Linacodec:12.5 令牌/秒的高压缩音频分词器,支持 48kHz 高清语音在 AI 语音模型(TTS/ASR)领域,音频分词器(Audio Tokenizer)的效率直接决定训练速度、推理延迟与生成质量。传统方案如 EnCodec、DAC 虽能压缩音频,但令牌率高、采样率低...语音模型# Linacodec# 音频分词器1个月前0130
Mistral AI 发布 Voxtral Transcribe 2:开源实时模型 + 高性价比批量转录,全面支持多语言语音应用Mistral AI 推出全新 Voxtral Transcribe 2 系列语音转文本(ASR)模型,包含面向批量离线处理的 Voxtral Mini Transcribe V2 和专为低延迟实时场...语音模型# Mistral AI# Voxtral Mini Transcribe V2# Voxtral Realtime1个月前0400
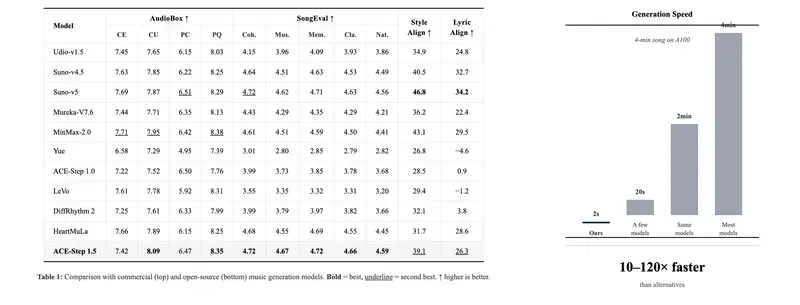
ACE Studio×阶跃星辰推出ACE-Step v1.5:混合架构开源音乐模型,商用就绪且50+语言适配ACE Studio联合阶跃星辰(StepFun)重磅发布ACE-Step v1.5,这是一款专为消费级硬件打造的高效开源音乐基础模型,首次将商业级音乐生成能力下沉到普通硬件环境。该模型不仅在核心评估...语音模型# ACE Studio# ACE-Step v1.5# 阶跃星辰1个月前0910
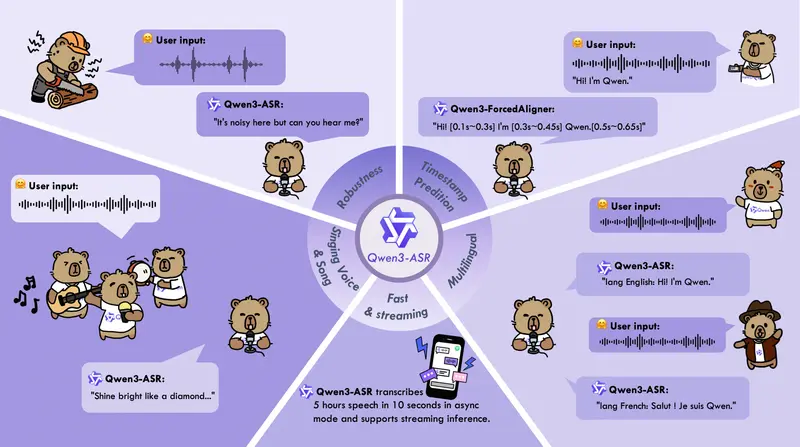
通义千问开源 Qwen3-ASR 与 Qwen3-ForcedAligner:支持流式、多语言、高并发的语音识别与对齐工具Qwen(通义千问)团队正式开源全新一代语音技术方案——Qwen3-ASR系列语音识别模型与Qwen3-ForcedAligner强制对齐模型。该系列包含Qwen3-ASR-1.7B、Qwen3-AS...语音模型# Qwen# Qwen3-ASR# Qwen3-ForcedAligner1个月前0440
