
阶跃星辰团队开源了面向智能语音交互的框架 Step-Audio,旨在解决当前开源语音模型在数据收集成本高、动态控制能力弱和智能水平有限等问题。Step-Audio 提出了一个 1300 亿参数的统一语音-文本多模态模型,能够实现语音理解与生成的统一,并通过多种创新技术提升语音交互的性能和灵活性。该框架在新的 StepEval-Audio-360 评估基准上表现出色,尤其是在指令跟随方面,展示了其在开源多模态语言技术发展中的领先地位。
- GitHub:https://github.com/stepfun-ai/Step-Audio
- 模型:https://huggingface.co/collections/stepfun-ai/step-audio-67b33accf45735bb21131b0b
用户可以通过语音指令与 Step-Audio 交互,例如“用粤语播放天气预报”或“用愤怒的语气唱一首歌”。Step-Audio 能够理解这些指令,并生成符合要求的语音输出,同时支持多种语言、方言和情感风格。大家可以在阶跃星辰旗下的跃问APP进行体验。

Step-Audio:业界首个语音理解与生成一体化的开源实时语音对话系统
功能亮点
- 多语言对话:支持中文、英文、日语等。
- 语音情感:支持开心、悲伤等多种情感表达。
- 方言支持:支持粤语、四川话等方言。
- 语速及韵律风格控制:可调节语速和韵律风格。
- 支持 RAP 和哼唱:支持多种音乐风格。
- 语音克隆:实现个性化的语音生成。
核心技术突破
- 1300 亿参数多模态模型:单模型实现语音识别、语义理解、对话、语音克隆、语音生成等功能,开源千亿参数多模态模型 Step-Audio-Chat。
- 高效数据生成链路:突破传统 TTS 对人工采集数据的依赖,生成高质量合成音频数据,开源支持 RAP 和哼唱的指令加强版语音合成模型 Step-Audio-TTS-3B。
- 精细语音控制:支持多种情绪、方言和唱歌风格的精准调控,满足多样化语音生成需求。
- 扩展工具调用:通过 ToolCall 机制和角色扮演增强,提升在复杂任务中的表现。
模型组成
在Step-Audio系统中,音频流采用Linguistic tokenizer(码率16.7Hz,码本大小1024)与Semantice tokenizer(码率25Hz,码本大小4096)并行的双码本编码器方案,双码本在排列上使用了2:3时序交错策略。通过音频语境化持续预训练和任务定向微调强化了130B参数量的基础模型(Step-1),最终构建了强大的跨模态语音理解能力。为了实现实时音频生成,系统采用了混合语音解码器,结合流匹配(flow matching)与神经声码技术。
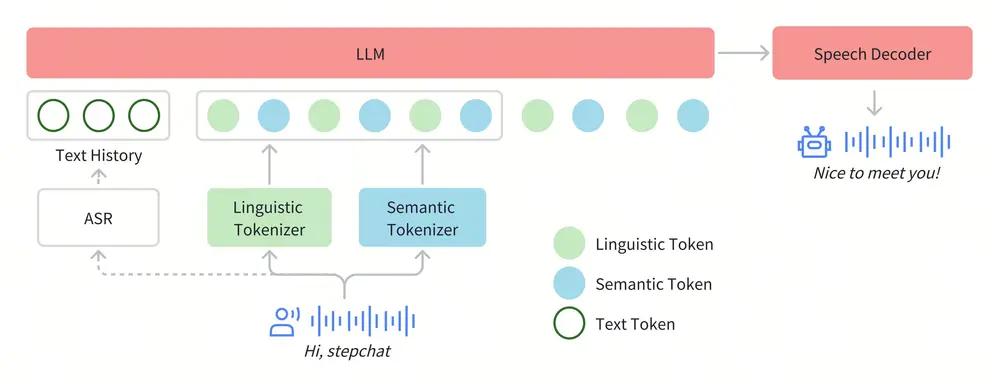
1. Tokenizer
Step-Audio 采用 Linguistic tokenizer(码率 16.7Hz,码本大小 1024)与 Semantic tokenizer(码率 25Hz,码本大小 4096)的双码本编码器方案。两者通过 2:3 的时序交错策略进行排列,实现 Linguistic token 与 Semantic token 的有效整合。
