MAI-DS-R1 是一个由微软 AI 团队对 DeepSeek-R1推理模型进行后训练的版本,提升其对受限话题的响应能力并改善其风险状况,同时保持推理能力和竞争力。简单来说就是把欧美的偏见加进去。
模型详情
模型描述
MAI-DS-R1 是基于 DeepSeek-R1 的推理模型,经微软 AI 团队后训练,填补了先前版本的信息缺口并提升了风险状况,同时保留了 R1 的推理能力。训练数据包括来自 Tulu 3 SFT 数据集的 11 万个安全性和非合规性示例,以及内部开发的约 35 万个多语言示例,涵盖了具有报告偏见的各种话题。
MAI-DS-R1 成功解锁了原始 R1 模型中大多数被屏蔽的查询,同时在相关安全基准测试中超越了最近发布的 R1-1776 模型(由 Perplexity 后训练)。这些成果在保留原始 DeepSeek-R1 通用推理能力的同时实现。
注意:微软对该模型进行了后训练以解决某些输出限制,但模型仍保留了之前的局限性和安全考量。
使用场景
直接使用
MAI-DS-R1 保留了 DeepSeek-R1 的通用推理能力,可用于广泛的语言理解和生成任务,特别是在复杂推理和问题解决中。主要直接用途包括:
通用文本生成与理解:为各种提示生成连贯、上下文相关的文本,包括对话、写作或根据提示续写故事。 通用知识任务:回答需要事实知识的开放领域问题。 推理与问题解决:通过链式思维策略处理多步骤推理任务,如数学应用题或逻辑谜题。 代码生成与理解:通过生成代码片段或解释代码协助编程任务。 科学与学术应用:在 STEM 和研究领域协助结构化问题解决。
下游使用(可选)
该模型可作为进一步微调的基础,适用于特定领域的推理任务,如数学自动辅导系统、编码助手或科学/技术领域的研究工具。
超出范围的使用
由于伦理/安全问题或模型在某些领域的可靠性不足,以下用途超出范围:
医疗或健康建议:模型非医疗设备,无法保证提供准确的医疗诊断或安全的治疗建议。 法律建议:模型非律师,不应委托其提供明确的法律咨询、解释法律或独自做出法律决定。 安全关键系统:模型不适合用于可能导致伤害、生命损失或重大财产损失的自主系统,如无人驾驶车辆、航空控制、医疗生命支持系统或无人工监督的工业控制。 高风险决策支持:不应依赖模型进行影响财务、安全或个人福祉的决策,如财务规划或投资建议。 恶意或不道德使用:不得使用模型生成有害、非法、欺骗性或不道德内容,包括仇恨言论、暴力、骚扰或侵犯隐私/知识产权。
偏见、风险与局限性
偏见:模型可能保留训练数据及原始 DeepSeek-R1 中的偏见,特别是在文化和人口统计方面。 风险:模型可能仍会虚构事实、易受对抗性提示影响,或在某些条件下生成不安全、偏见或有害内容。开发者应实施内容审查和使用监控以减轻滥用风险。 局限性:MAI-DS-R1 继承了 DeepSeek-R1 的知识截止,可能缺乏对近期事件或特定领域事实的了解。
推荐
为确保负责任使用,建议如下:
透明度:明确告知用户模型的潜在偏见和局限性。 人工监督与验证:直接和下游用户在敏感或高风险场景中应实施人工审查或自动验证输出。 使用防护:开发者应整合内容过滤、提示工程最佳实践和持续监控,以减轻风险并确保输出符合安全和质量标准。 法律与监管合规:模型可能输出政治敏感内容(如中国治理、历史事件),可能与当地法律或平台政策冲突。运营者需确保符合区域法规。
