新Hume AI 开源 TTS 模型 TADA:文本 - 声学一对一同步,推理速度提升 5 倍且零幻觉在基于大语言模型(LLM)的文本转语音(TTS)领域,开发者长期面临一个“不可能三角”:速度、质量与可靠性难以兼得。传统的 LLM-TTS 系统往往因为文本与音频表示的不匹配,导致推理缓慢、内存消耗巨...语音模型# Hume AI# TADA# TTS9小时前0100
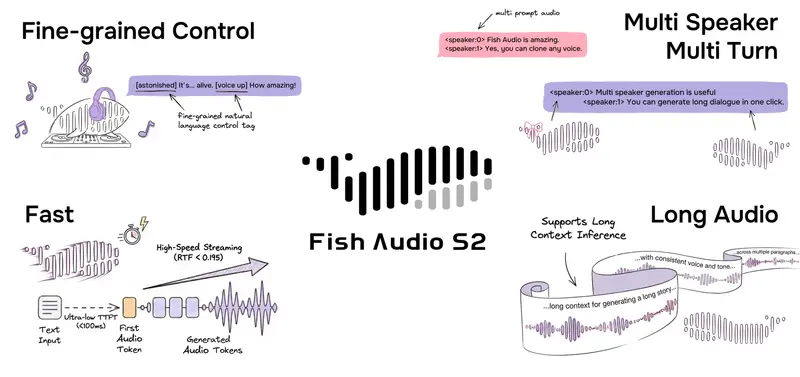
新Fish Audio 开源 Fish Audio S2 Pro:支持自然语言指令的精细化 TTS 模型,单卡 H200 实时因子低至 0.195在文本转语音(TTS)领域,如何在保持高保真音质的同时,实现对韵律、情感和副语言特征(如笑声、呼吸声)的精细化控制,一直是行业难点。今日,Fish Audio 正式开源 S2 模型及其完整的生产级推理...语音模型# Fish Audio# Fish Audio S2 Pro10小时前040
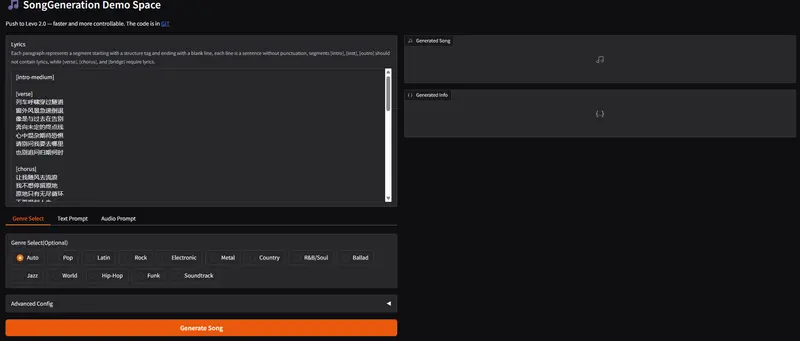
新腾讯开源SongGeneration 2:歌词准确率超越 Suno v5,首个真正达到“商业级”的开源音乐大模型腾讯 AI 实验室重磅发布 LeVo 2 (SongGeneration 2) —— 一个旨在打破开源 AI 音乐天花板的基础模型。经过大规模、严格的专家盲测评估,LeVo 2 在音乐性、歌词准确性和...语音模型# SongGeneration 2# 腾讯2天前0420
阿里通义发布 Fun-CosyVoice3.5 与 Fun-AudioGen-VD:自然语言指令即可实现“FreeStyle”语音与场景生成阿里通义实验室语音团队今日正式宣布,推出两款支持 FreeStyle 指令生成 的突破性模型:Fun-CosyVoice3.5 与 Fun-AudioGen-VD。 官方文档:https://help...语音模型# Fun-AudioGen-VD# Fun-CosyVoice3.5# 阿里通义1周前0230
