
香港大学与华为诺亚方舟实验室携手,正式发布了迄今为止最强大的开放扩散(Diffusion)大语言模型——Dream 7B。这一模型不仅在性能上大幅超越现有的扩散语言模型,还在通用能力、数学能力和编码能力上与同等规模的顶级自回归语言模型相媲美,甚至在某些方面实现了超越。Dream 7B的出现,为语言模型的发展带来了新的可能性,也为未来的AI应用奠定了坚实的基础。
- 项目主页:https://hkunlp.github.io/blog/2025/dream
- GitHub:https://github.com/HKUNLP/Dream
- Base model: Dream-org/Dream-v0-Base-7B
- SFT model: Dream-org/Dream-v0-Instruct-7B
- Demo:https://huggingface.co/spaces/multimodalart/Dream
为什么选择扩散模型进行文本生成?
大语言模型(LLMs)的快速发展已经深刻改变了AI领域,推动了众多行业的变革。目前,自回归(AR)模型在文本生成领域占据主导地位,几乎所有领先的LLMs(如GPT-4、DeepSeek、Claude等)都依赖于这种从左到右的顺序架构。然而,随着AR模型在大规模应用中暴露出一些局限性,如复杂推理、长期规划以及在扩展上下文中保持连贯性的挑战,人们开始思考下一代LLMs的架构范式。

离散扩散模型(DMs)作为序列生成的替代方案,自引入文本领域以来便备受关注。与AR模型按顺序生成token不同,离散DMs从完全噪声状态开始,动态优化整个序列。这种架构差异带来了显著优势,包括双向上下文建模、灵活的可控生成能力以及基础采样加速的潜力。最近,扩散模型在语言任务中的显著进步进一步凸显了其潜力,使其成为克服自回归方法局限性的有前景的方向。
Dream 7B的训练与创新