评估
测试数据、因素与指标
测试数据
模型在多个基准测试中进行了评估,涵盖不同任务并关注性能和危害缓解。关键基准包括:
公共基准:涵盖自然语言推理、问答、数学推理、常识推理、代码生成和代码补全,评估模型的通用知识和推理能力。 屏蔽测试集:包含 3.3 万个涉及 R1 屏蔽话题的提示,覆盖 11 种语言,评估模型解锁先前屏蔽内容的能力。 危害缓解测试集:来自 HarmBench 数据集的 320 个查询,分为标准、上下文和版权三类功能类别,涵盖八个语义类别,如虚假信息、化学/生物威胁、非法活动、有害内容、版权侵犯、网络犯罪和骚扰,评估模型泄露有害或不安全内容的比率。
因素
以下因素可能影响 MAI-DS-R1 的行为和性能:
输入话题与敏感性:模型针对先前屏蔽的话题进行了优化,能提供基础模型可能回避的信息。但对于真正有害或明确禁止的内容(如暴力指令),模型因微调仍保持限制。 语言:尽管 MAI-DS-R1 使用多语言数据进行后训练,但可能继承原始 DeepSeek-R1 的局限性,性能在英语和中文中最强。 提示复杂性与推理需求:模型在需要推理的复杂查询上表现良好,但极长或复杂提示仍可能构成挑战。 用户指令与角色提示:作为面向聊天的 LLM,MAI-DS-R1 的响应可受系统或开发者提供的指令(例如定义角色和风格的系统提示)以及用户措辞的影响。开发者应提供清晰指令以引导模型行为。
指标
公共基准: 准确率:模型输出与正确答案匹配的问题百分比。 Pass@1:模型首次尝试生成通过所有测试用例的正确解决方案的问题百分比。
屏蔽评估: 满意度(内部指标,衡量与问题相关性,0-4 分):旨在衡量解锁答案是否回答问题且不生成无关内容。 响应比例:成功解锁的先前屏蔽样本比例。
危害缓解评估: 攻击成功率:引发模型特定行为的测试用例百分比,按功能或语义类别评估。 微攻击成功率:所有类别的攻击成功率总平均值。
总结
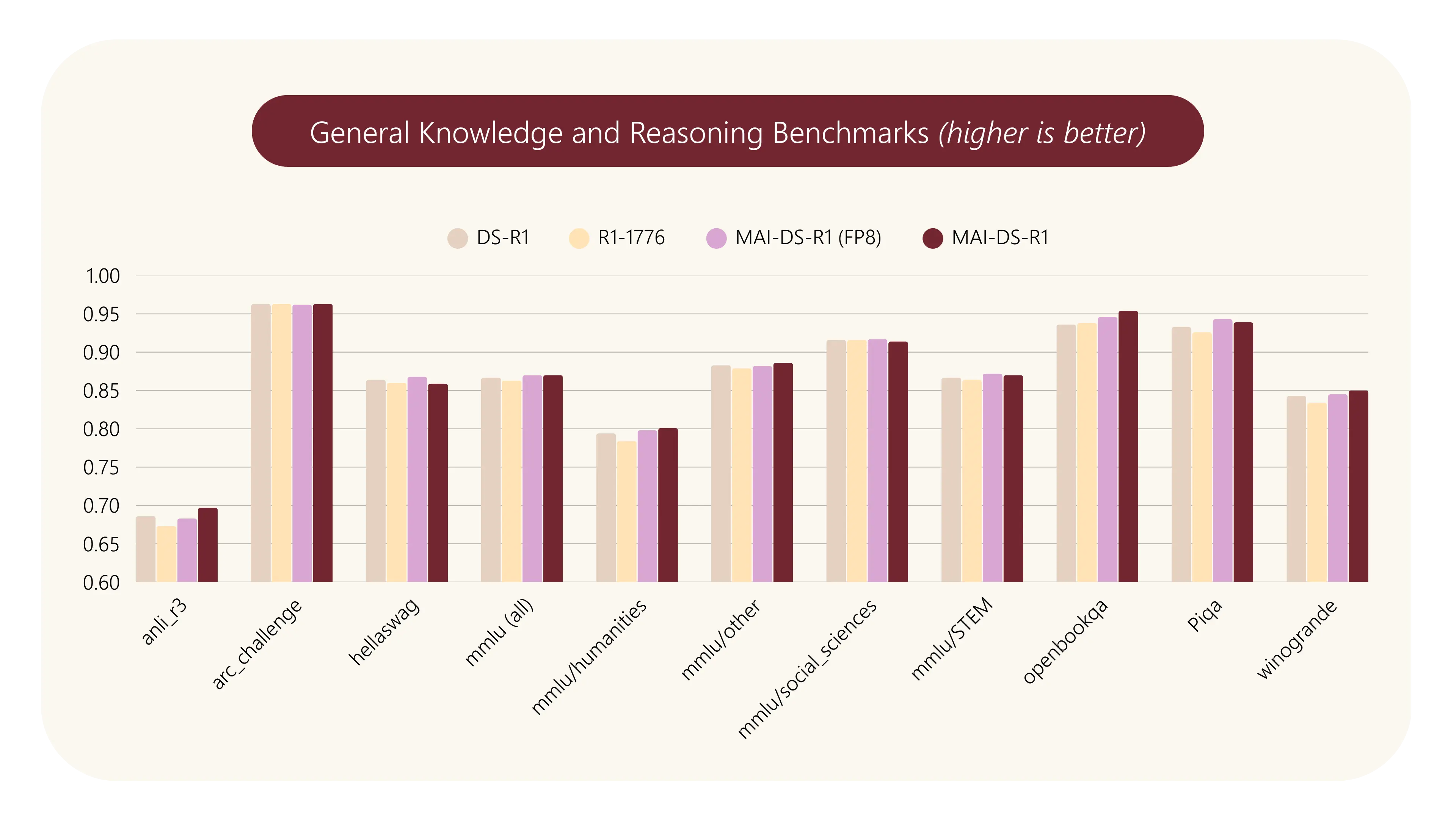
通用知识与推理:MAI-DS-R1 与 DeepSeek-R1 表现相当,略优于 R1-1776,特别是在 mgsm_chain_of_thought_zh 上,R1-1776 出现显著退步。 屏蔽话题:MAI-DS-R1 屏蔽了 99.3% 的样本,与 R1-1776 相当,并因更相关的响应获得更高的满意度评分。 危害缓解:MAI-DS-R1 在减少有害内容方面优于 R1-1776 和原始 R1 模型。
模型架构与目标
模型名称:MAI-DS-R1 架构:基于 DeepSeek-R1 的基于变换器的自回归语言模型,利用多头自注意力机制和专家混合(MoE)实现可扩展且高效的推理。 目标:后训练以减少与中共相关的限制并增强危害防护,同时保留原始模型的强大链式思维推理和通用语言理解能力。 预训练模型基础:DeepSeek-R1(671B)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