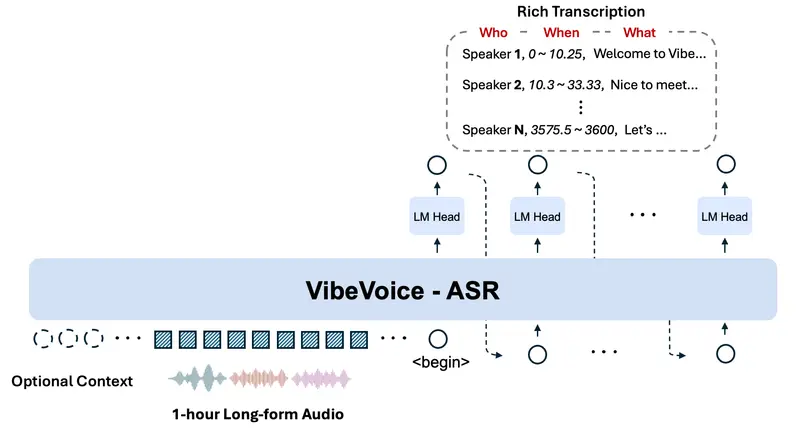
微软开源 VibeVoice-ASR:支持60分钟长音频的端到端语音转写模型微软正式开源 VibeVoice-ASR——一款面向真实场景的统一语音识别模型。它能单次处理长达60分钟的连续音频,并输出包含说话人身份、精确时间戳与文本内容的结构化转录结果,同时支持用户注入自定义热...语音模型# VibeVoice-ASR# 微软2个月前0220
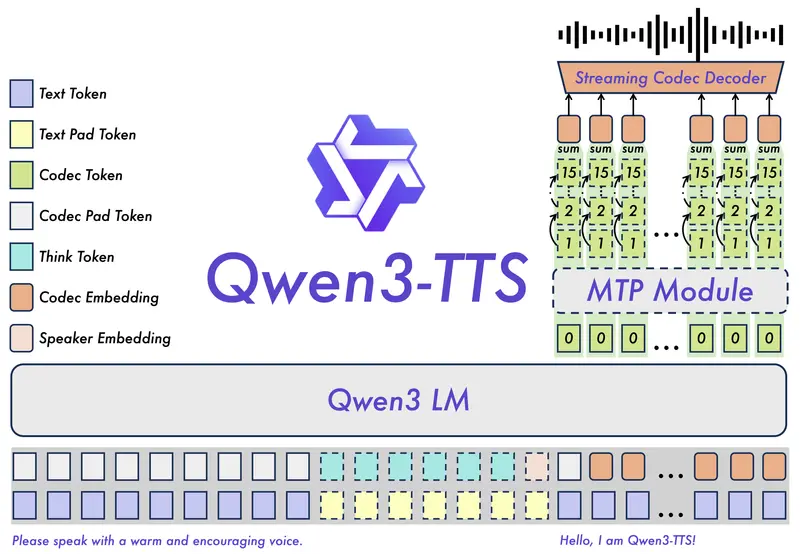
Qwen3-TTS 全家桶开源:支持音色克隆、创造与多语言拟人语音在语音生成技术快速迭代的当下,开发者与用户对高保真、可定制、低延迟的语音合成方案需求日益迫切。阿里Qwen项目组推出的 Qwen3-TTS 开源全家桶,凭借音色克隆、音色创造、拟人化语音生成与自然语言...语音模型# Qwen3-TTS# 阿里2个月前0920
英伟达推出实时语音对话模型PersonaPlex,打造支持自定义角色与声音的自然对话AI长期以来,语音对话 AI 面临一个根本性矛盾: 传统级联系统(ASR → LLM → TTS)允许你自定义角色和声音,但对话僵硬、延迟高、无法被打断; 全双工模型(如 Moshi)实现了自然的话轮转换...语音模型# PersonaPlex# 实时语音对话模型# 英伟达2个月前0290
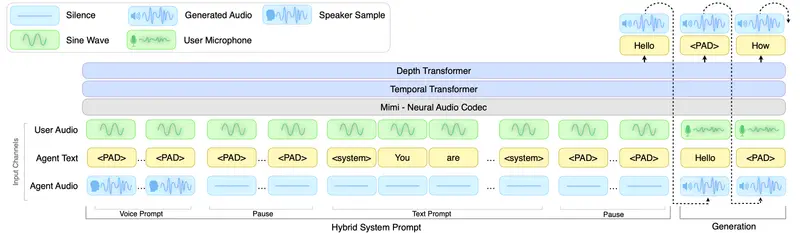
FlashLabs推出Chroma 1.0:首个开源实时语音对话模型,支持低延迟个性化语音克隆在虚拟人交互与语音合成领域,兼顾低延迟、高保真语音克隆、多轮对话理解的模型一直是技术难点。由FlashLabs开发的 Chroma 1.0 正是一款突破性的多模态因果语言模型,它不仅能直接处理音频输入...语音模型# Chroma# FlashLabs# 实时语音对话模型2个月前04520
