智谱AI全新发布 GLM-ASR 系列语音识别模型,包含云端部署的 GLM-ASR-2512 与端侧轻量化的 GLM-ASR-Nano-2512 两个版本。其中 Nano 版以 1.5B 紧凑参数规模实现免费开源,支持笔记本、手机等终端设备本地运行,在方言识别、低音量语音转录等场景达到同类开源模型 SOTA 性能,同时超越 OpenAI Whisper V3。
- 文档:https://docs.bigmodel.cn/cn/guide/models/sound-and-video/glm-asr-2512
- Hugging Face:https://huggingface.co/zai-org/GLM-ASR-Nano-2512
- 魔塔:https://www.modelscope.cn/models/ZhipuAI/GLM-ASR-Nano-2512
双版本定位:云端精准识别,端侧低延迟部署
GLM-ASR 系列针对不同使用场景,提供差异化模型选择:
- GLM-ASR-2512(云端版)
- 定位:面向云端大规模语音识别需求,适配复杂声学环境;
- 核心指标:字符错误率低至 0.0717;
- 支持场景:中文、英文、方言转录,以及嘈杂环境下的语音识别,满足企业级高精准度需求。
- GLM-ASR-Nano-2512(端侧开源版)
- 核心参数:1.5B 参数规模,体积轻量化,可直接在笔记本、手机等终端设备本地运行;
- 开源属性:免费开源,支持开发者二次优化与定制;
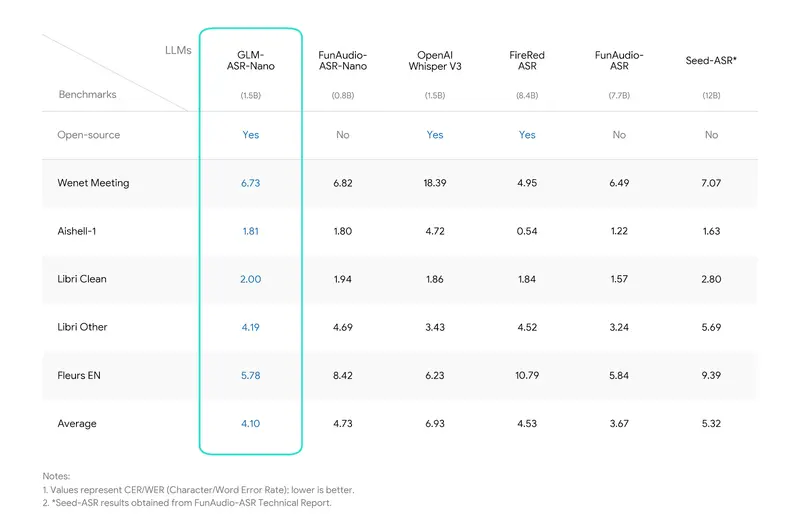
- 性能优势:在同类开源模型中实现最低平均错误率(4.10),在 Wenet Meeting、Aishell-1 等中文权威基准测试中表现突出,综合性能优于 OpenAI Whisper V3。
核心功能亮点:覆盖多场景语音识别痛点
GLM-ASR-Nano-2512 针对现实世界语音识别的复杂需求做深度优化,解决传统模型的多个短板:
- 卓越的方言支持能力
除标准普通话和英语外,模型针对粤语等方言进行专项优化,有效填补方言语音识别的技术空白,适用于地方特色内容转录、方言交互等场景。 - 低音量语音鲁棒性
专门针对耳语、轻声场景开展训练,能够精准捕捉传统语音识别模型容易遗漏的极低音量音频,可满足会议低声讨论、夜间语音输入等隐私性强的使用需求。 - 复杂声学环境适应性
在嘈杂环境下仍保持高识别准确率,无需额外降噪预处理即可直接转录,适配车载、商场、工厂等多背景噪音场景。
基准测试表现:同类模型中优势显著
在多轮权威基准测试中,GLM-ASR-Nano-2512 展现出远超同级别模型的性能:
- 对比 OpenAI Whisper V3:在相同参数量级下,GLM-ASR-Nano-2512 平均错误率更低,尤其在方言和低音量场景优势明显;
- 中文场景专项测试:在 Wenet Meeting(会议语音)、Aishell-1(中文普通话)等数据集测试中,识别准确率领先其他开源语音识别模型,达到 SOTA 水平。
部署与使用价值
- 端侧部署便捷性:GLM-ASR-Nano-2512 支持笔记本、手机等设备本地运行,无需依赖云端网络,实现低延迟语音转录,保护用户数据隐私;
- 开源生态赋能:模型免费开源,开发者可基于现有框架优化适配更多方言、特殊场景,拓展语音识别应用边界;
- 多场景落地潜力:可广泛应用于方言内容创作、离线语音助手、会议实时转录、低音量语音交互等场景,兼顾个人与企业级需求。
GLM-ASR 系列的推出,既为云端提供了高精准度的语音识别方案,又通过端侧开源模型降低了语音技术的使用门槛,为中文语音识别的本地化、个性化发展提供了新的技术底座。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...