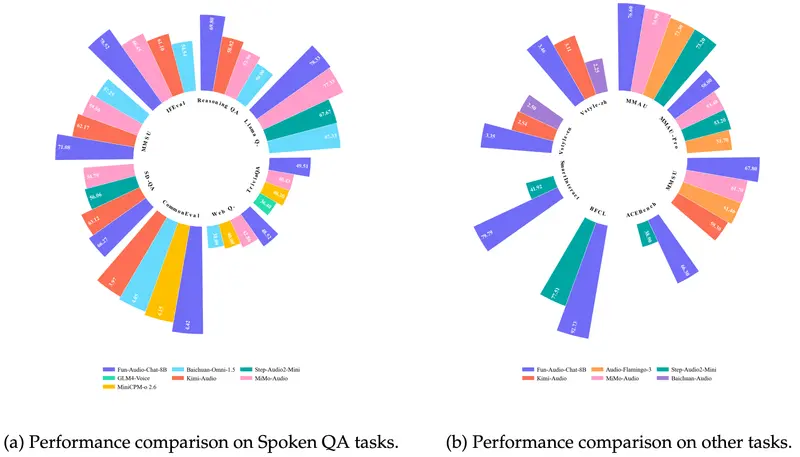
通义百聆发布 Fun-Audio-Chat:8B 端到端语音模型,延迟更低、效率更高通义实验室旗下语音团队 通义百聆(Tongyi Bailin)正式推出 Fun-Audio-Chat —— 一款专为自然、低延迟语音交互设计的端到端大型音频语言模型(Audio Language Mo...语音模型# Fun-Audio-Chat# 通义百聆3个月前0270
Chatterbox-Turbo 发布:3.5 亿参数、一步解码、支持副语言标签的高效 TTS 模型Resemble AI 正式开源 Chatterbox 系列——一个由三款高性能文本转语音(TTS)模型组成的开源 TTS 工具集,覆盖低延迟交互、多语言支持与创意语音控制三大典型场景。所有模型均支持...语音模型# Chatterbox-Turbo3个月前0610
Grok Voice Agent API 上线:支持多语言、实时工具调用与低延迟语音交互xAI 正式推出 Grok Voice Agent API,向开发者开放其在 Grok 移动应用及特斯拉车载系统中使用的语音交互技术。该 API 支持构建能实时对话、调用工具、搜索网络并流利使用数十种...语音模型# Grok Voice Agent3个月前0290
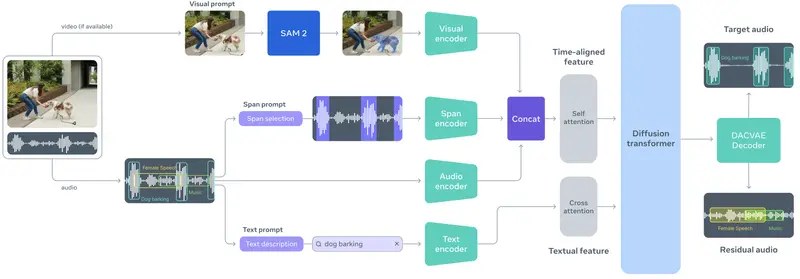
Meta发布SAM Audio:首个支持文本、视觉、时间提示的统一音频分离模型在图像领域,Meta 的 Segment Anything Model (SAM) 通过“任意分割”能力,彻底改变了计算机视觉的交互范式。如今,这一理念正式延伸至音频领域。 Meta 正式发布 SAM...语音模型# Meta# SAM Audio# 音频分离模型3个月前0950
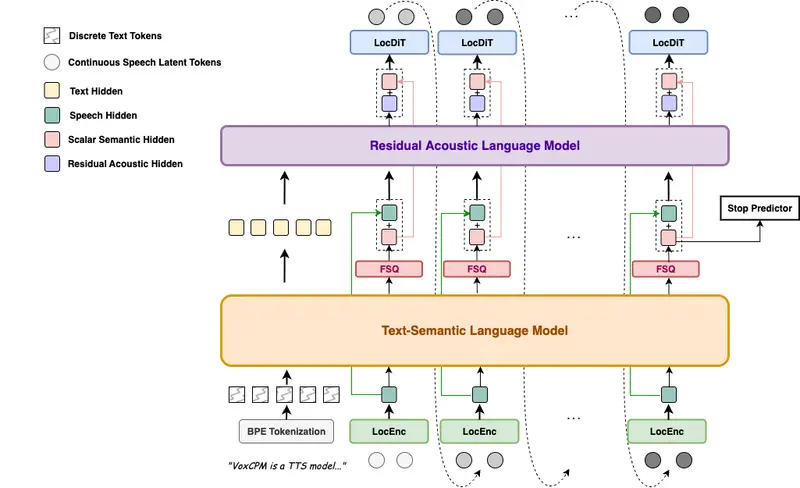
面壁智能发布 VoxCPM1.5:6.25Hz 标记率降低计算开销,支持高质量声音克隆2025 年 12 月 5 日,面壁智能正式发布 VoxCPM1.5 模型权重。作为 VoxCPM 系列的重大升级版本,它在保留上下文感知语音生成与零样本声音克隆能力的基础上,通过两项关键技术改进,显...语音模型# VoxCPM1.5# 面壁智能3个月前0290
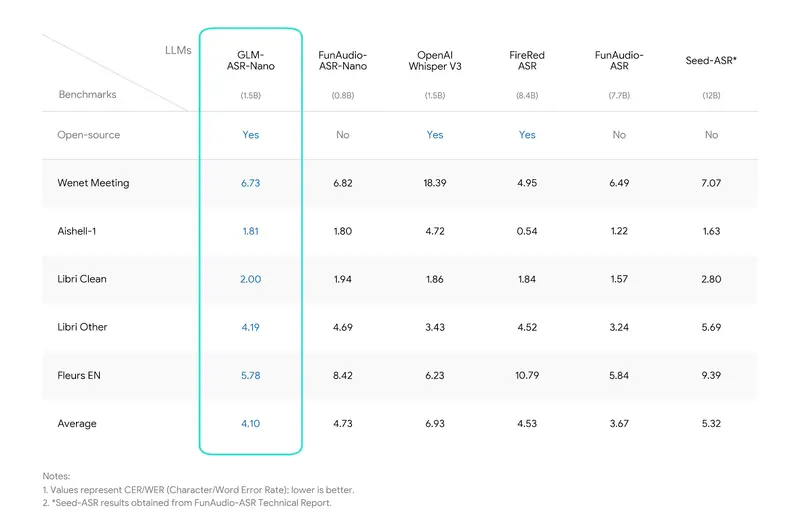
智谱AI语音识别模型GLM-ASR双版本登场:云端版精准识别多场景,Nano版开源免费,笔记本/手机均可部署智谱AI全新发布 GLM-ASR 系列语音识别模型,包含云端部署的 GLM-ASR-2512 与端侧轻量化的 GLM-ASR-Nano-2512 两个版本。其中 Nano 版以 1.5B 紧凑参数规模...语音模型# GLM-ASR-2512# GLM-ASR-Nano-2512# 智谱AI3个月前0390