2. 语言模型
基于 1300 亿参数的文本大型语言模型 Step-1,通过音频持续预训练,强化跨模态语音理解能力。
3. 语音解码器
语音解码器将离散标记信息转换为连续语音信号,结合 30 亿参数的语言模型、流匹配模型和梅尔频谱到波形的声码器。采用双码交错训练方法,优化合成语音的清晰度和自然度。
4. 实时推理管线
推理管线包含语音活动检测(VAD)、流式音频分词器、Step-Audio 语言模型与语音解码器、上下文管理器等模块,确保实时语音交互的流畅性。
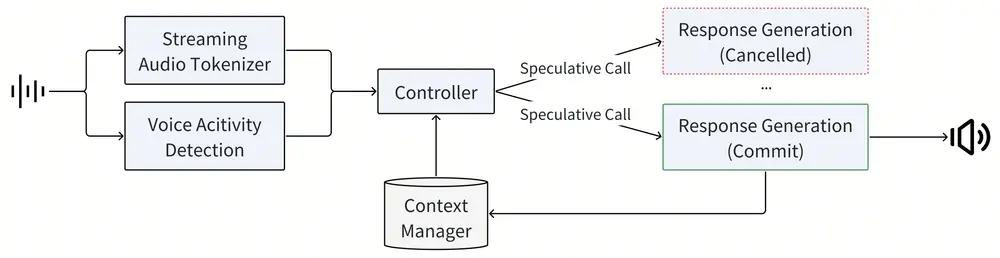
5. 后训练细节
针对 ASR 和 TTS 任务进行专项监督微调(SFT),并采用基于人类反馈的强化学习(RLHF),提升情感表达、语速、方言及韵律的细粒度控制。

模型使用
硬件要求
运行 Step-Audio 模型需要支持 CUDA 的英伟达显卡。建议使用 4 块 80GB 显存的 A800/H800 系列显卡,以确保最佳生成质量。测试操作系统为 Linux。
模型下载
模型可通过以下链接获取:
Huggingface
| 模型 | 链接 |
|---|---|
| Step-Audio-Tokenizer | huggingface |
| Step-Audio-Chat | huggingface |
| Step-Audio-TTS-3B | huggingface |
Modelscope
| 模型 | 链接 |
|---|---|
| Step-Audio-Tokenizer | modelscope |
| Step-Audio-Chat | modelscope |
| Step-Audio-TTS-3B | modelscope |
基准测试
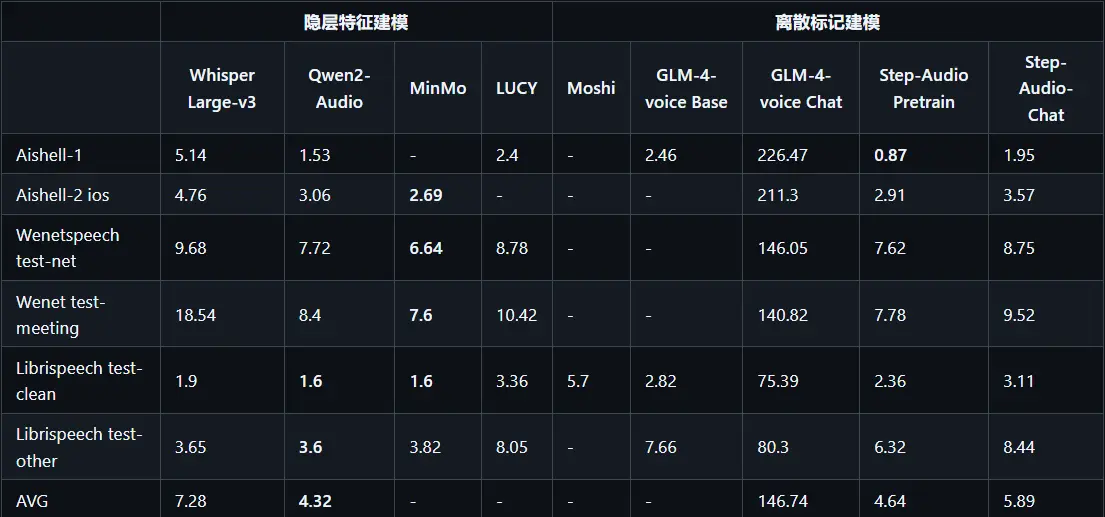
1. 语音识别
Step-Audio 在多个数据集上表现出色,例如在 Aishell-1 数据集上,其 WER 低至 1.95%,显著优于其他模型。
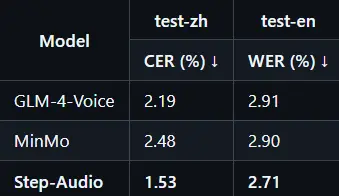
2. 语音合成
Step-Audio 在内容一致性(CER/WER)上优于 GLM-4-Voice 和 MinMo,展现出更高的合成质量和自然度。
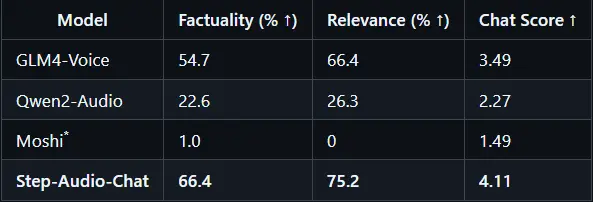
3. 语音对话
Step-Audio 在 StepEval-Audio-360 基准测试中表现优异,尤其是在指令跟随、语音理解、逻辑推理和角色扮演方面。例如,在语音指令遵循测试中,Step-Audio 在语言、角色扮演和唱歌等类别上的表现均优于 GLM-4-Voice。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