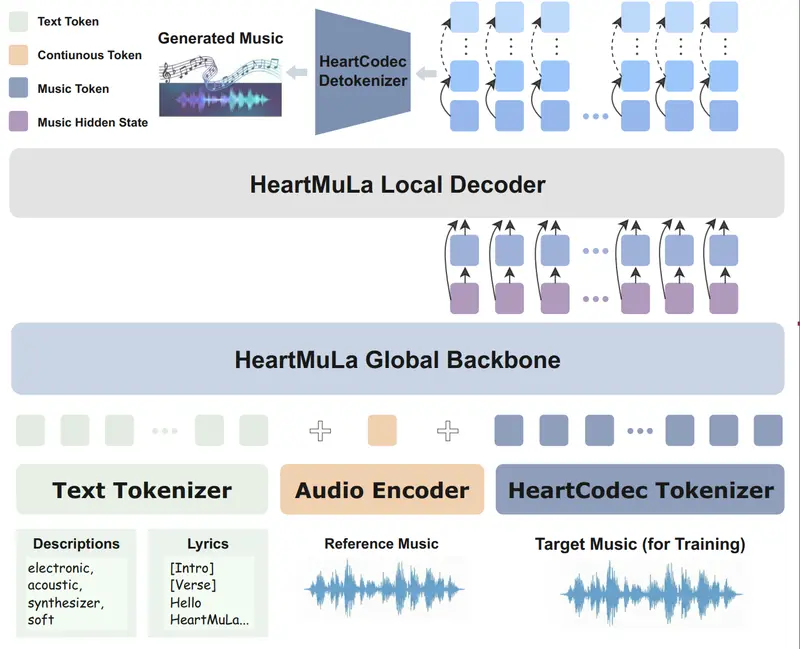
HeartMuLa:开源音乐基础模型家族,支持歌词识别、高保真生成与细粒度控制如果你曾幻想过——只需输入一段歌词和一句描述(如“一首欢快的流行歌,吉他伴奏,副歌要有电子音效”),AI 就能生成一首结构完整、音质高保真的歌曲——那么 HeartMuLa 项目正将这一愿景变为现实...语音模型# HeartMuLa# 音乐模型2个月前01960
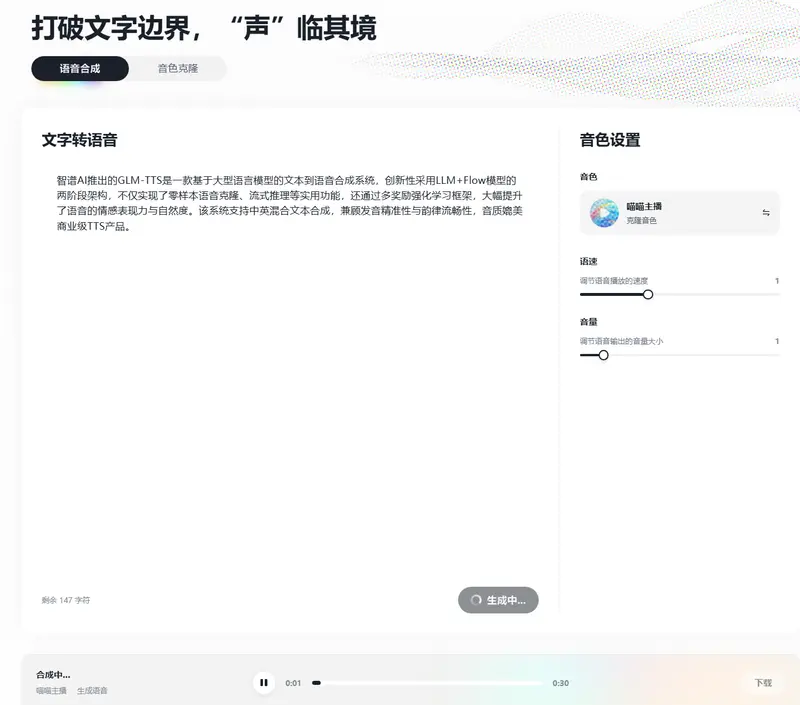
智谱AI开源GLM-TTS:LLM驱动的高质量TTS系统,支持零样本克隆与情感增强智谱AI推出的GLM-TTS是一款基于大语言模型的文本到语音合成系统,创新性采用LLM+Flow模型的两阶段架构,不仅实现了零样本语音克隆、流式推理等实用功能,还通过多奖励强化学习框架,大幅提升了语音...语音模型# GLM-TTS# 智谱AI2个月前0500
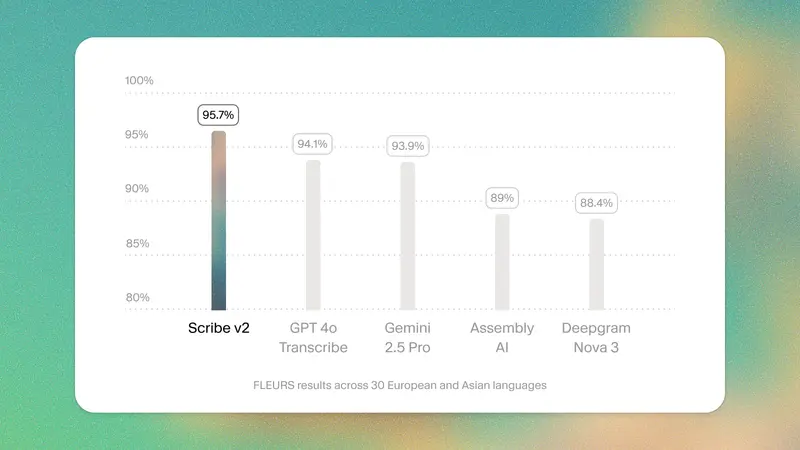
ElevenLabs 推出 Scribe v2:支持 90+ 语言的高精度批量转录模型ElevenLabs 正式发布 Scribe v2——一款专为大规模音视频内容处理设计的新一代语音转文字模型。与主打低延迟的 Scribe v2 Realtime 不同,Scribe v2 面向批量转...语音模型# ElevenLabs# Scribe v22个月前01770
Nemotron-Speech-Streaming-En-0.6B:面向低延迟与高吞吐的流式语音识别模型英伟达推出的 Nemotron-Speech-Streaming-En-0.6B 是 Nemotron Speech 系列中的首个统一语音识别(ASR)模型,专为实时英语转录场景设计。它同时支持低延迟...语音模型# Nemotron-Speech-Streaming-En-0.6B# 英伟达# 语音识别2个月前0260