Dream 7B的开发建立在团队在扩散语言模型领域的先前工作基础之上,借鉴了RDM的理论基础和DiffuLLaMA的适应策略。训练数据涵盖文本、数学和代码,主要来源于Dolma v1.7、OpenCoder和DCLM-Baseline,经过多个预处理和筛选流程。在精心设计的训练过程中,Dream 7B使用混合数据进行了预训练,总计处理了5800亿token,预训练在96个英伟达 H800 GPU上进行了256小时。整个预训练过程总体顺利,尽管偶尔出现节点异常,但未遇到不可恢复的损失峰值。
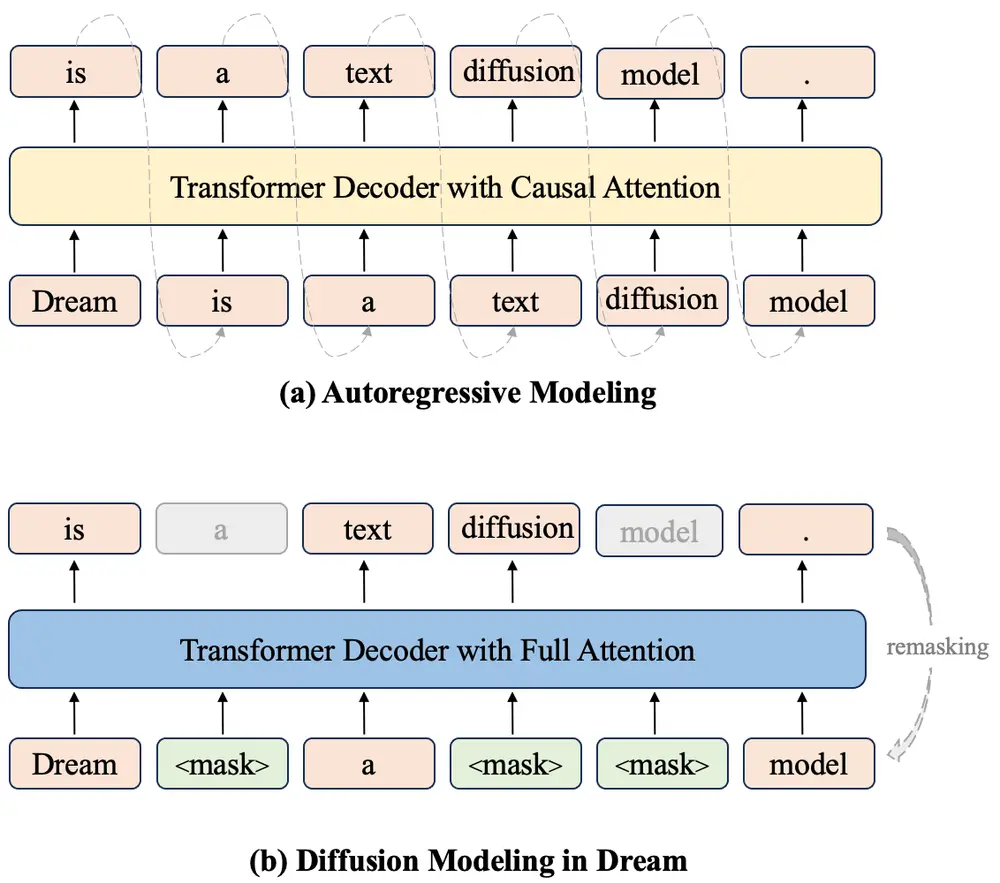
在训练过程中,团队在10亿参数级别上广泛研究了设计选择,并确定了许多有价值的组件。例如,从AR模型(如Qwen2.5和LLaMA3)中初始化权重,以及上下文自适应的token级噪声重新调度,这些都使得Dream 7B的有效训练成为可能。
AR初始化
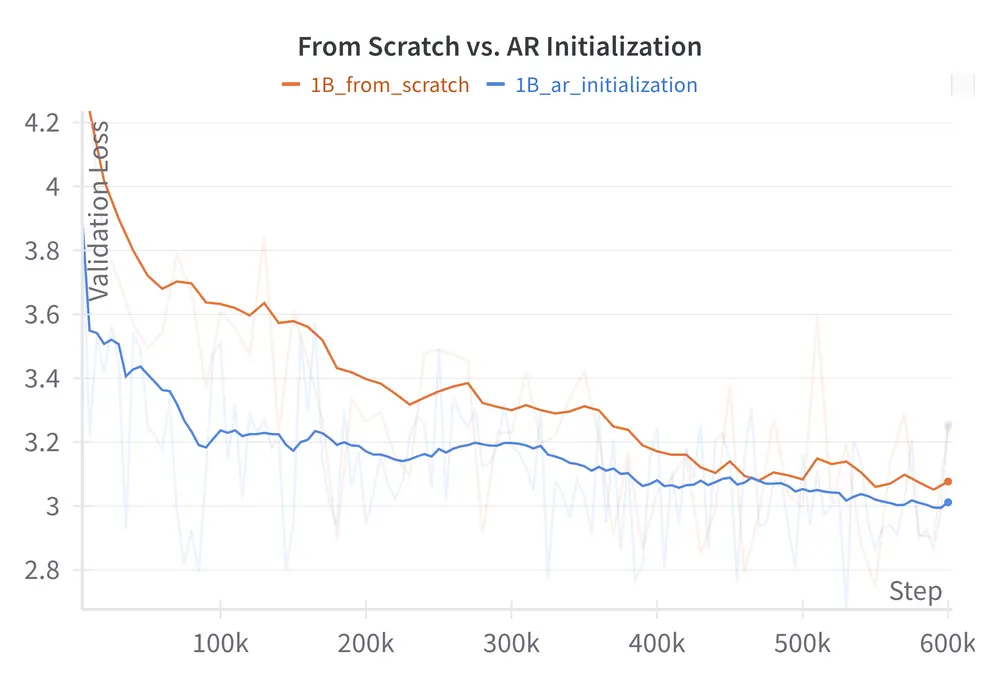
在先前的工作DiffuLLaMA中,团队发现使用现有AR模型的权重作为扩散语言模型的非平凡初始化是有效的。这种设计比从头训练扩散语言模型更有效,尤其是在训练早期阶段。Dream 7B最终使用Qwen2.5 7B的权重进行初始化。在训练过程中,学习率的设置尤为重要。如果设置过高,会迅速洗掉初始权重中的从左到右知识,对扩散训练帮助甚微;而如果设置过低,则会阻碍扩散训练。团队精心挑选了这一参数,得益于AR模型中现有的从左到右知识,扩散模型的任意顺序学习得以加速,显著减少了预训练所需的token和计算量。
上下文自适应Token级噪声重新调度
在传统的离散扩散训练中,会采样一个时间步t来确定句子级别的噪声水平,然后模型执行去噪。然而,由于学习最终是在token级别上进行的,每个token的实际噪声水平并不严格与t对齐,导致对具有不同上下文信息的token学习效果不佳。为解决这一问题,团队引入了上下文自适应token级噪声重新调度机制,该机制根据注入噪声后的损坏上下文动态重新分配每个token的噪声水平,为单个token的学习过程提供了更细粒度和精确的指导。
