数据生成完整的 3D 场景,帮助研究人员更好地理解和展示遗址。
- 自动驾驶:FlexWorld 可以生成复杂的 3D 场景,用于自动驾驶系统的训练和测试,提升其在不同视角下的感知能力。
总结
FlexWorld 通过结合强大的 V2V 扩散模型和逐步扩展的 3D 场景生成过程,显著提升了从单张图像生成灵活视角 3D 场景的能力。该框架在多个基准数据集上表现出色,生成的 3D 场景具有高保真度和视角灵活性。FlexWorld 在虚拟现实内容创作、3D 旅游和考古保护等领域具有广阔的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











