随着计算机图形学和人工智能的发展,生成高质量的人类动画变得越来越重要。特别是,当涉及到创建生动、自然的动画时,音频、姿势或运动图等条件的引入大大提升了动画的真实性和表现力。然而,这些增强的方法也带来了额外的复杂性:
控制条件:需要额外的数据(如音频、运动捕捉数据)来驱动动画。 条件注入模块:通常需要复杂的架构来处理这些额外的条件,增加了模型训练和推理的难度。 区域局限性:很多方法局限于头部区域的动画,未能充分利用全身动作来丰富表达。
EchoMimicV2 的提出
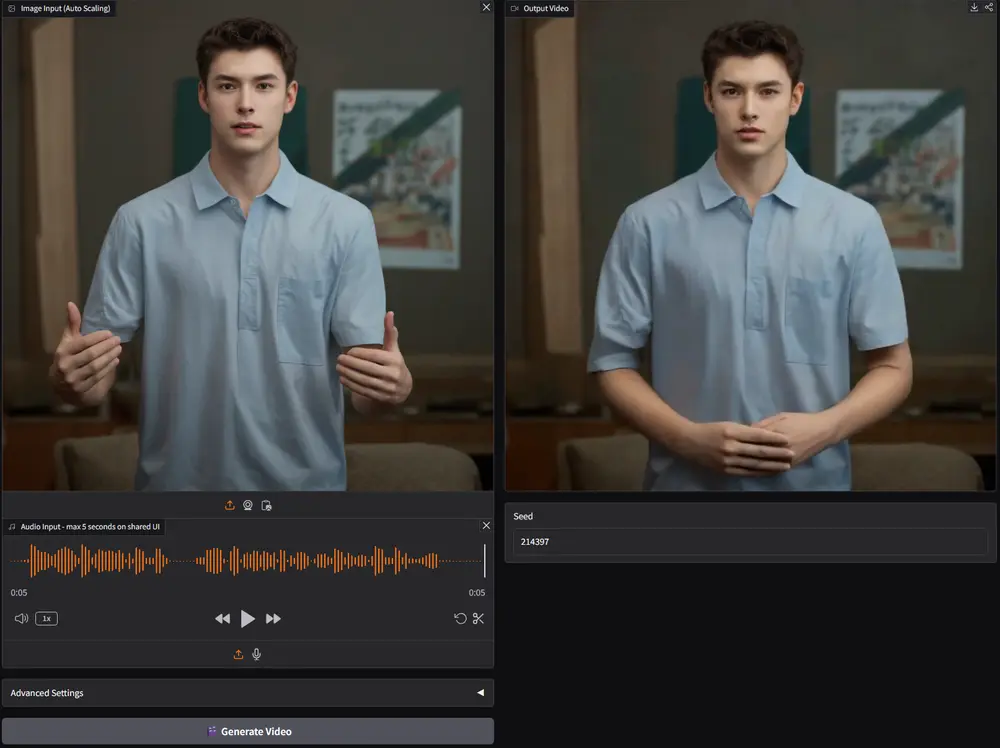
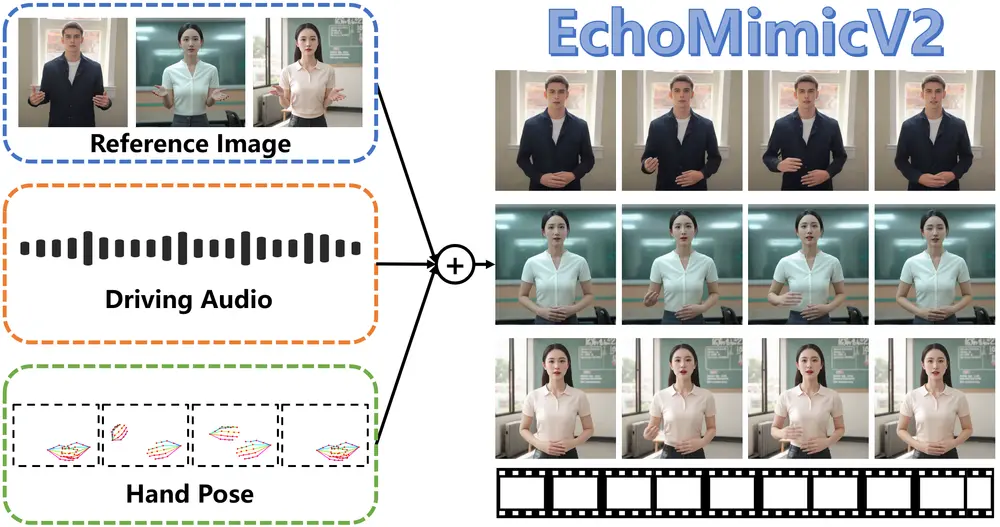
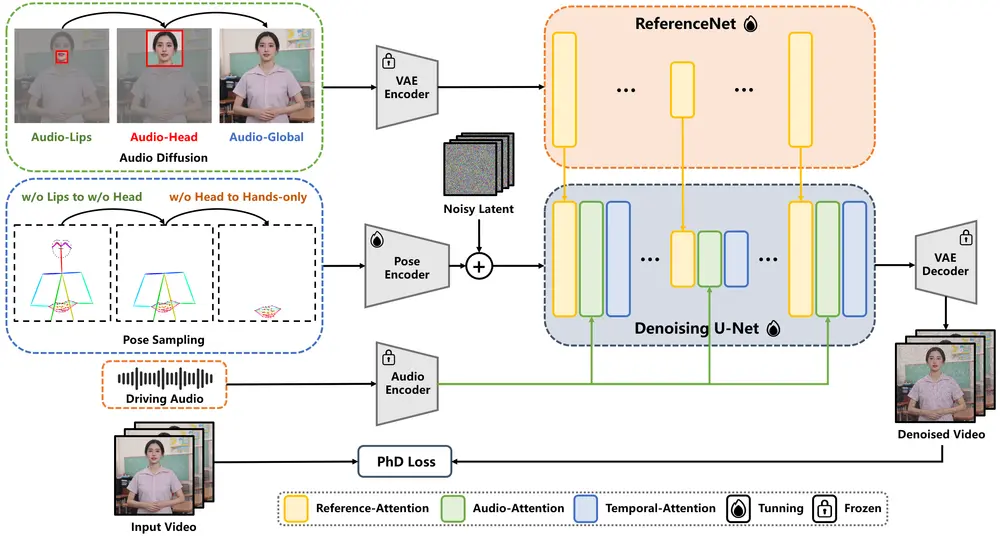
为了应对上述挑战,蚂蚁集团支付宝终端技术部在之前EchoMimic的基础上推出了 EchoMimicV2,这是一种半身人体动画生成框架,它能够利用参考图像、音频剪辑和一系列手部姿势来生成高质量的动画视频,确保音频内容与半身动作之间的连贯性。这个框架旨在简化人体动画生成过程中的不必要条件,同时提高动画的生动性和真实感。
- 项目主页:https://antgroup.github.io/ai/echomimic_v2
- GitHub:https://github.com/antgroup/echomimic_v2
