大模型是否只能存在于云端集群?LiquidAI 给出了否定的答案。
LiquidAI 正式发布了 LFM2-24B-A2B,这是其 LFM2 家族中规模最大的早期模型。这款稀疏混合专家(MoE)模型拥有 240 亿总参数,但在推理时每个 token 仅激活 20 亿参数。这一精妙的设计使其能够完美适配 32GB 内存 的消费级设备,包括配备集成 GPU 或专用 NPU 的笔记本电脑和台式机,真正实现了高性能大模型的“端侧落地”。
- 模型:https://huggingface.co/LiquidAI/LFM2-24B-A2B
- GGUF版:https://huggingface.co/LiquidAI/LFM2-24B-A2B-GGUF
核心架构:高效扩展的混合专家设计
LFM2-24B-A2B 并非简单的参数堆砌,而是基于 LiquidAI 独特的 混合架构 进行深度优化:
- 门控短卷积 + 分组查询注意力 (GQA):通过硬件在环架构搜索(Hardware-in-the-loop NAS)开发,这种设计结合了卷积的高效预填能力和注意力的长程建模优势,实现了极低的内存占用和超快的解码速度。
- 深度与专家数的双重扩展:
- 层数增加:从 LFM2-8B 的 24 层增至 40 层,构建更丰富的语义表示。
- 专家翻倍:每个 MoE 块的专家数量从 32 个增至 64 个,配合 Top-4 路由机制,提供更精细的任务专业化能力。
- 激活控制:为了将激活参数严格控制在 23 亿 以内,每个专家的宽度略作收窄(中间层 1536 vs 1792)。
- 容量与效率的平衡:总参数增加了 3 倍(8B → 24B),但激活参数仅增长 1.5 倍。这意味着模型将巨大的知识容量存储在“休眠”参数中,仅在需要时唤醒,从而在保持边缘设备友好性的同时,大幅提升了智能水平。
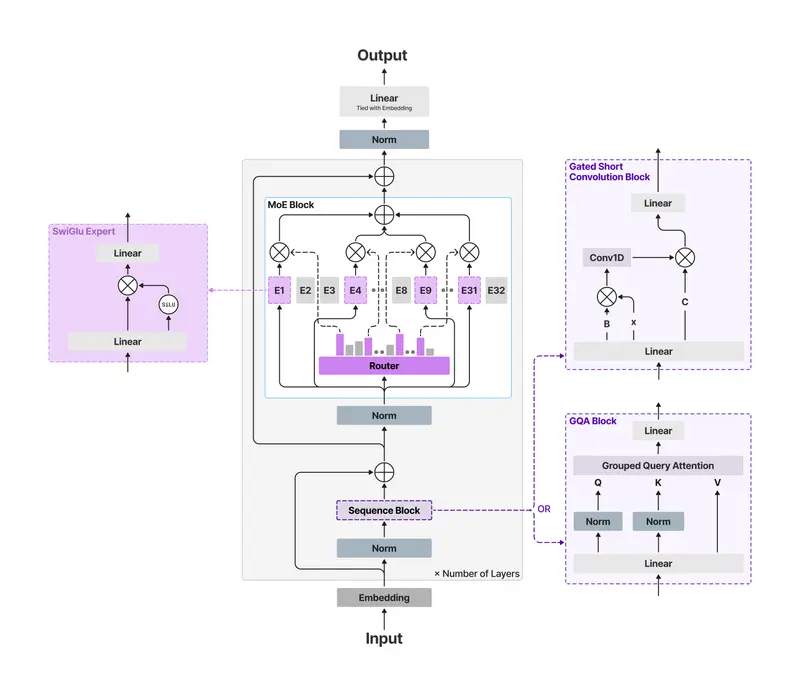
关键数据:前两层保持密集连接以确保训练稳定性,注意力层与卷积层比例维持在 1:3(40 层中 10 层为注意力),完美继承了 LFM2 家族的快速预填特性。
性能表现:遵循扩展定律,推理速度惊人
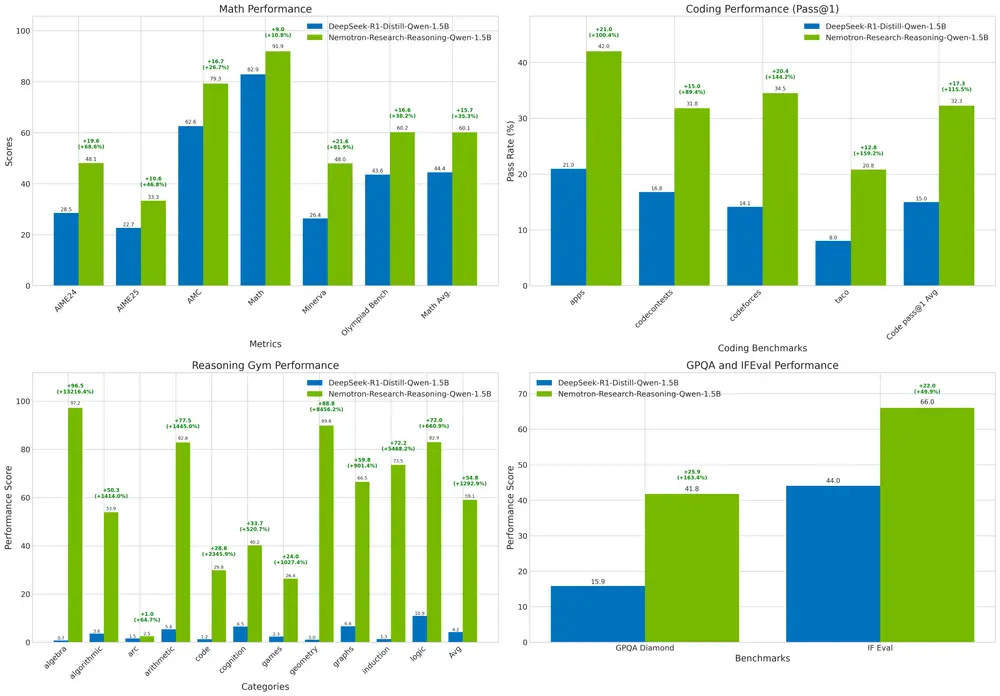
1. 质量随规模线性提升
LiquidAI 验证了 LFM2 架构在从 3.5 亿 (350M) 到 240 亿 (24B) 的近 100 倍参数范围内,依然遵循可预测的对数线性扩展定律。
