阿里云的Qwen团队最近宣布了一项重要进展,他们通过整合大规模强化学习(RL)技术来提升大语言模型的智能水平,并推出了新的推理模型QwQ-32B。这款拥有320亿参数的模型,在性能上能够与具有6710亿参数(其中激活了370亿)的DeepSeek-R1相媲美。
- Hugging Face:https://huggingface.co/Qwen/QwQ-32B
- ModelScope :https://modelscope.cn/models/Qwen/QwQ-32B
- Qwen Chat :https://chat.qwen.ai/?models=Qwen2.5-Plus
- Ollama:https://ollama.com/library/qwq(4090可本地运行)

强化学习对大语言模型的影响
Qwen团队的研究表明,通过将强化学习应用于已经过大规模预训练的强大基础模型,可以显著提高其推理能力。特别是,QwQ-32B不仅在数学推理和编程能力方面表现出色,还集成了Agent相关的功能,使模型能够在使用工具的同时进行批判性思考,并根据环境反馈调整推理过程。
QwQ-32B的关键特性
- 参数规模:320亿参数
- 性能对比:可与DeepSeek-R1等更大型号相媲美
- 开源平台:已在Hugging Face和ModelScope上开源,采用Apache 2.0协议
- 直接体验:可通过Qwen Chat直接试用
强化学习的应用细节
Qwen团队在其研究中采用了分阶段的方法来进行强化学习:
- 初始阶段:专注于数学和编程任务的RL训练。不同于传统的奖励模型,他们直接验证生成答案的正确性,对于数学问题则检查解题步骤是否准确;对于编程任务,则通过代码执行服务器评估代码能否成功运行并通过测试用例。
- 后续阶段:增加了针对通用能力的RL训练,利用通用奖励模型及基于规则的验证器进行优化。结果显示,经过少量步骤的通用RL训练后,模型的通用能力得到了提升,同时保持了在数学和编程领域的高水平表现。

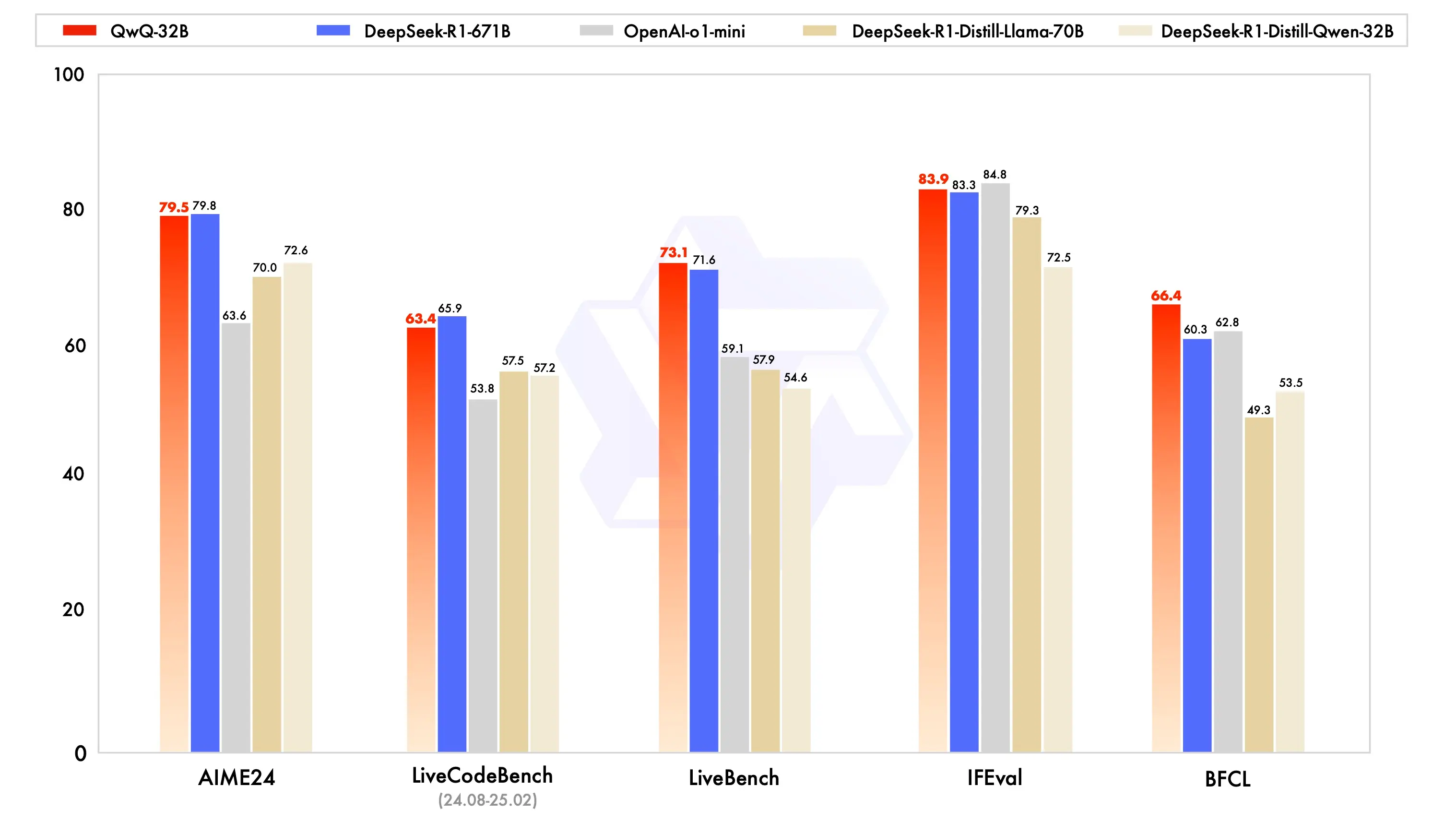
性能评估
QwQ-32B已经在多个基准测试中进行了评估,包括但不限于数学推理、编程能力和通用能力。结果表明,QwQ-32B在这些领域内的表现优于或至少持平于其他领先的模型,如DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini以及原始的DeepSeek-R1。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