- 模型:https://huggingface.co/BadToBest/EchoMimicV2 & https://modelscope.cn/models/BadToBest/EchoMimicV2
- ComfyUI插件:https://github.com/smthemex/ComfyUI_EchoMimic
- Demo:https://huggingface.co/spaces/fffiloni/echomimic-v2
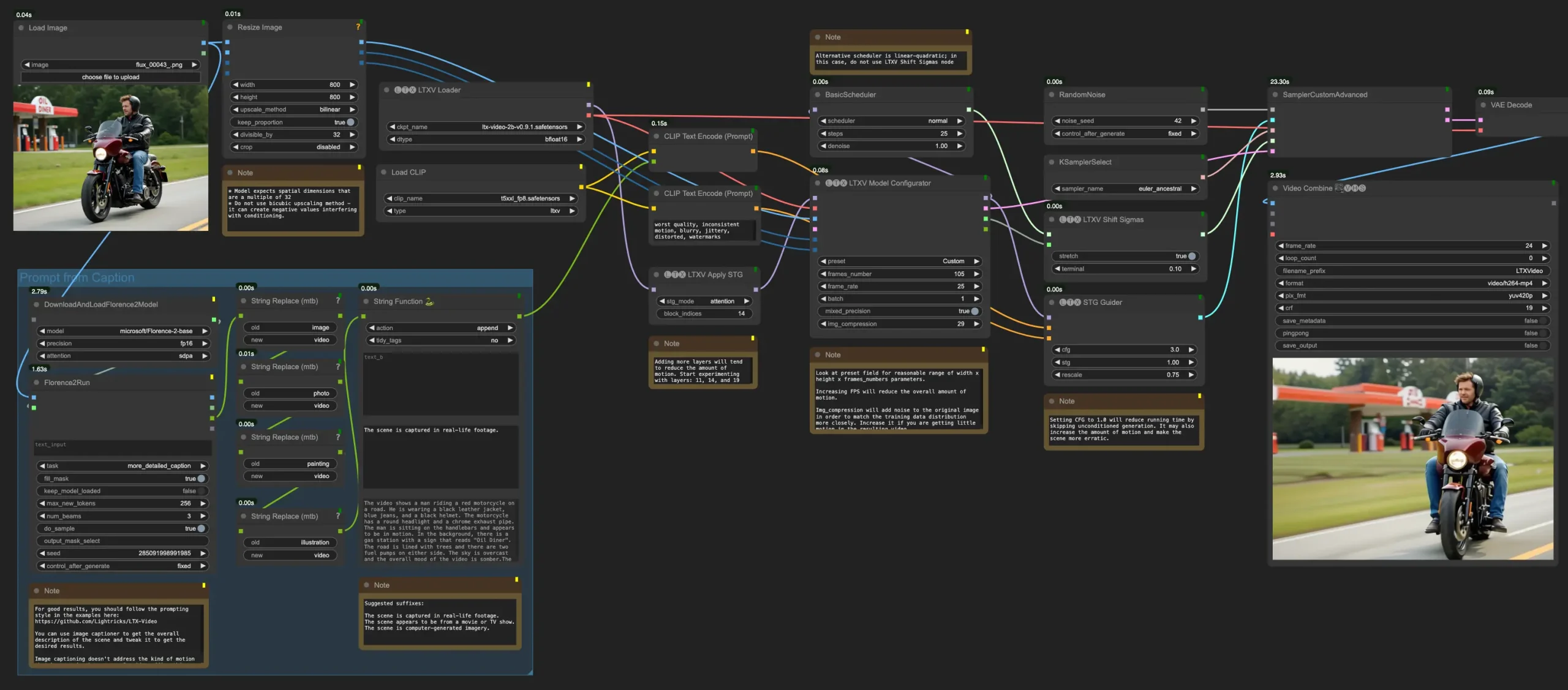
例如,假设我们有一张人物的正面照片、一段该人物的演讲音频以及一些手部姿势的数据。EchoMimicV2可以利用这些输入生成一个动画视频,视频中的人物会根据音频内容进行自然的头部和身体动作,同时手部姿势也会与音频中的情感和节奏相匹配。
它包括以下关键技术:
姿势采样:通过智能采样机制选择最能代表目标动作的关键姿势,从而减少对大量条件数据的依赖。 音频扩散:利用音频信号的特性,以更自然的方式影响动画中的人物表情和手势,而不需要逐帧指定详细的动作指令。 头部部分注意力:考虑到半身动画数据的稀缺性,EchoMimicV2 采用了一种特别设计的注意力机制,可以有效地将丰富的头部动画数据融入到训练过程中。
主要特点
简化条件:EchoMimicV2通过减少控制条件和简化条件注入模块,降低了生成动画的复杂性。 音频-姿势动态协调(APDH):通过姿势采样和音频扩散,EchoMimicV2能够增强半身细节、面部和手势的表现力。 头部部分注意力(HPA):为了补偿半身数据的不足,EchoMimicV2利用头部部分注意力无缝地将头像数据融入训练框架中。 