
Nari Labs在今天开源了一个拥有16亿参数的文本转语音模型Dia-1.6B。这个模型的最大亮点在于它能够生成高度逼真的对话,并且加入了自然人声元素,比如笑声、咳嗽、清喉咙等,让语音合成更加生动自然。目前,这个模型还没有量化版本,运行时大概需要10G显存。不过,目前该模型仅支持英语生成。
- GitHub:https://github.com/nari-labs/dia
- 模型:https://huggingface.co/nari-labs/Dia-1.6B
- Demo:https://huggingface.co/spaces/nari-labs/Dia-1.6B
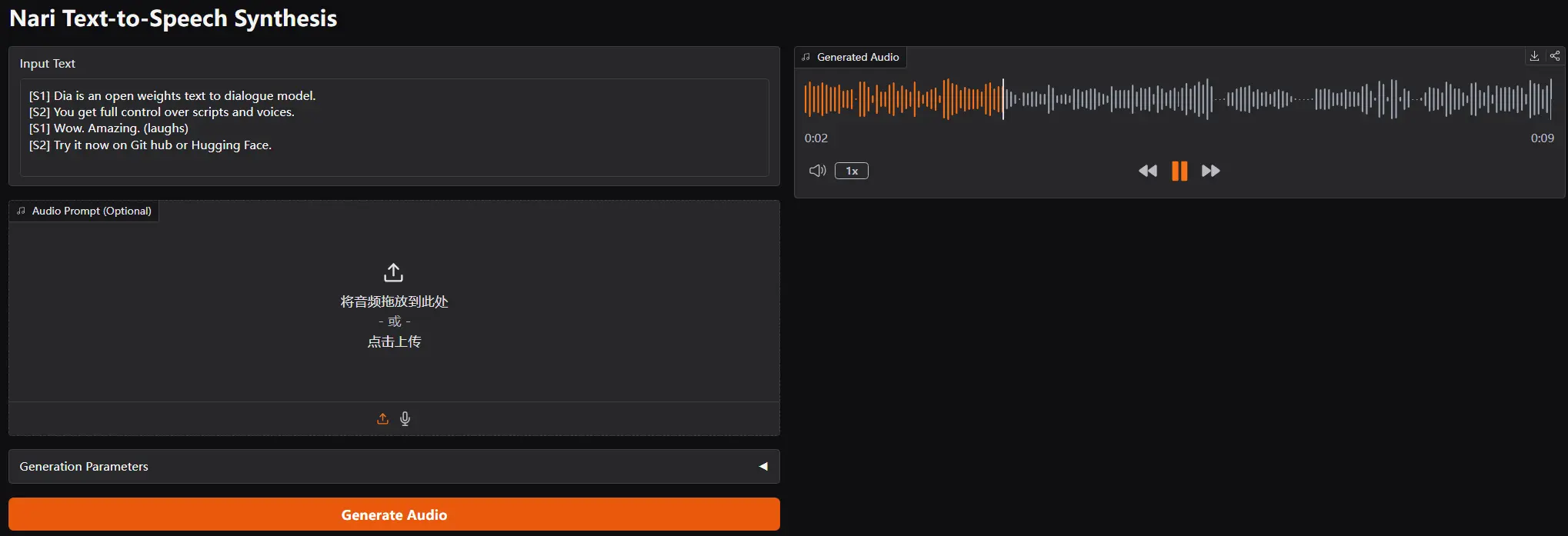
特性亮点
- 生成对话:通过[S1]和[S2]标签,Dia可以生成流畅的对话,模拟真实的人际交流场景。
- 非语言表达:模型能够生成如(laughs)、(coughs)等非语言表达,让语音合成更加贴近真实的人类交流。
- 声音克隆:用户可以上传想要克隆的音频,并将其文本稿放在脚本之前。模型会根据这些信息生成与原音频相似的语音,实现声音克隆的效果。详情请参考example/voice_clone.py。
硬件与性能
Dia-1.6B 目前仅支持 GPU 推理,建议使用 PyTorch 2.0+ 和 CUDA 12.6 环境。以下是关于硬件和性能的一些关键信息:
- 显存需求 :完整版本的 Dia 需要大约 10GB 显存 。
- 推理速度 :在高性能 GPU(如 A4000)上,模型可以实时生成音频,速度约为 40 tokens/秒 (86 tokens 约等于 1 秒音频)。对于较旧的 GPU,推理时间会相应变慢。
- 首次运行 :首次运行时需要下载 Descript Audio Codec,因此耗时较长。
- 未来优化 :开发团队计划添加量化版本以降低显存需求,并优化推理速度。
如果您没有合适的硬件,或者想体验更大版本的模型,可以通过官方提供的链接加入候补名单。
许可与责任
本项目基于Apache License 2.0许可,具体详情请参考LICENSE文件。
免责声明:本项目提供了一个高保真语音生成模型,旨在用于研究和教育目的。请严格遵守以下规定:
- 身份滥用:未经许可,不得生成模仿真实个人的音频。
- 欺骗性内容:不得使用此模型生成误导性内容(如假新闻)。
- 非法或恶意使用:不得将此模型用于非法或意图造成伤害的活动。
使用该模型即表示你同意遵守相关法律和道德责任。开发团队不承担任何滥用行为的责任,并坚决反对任何不道德地使用该技术的行为。
未来展望
- Docker支持:正在开发中,将为用户提供更便捷的部署体验。
- 优化推理速度:持续改进中,以适应更多硬件环境。
- 量化版本:计划推出,以提高内存效率,降低硬件要求。
Nari Labs开源的Dia-1.6B模型为文本到语音技术带来了新的突破,让语音合成更加自然、生动。随着未来版本的不断优化,它有望在更多领域发挥更大的作用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