MioCodec v2 发布:仅需 341 bps 即可重建 44.1kHz 高保真音频,TTS 模型无缝升级神器在口语语言建模(Speech Language Modeling)领域,我们长期面临着一个两难选择:是要高压缩率以降低计算成本,还是要高保真度以确保音质清晰?传统的神经音频编解码器往往难以兼得,且常常...语音模型# MioCodec2周前0120
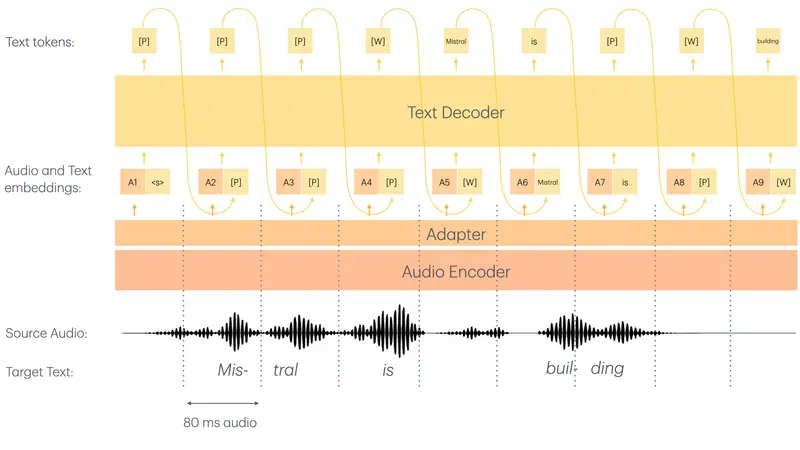
Mistral AI 发布 Voxtral Mini 4B Realtime 2602:40 亿参数开源实时语音模型,延迟低至 500ms 且支持中文在实时语音处理领域,准确性与低延迟往往难以兼得。传统的开源模型(如 Whisper)虽然精度高,但通常需要收集完整音频片段后才能开始转写,导致显著的延迟,无法满足实时字幕或即时语音助手的需求。 模型...语音模型# Mistral AI# Voxtral Mini 4B Realtime 26023周前0200
谷歌发布全新音乐模型 Lyria 3:已集成到Gemini,输入文字或图片,30 秒生成原创音乐谷歌周三正式宣布,其旗舰 AI 助手 Gemini 迎来重大功能升级——集成音乐生成能力。这一新功能由谷歌旗下 DeepMind 团队最新研发的 Lyria 3 模型驱动,目前正处于测试阶段,面向全球...早报语音模型# Lyria 3# 谷歌# 音乐模型3周前0170
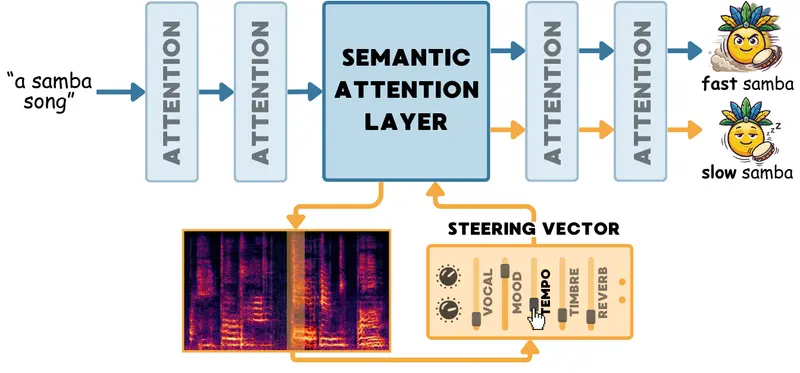
TADA:给AI音乐生成装上"调音台",让创作精准可控想象一下,你对AI说"生成一首桑巴舞曲",它确实生成了一段不错的音乐。但你现在觉得节奏稍微快了点,或者想把女声换成男声,又或者想加点钢琴伴奏——用传统的文字提示,你只能说"一首快节奏的男性演唱桑巴舞曲...语音模型# TADA# 音频扩散模型3周前0150
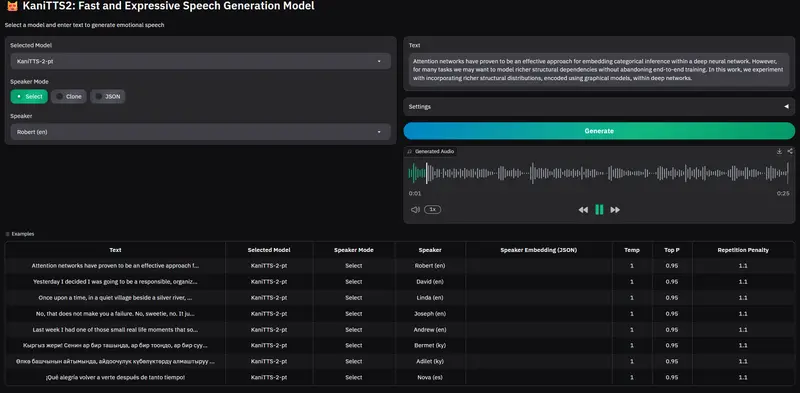