- 在 GPQA Diamond、MMLU-Pro、GSM8K、MATH-500 等硬核基准测试中,LFM2-24B-A2B 展现了显著的质量飞跃,未出现小模型常见的瓶颈。
- 目前模型已基于 17 万亿 Token 进行训练(预训练仍在进行中),并以轻量级后训练方式发布为指令模型,响应迅速且实用。
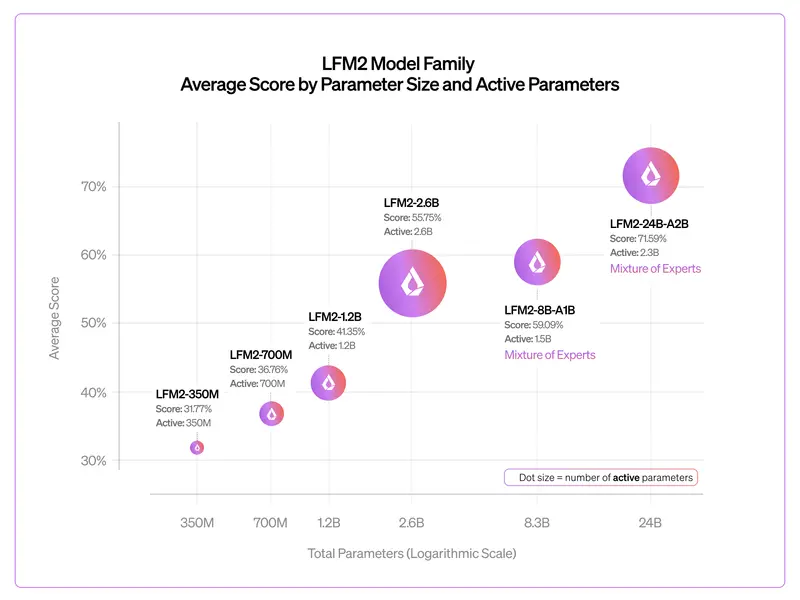
2. 端侧推理:消费级硬件的福音
得益于低激活参数设计,LFM2-24B-A2B 可通过 llama.cpp (GGUF 格式)、vLLM 和 SGLang 轻松部署。
- 实测设备:在搭载 AMD Ryzen AI Max+ 395 的笔记本上,即使运行 Q4_K_M 量化版本,其在不同上下文长度下的预填和解码吞吐量均表现出色。
- NPU 支持:LiquidAI 正与硬件伙伴合作,进一步释放移动设备 NPU 的潜力,让 24B 模型在端侧运行更加丝滑。
3. 云端吞吐:单卡超越同级
在服务器端,LFM2-24B-A2B 同样表现卓越。在单张 H100 SXM5 GPU 上使用 vLLM 测试:
- 并发能力:在 1024 个并发请求下,吞吐量达到 26.8K tokens/秒。
- 对比优势:相比同规模的 Qwen3-30B-A3B (30B/3.3B) 和 gpt-oss-20b (21B/3.6B),LFM2-24B-A2B 凭借更优的架构设计,在持续批处理场景下实现了更高的吞吐量,显著降低了服务成本。
开源与生态:立即开始构建
LFM2-24B-A2B 作为开放权重模型,现已在 Hugging Face 上线。LiquidAI 鼓励开发者将其应用于各类场景,从本地个人助手到高并发云服务。
- 下载权重:访问 Hugging Face 获取模型文件。
- 本地运行:支持 llama.cpp 多种量化等级,一键在 MacBook 或 Windows 笔记本上运行。
- 微调定制:提供完整文档,支持针对特定领域进行微调。
- 在线体验:通过 LiquidAI Playground 直接测试模型能力。
里程碑:LFM2 家族在 Hugging Face 的下载量已突破 1000 万次!
未来展望
目前的 LFM2-24B-A2B 仅是序幕。随着预训练的完成,LiquidAI 计划推出经过更强后训练和强化学习(RLVR)优化的 LFM2.5-24B-A2B 版本,进一步提升推理能力和复杂任务处理水平。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