微软发布轻量级实时TTS模型VibeVoice-Realtime:300ms响应的流式长文本TTS模型实时文本转语音(TTS)技术在智能助手、实时播报、大模型交互等场景中有着极高的需求,但传统模型往往面临“延迟高”“长文本生成不稳定”“流式输入支持差”等痛点。 微软推出了一款轻量级实时TTS模型——V...语音模型# VibeVoice-Realtime# 微软3个月前0570
阶跃星辰开源Step-Audio-R1:首个支持测试时计算扩展的音频大语言模型,“越想越准”比肩Gemini 3阶跃星辰开源的 Step-Audio-R1 打破了传统音频模型的性能瓶颈,成为首个支持“测试时计算扩展”的音频大语言模型。它通过创新的模态落地推理蒸馏技术,让模型直接基于声学特征进行链式思考,而非依赖...语音模型# Step-Audio-R1# 阶跃星辰3个月前0450
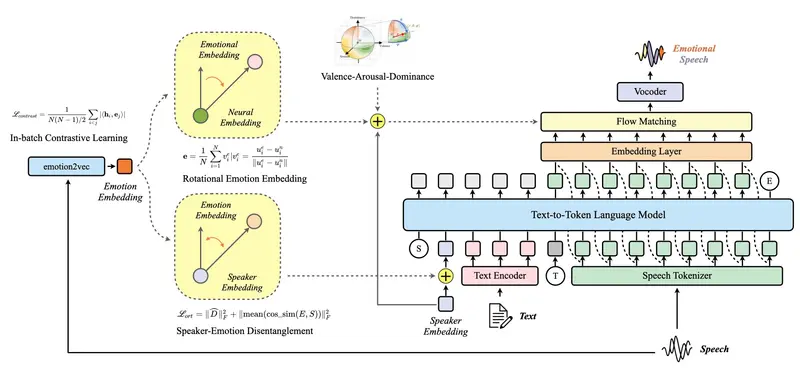
阿里开源Marco-Voice:说话人-情感独立调控,语音克隆相似度0.8275碾压同类阿里巴巴国际数字商务团队推出的开源语音合成框架 Marco-Voice,以“说话人-情感解耦”为核心创新,整合语音克隆、情感可控合成、跨语言生成三大功能,构建了统一且高效的文本转语音系统。该框架通过批...语音模型# Marco-Voice# TTS3个月前0550
Maya1:开源 3B 语音模型,支持自然语言控制与情感标签的文本到语音生成Maya Research 近期发布了一款突破性的开源文本到语音(TTS)模型——Maya1。这款仅3B参数的模型,不仅能将文本与自然语言描述转化为富有情感的24kHz高质量语音,还支持单GPU实时运...语音模型# Maya1# 语音模型4个月前0730
Meta 开源 Omnilingual ASR:支持 1600+ 语言的语音识别系统Meta AI 近日发布了 Omnilingual ASR——一套开源、可扩展的多语言自动语音识别(ASR)系统,支持 1600 多种语言,并能通过零样本上下文学习泛化到 超过 5400 种语言,包括...语音模型# Meta# Omnilingual ASR# 语音识别4个月前0990
阶跃星辰开源 Step-Audio-EditX:首个基于 LLM 的迭代式音频编辑模型阶跃星辰(Step AI)正式发布 Step-Audio-EditX —— 一款革命性的基于大语言模型(LLM)的音频编辑系统,首次实现对语音情感、说话风格与副语言特征的高精度、迭代式、零样本控制,并...语音模型# Step-Audio-EditX# 阶跃星辰# 音频编辑模型4个月前01690