NineNineSix 开源 KaniTTS2:4 亿参数实时对话 TTS 模型,支持语音克隆与多语言AI 初创公司 NineNineSix 正式开源其新一代文本转语音(TTS)模型 KaniTTS2。该模型专为低延迟、高自然度的实时对话场景设计,支持语音克隆、多语言输出,并提供完整的从零预训练代码框...语音模型# KaniTTS2# TTS 模型3周前0200
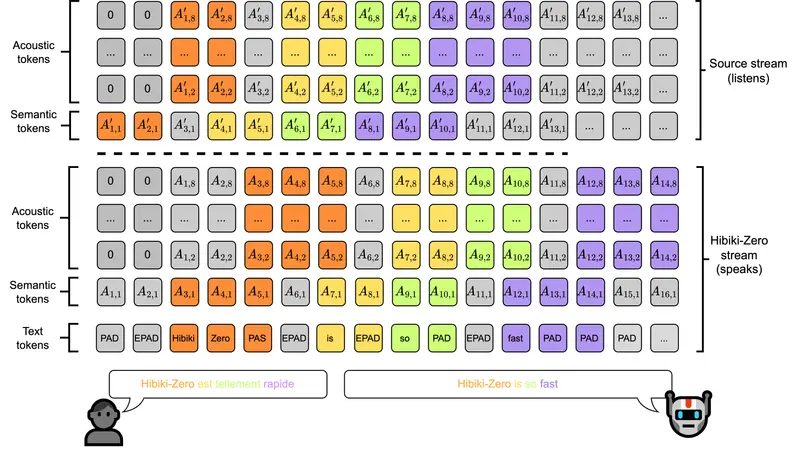
Kyutai 开源 Hibiki-Zero:3B 参数实时语音翻译模型,无需词级对齐,支持音色迁移实时语音翻译的核心挑战在于如何在翻译质量与系统延迟之间取得最佳平衡。传统方法通常需要大量精细标注的词级对齐数据来指导模型何时开始翻译,这不仅成本高昂,也极大地限制了模型向新语言的扩展能力。 为彻底解决...语音模型# Hibiki-Zero# 实时语音翻译模型4周前0130
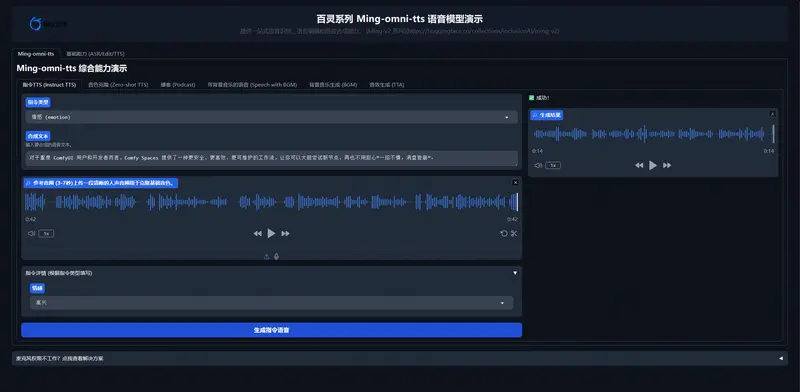
蚂蚁集团 inclusionAI 团队发布统一生成模型Ming-omni-tts:统一语音、音乐与声音生成,实现高精度细粒度可控音频合成蚂蚁集团 inclusionAI 团队近期正式发布了 Ming-omni-tts,这是一款设计简洁、运行高效的统一音频生成模型。它不仅可以在单一框架内合成高质量的语音,还能同时生成音乐与各类环境声音...语音模型# Ming-omni-tts# 统一生成模型4周前0400
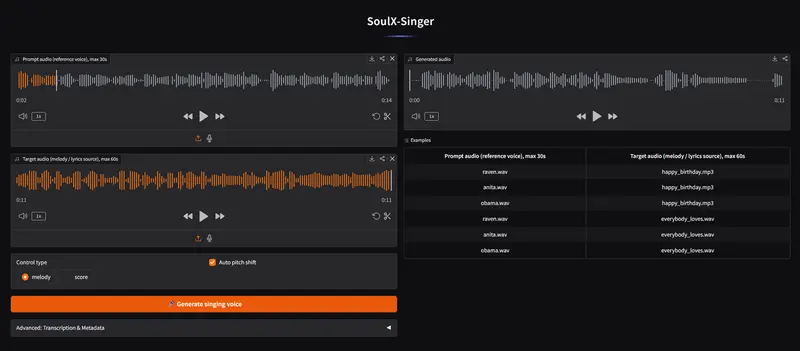
SoulX-Singer:42,000 小时训练的零样本歌声合成模型,支持 MIDI 与旋律双模式控制Soul AI Lab(中国)联合吉利汽车研究院、天津大学及西北工业大学,共同发布了一款高保真、零样本歌声合成模型——SoulX-Singer。这款模型的核心优势的是,无需对未见歌手进行任何微调,就能...语音模型# SoulX-Singer# 歌声合成模型4周前0290