阶段性去噪损失(PhD Loss):通过设计特定阶段的去噪损失,EchoMimicV2能够分别指导动画的运动、细节和低级质量。 新的基准测试:为了评估半身人体动画的有效性,EchoMimicV2提供了一个新的基准测试集。
特定阶段的去噪损失
EchoMimicV2的主要功能是生成与音频同步的半身人物动画。它能够处理音频、姿势和视觉输入,生成连贯、逼真的动画输出。为了进一步提高动画的质量,EchoMimicV2 设计了特定阶段的去噪损失函数。这些损失函数分别针对动画的不同方面进行优化,确保在每个阶段都能得到最佳的结果:
动作指导:专注于整体动作的流畅性和自然度。 细节指导:提升局部细节的表现力,如面部表情和手势。 低级质量指导:改善图像的基本质量,如清晰度和平滑度。
新基准与评估
为了客观地评估 EchoMimicV2 的性能,研究团队还提出了一套新的基准测试。这套基准不仅涵盖了定量指标(如 PSNR、SSIM 等),还包括了定性评估,如视觉效果和用户感知调查。广泛的实验和分析表明,EchoMimicV2 在多个方面均优于现有的方法,特别是在以下几个关键点上:
简化条件:减少了对额外条件数据的依赖,使模型更加通用和易于使用。 提高表现力:增强了半身动画的细节和表现力,尤其是面部和手势的自然度。 高效训练:通过巧妙的设计,即使在有限的数据集上也能获得良好的泛化能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











