
继发布超大规模的 Qwen3-Coder-480B-A35B-Instruct 后,阿里通义千问团队近日推出一款更轻量但性能强劲的新版本:
这是 Qwen3-Coder 系列中面向高效部署与实际编码任务的精简型号,在保持卓越代码理解与生成能力的同时,显著降低资源消耗,更适合本地或边缘环境运行。
- Hugging Face:https://huggingface.co/Qwen/Qwen3-Coder-30B-A3B-Instruct
- 魔塔:https://modelscope.cn/models/Qwen/Qwen3-Coder-30B-A3B-Instruct
- GGUF版本:https://huggingface.co/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF
模型定位:小而强的代码助手
| 项目 | 值 |
|---|---|
| 模型类型 | 因果语言模型(Causal LM) |
| 总参数量 | 30.5B |
| 激活参数量 | 3.3B(激活专家) |
| 层数 | 48 |
| 注意力机制 | GQA(32Q / 4KV) |
| MoE 结构 | 128 专家,每次激活 8 个 |
| 原生上下文长度 | 262,144 令牌(约 256K) |
| 可扩展上下文 | 使用 Yarn 技术可达 1M 令牌 |
该模型采用 混合专家(MoE)架构,通过稀疏激活机制,在推理时仅调用部分专家,实现高性能与高效率的平衡。
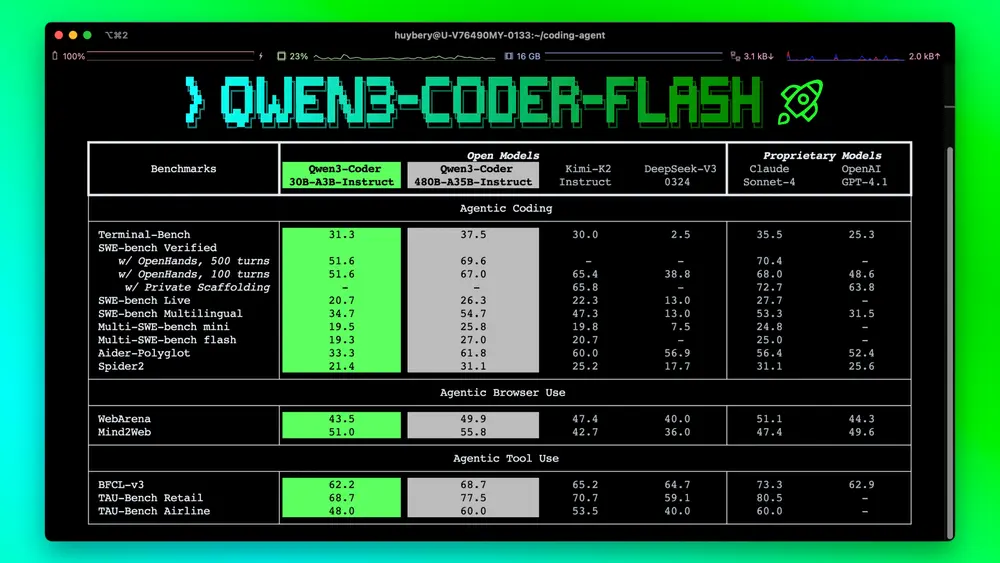
核心能力亮点
✅ 显著提升的代理式编码能力
Qwen3-Coder-30B 在以下任务中表现突出,是当前开源模型中的领先者之一:
- Agent-based coding(代理编码)
能够在复杂项目环境中自主规划、编写、调试代码。 - Agent Browser Use(浏览器代理)
支持通过自然语言指令操作浏览器,完成网页交互任务。 - 仓库级代码理解
借助 256K 原生上下文,可一次性加载大型代码库,进行跨文件分析、重构建议、依赖追踪等任务。
💡 实际场景示例:上传一个包含数百个文件的 GitHub 仓库,模型可理解整体架构并回答“这个项目是如何实现用户认证的?”这类问题。
✅ 广泛平台支持与标准化函数调用
模型已适配主流代码代理平台,包括:
- Qwen Code
- CLINE
并采用统一设计的函数调用格式,便于集成到自动化工作流中,提升多系统兼容性。
重要变更:不再输出 <think> 块
与早期 Qwen-Coder 版本不同,此模型仅支持非思考模式(non-thinking mode)。
这意味着:
- ❌ 不再生成
<think>...</think>思维过程标记 - ✅ 无需手动设置
enable_thinking=False - ✅ 输出更干净,适合直接用于代码生成和 API 集成
这一变化简化了使用流程,也表明模型在推理路径上已做内部优化,无需暴露中间思维链。
最佳实践建议
为充分发挥模型性能,官方推荐以下配置:
1. 采样参数
temperature: 0.7 # 适度随机,避免死板
top_p: 0.8 # 核采样,保留高质量候选
top_k: 20 # 限制候选集大小
repetition_penalty: 1.05 # 抑制重复输出
适用于大多数代码生成、解释、转换任务。
2. 输出长度设置
- 建议最大输出长度:65,536 令牌
- 对于长代码生成、批量重构等任务,应确保生成器支持长输出
⚠️ 注意:虽然模型原生支持 256K 输入,但输出长度仍需单独配置,建议不低于 32K,复杂任务设为 65K。
适用场景
| 场景 | 优势 |
|---|---|
| 本地代码助手 | 30B 级别可在单张高端消费卡(如 H100/A100)部署 |
| 企业级代码分析 | 支持整库理解,适合 CI/CD 集成 |
| 编程教育辅助 | 可解释复杂算法逻辑,生成教学示例 |
| 自动化脚本生成 | 结合函数调用,实现 CLI 或 Web 自动化 |
480B 版本对比
| 特性 | Qwen3-Coder-30B | Qwen3-Coder-480B |
|---|---|---|
| 总参数 | 30.5B | 480B |
| 激活参数 | 3.3B | 35B |
| 上下文 | 256K(可扩至1M) | 相同 |
| 推理成本 | 低,适合本地部署 | 高,需多卡集群 |
| 适用人群 | 开发者、中小企业 | 大模型研究机构、云服务厂商 |
两者在核心能力上保持一致,30B 版本是面向实际应用的高效选择。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











