Maya Research 近期发布了一款突破性的开源文本到语音(TTS)模型——Maya1。这款仅3B参数的模型,不仅能将文本与自然语言描述转化为富有情感的24kHz高质量语音,还支持单GPU实时运行,直接打破了此前专有TTS系统在“表现力”与“部署门槛”上的垄断。
- GitHub:https://github.com/MayaResearch/maya1-fastapi
- 模型:https://huggingface.co/maya-research/maya1
- Demo:https://huggingface.co/spaces/maya-research/maya1
无论是为虚拟助手定制专属声线、给游戏角色赋予独特语音,还是快速生成带情感的播客内容,Maya1都以开源、可控、高效的特性,为开发者和创作者提供了全新选择。
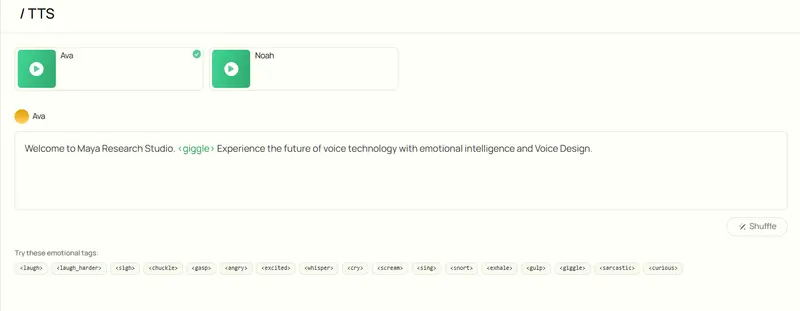
核心功能:用自然语言“指挥”语音风格
Maya1的核心优势在于“高度可控的表现力”,其操作逻辑简单直观,无需复杂参数配置:
1. 双输入设计,精准匹配需求
模型接受两个核心输入,即可生成定制化语音:
- 自然语言语音描述:像给配音演员提要求一样自由表达,例如“20多岁的女性声音,英国口音,充满活力且发音清晰”“恶魔角色,男性低音,粗砺音色,缓慢节奏”;
- 目标文本:需要被朗读的内容,支持在文本中插入内联情感标签,实现局部语气控制。
2. 20+情感标签,细化表现力
文本中可直接嵌入<laugh>(笑声)、<sigh>(叹息)、<whisper>(低语)、<angry>(愤怒)、<giggle>(轻笑)、<gasp>(惊呼)、<cry>(哭泣)等超过20种情感标签,让语音在关键节点自然传递情绪,避免生硬的“机器人语调”。
3. 输出特性:高质量+实时流式
最终输出24kHz单声道音频,兼顾音质与传输效率;同时支持实时流式传输,完美适配助手交互、直播、游戏等对延迟敏感的场景。
技术架构:高效生成的核心逻辑
Maya1采用“Transformer解码器+神经音频编解码器”的分离式架构,既保证了生成质量,又降低了部署成本:
1. 模型基础:Llama风格仅解码器Transformer
核心模型基于Llama风格的仅解码器Transformer构建,参数规模仅3B,兼顾性能与轻量化。与传统TTS模型直接预测原始波形不同,Maya1专注于预测“SNAC神经音频编解码器”的离散令牌,大幅提升生成效率。
2. 关键组件:SNAC神经音频编解码器
SNAC是一款专为实时流式设计的神经音频编解码器,采用多尺度分层结构(支持约12、23、47Hz采样率),在保持自回归序列紧凑性的同时,能精准保留语音细节。其核心优势包括:
- 生成流程:文本→分词→生成SNAC令牌(每帧7个令牌)→解码→24kHz音频;
- 高效传输:支持约0.98kbps的实时流式传输,适配网络场景;
- 分离设计:SNAC解码器(如hubertsiuzdak/snac_24khz)独立于生成模型,可单独调用,让生成过程更易扩展。
这种“生成令牌+独立解码”的模式,相比直接波形预测,不仅降低了模型计算量,还提升了语音生成的稳定性和可控性。
训练数据:从大规模预训练到精细化微调
Maya1的高质量表现,源于“互联网规模预训练+工作室级微调”的双阶段数据管道:
1. 预训练阶段:覆盖广泛声学特征
基于互联网规模的英语语音语料库进行预训练,目的是学习丰富的声学覆盖范围和自然的语音韵律,为模型打下基础。
2. 微调阶段:聚焦表现力与可控性
在精选的专有工作室录音数据集上进行微调,数据具备三大特点:
- 标注细致:每个样本均有人类验证的语音描述、超过20个情感标签;
- 多样性强:涵盖多种英语口音、不同角色声线和语音变体;
- 处理规范:经过严格的数据预处理流程,确保质量统一:
- 24kHz单声道重采样,响度归一化至-23 LUFS;
- 语音活动检测,修剪沉默片段,保留1-14秒有效内容;
- 使用Montreal Forced Aligner进行强制对齐,优化短语边界;
- MinHash LSH文本去重+Chromaprint音频去重,避免数据冗余;
- SNAC编码,按每帧7个令牌打包处理。
3. 格式优化:自然语言描述的高效编码
为解决“模型误读描述”或“泛化不佳”的问题,团队最终采用XML风格的属性包装器编码描述与文本,既支持自由形式的描述(类似配音简报),又能让模型精准识别指令,无需开发者学习自定义参数格式。
部署方案:单GPU即可落地,支持多场景适配
Maya1的设计初衷之一是“降低使用门槛”,提供了从快速测试到生产部署的全流程支持,核心亮点是“单GPU实时运行”:
1. 基础部署要求
- 硬件:推荐16GB及以上显存的单GPU(如A100、H100专业卡,或消费级RTX 4090);
- 软件:通过Hugging Face加载,核心代码示例:
from transformers import AutoModelForCausalLM from snac import SNAC # 加载Maya1模型 model = AutoModelForCausalLM.from_pretrained( "maya-research/maya1", torch_dtype=torch.bfloat16, device_map="auto" ) # 加载SNAC解码器 snac = SNAC.from_pretrained("hubertsiuzdak/snac_24khz")
2. 生产级部署工具
- vLLM流式推理脚本:提供
vllm_streaming_inference.py,支持自动前缀缓存(优化重复语音描述场景)、WebAudio环形缓冲区、多GPU扩展,目标延迟低于100毫秒,满足实时交互需求; - 轻量化变体:发布GGUF量化版本,可通过llama.cpp部署,进一步降低硬件要求;
- 可视化工具:提供ComfyUI节点,集成情感标签助手和SNAC解码器,拖拽式操作即可生成语音。
3. 快速体验渠道
官方在Hugging Face Space提供交互式浏览器演示,用户无需部署,直接输入文本和语音描述就能听取生成结果,快速验证效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