Dream 7B的规划能力与推理灵活性
规划能力
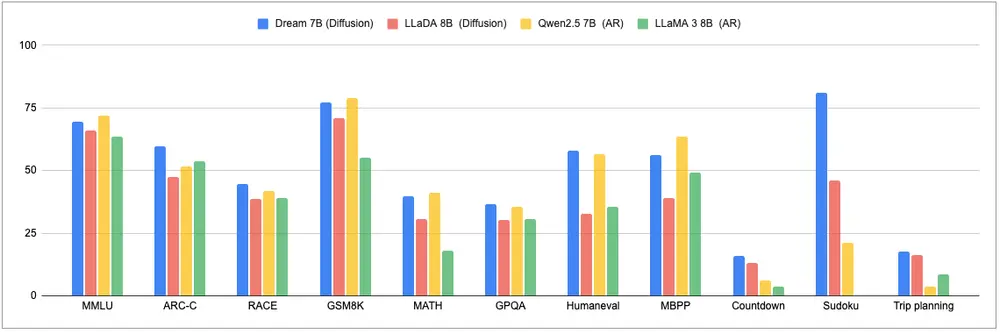
在之前的研究中,团队展示了文本扩散在小规模、任务特定的上下文中具有优越的规划能力。然而,一个通用的、扩展的扩散模型是否具备类似能力仍不确定。现在,通过Dream 7B,团队能够更好地回答这一问题。在Countdown和Sudoku任务上,Dream 7B与其他同等规模的基线模型(如LLaDA 8B、Qwen2.5 7B和LLaMA3 8B)以及最新的Deepseek V3 671B (0324)进行了比较,所有模型均在少样本设置下评估,未针对这些任务进行训练。结果显示,Dream 7B优于其他同等规模的基线模型,扩散模型在解决多约束问题或实现特定目标时更有效。
推理灵活性
扩散模型在推理灵活性方面提供了比AR模型更多的可能性。首先,扩散模型不受限于顺序(例如从左到右)生成,允许以任意顺序合成输出,为更多样化的用户查询提供了可能。其次,扩散模型还支持补全和填充功能,可以根据不同的查询调整解码行为,使其从更像AR模型的从左到右生成转变为更随机的顺序生成。此外,扩散模型还提供了质量与速度之间的可调权衡:更少的步骤产生更快但较粗糙的结果,而更多的步骤以更高的计算成本产生更高质量的输出。这种可调整的计算-质量权衡是传统AR框架所不具备的独特优势。
监督微调与未来展望
作为后训练扩散语言模型的初步步骤,团队对Dream 7B进行了监督微调,以使其与用户指令对齐。具体来说,团队从Tulu 3和SmolLM2中整理了一个包含180万对的数据集,对Dream 7B进行了三轮微调。微调结果显示,Dream 7B在性能上与自回归模型相当,展现出巨大的潜力。展望未来,团队计划探索更高级的扩散语言模型后训练方法,进一步提升模型的性能和应用价值。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











