
长期以来,数学推理一直是人工智能领域的一项重大挑战。尽管传统的语言模型在生成自然语言文本方面表现出色,但在解决需要深入领域知识和多步骤逻辑推导的复杂数学问题时,它们往往显得力不从心。为了弥合这一差距,英伟达推出了 OpenMath-Nemotron-32B 和 OpenMath-Nemotron-14B-Kaggle,这两款先进的数学推理 AI 模型不仅在 AIMO-2 数学竞赛中荣获第一名,还在多个基准测试中创下新的记录。
- OpenMath-Nemotron-32B:https://huggingface.co/nvidia/OpenMath-Nemotron-32B
- OpenMath-Nemotron-14B-Kaggle:https://huggingface.co/nvidia/OpenMath-Nemotron-14B-Kaggle
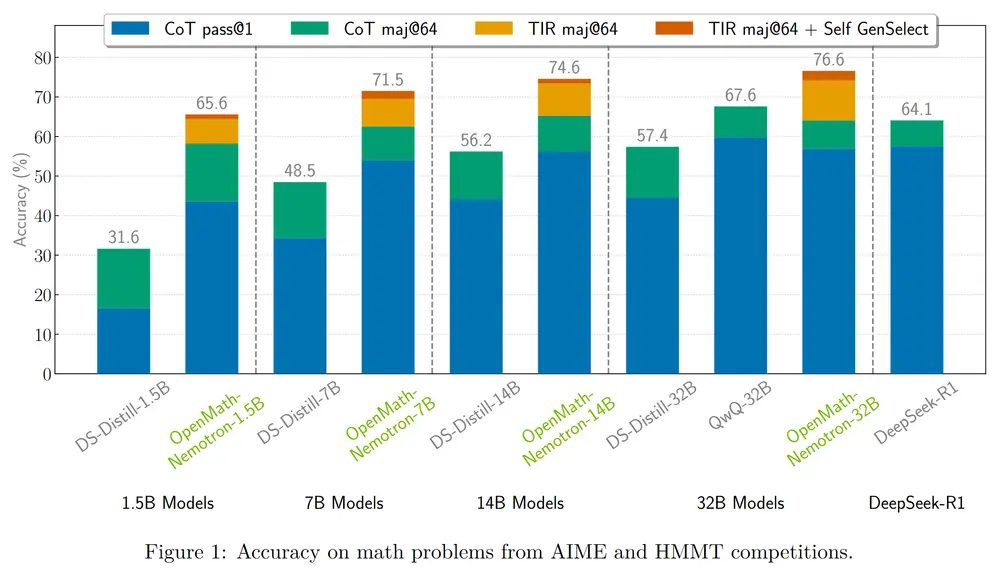
OpenMath-Nemotron 系列的核心亮点
1. OpenMath-Nemotron-32B:旗舰级数学推理模型
参数规模:328 亿个参数 硬件优化:利用 BF16 张量运算实现高效的硬件利用率 训练数据:基于 Qwen2.5-32B,并在 OpenMathReasoning 数据集(一个包含数学奥林匹克竞赛和标准化考试难题的精选语料库)上进行了大规模微调。
性能表现:
在美国数学邀请赛 (AIME) 2024 和 2025 中,实现了 78.4% 的 pass@1 准确率,并通过多数投票机制达到了 93.3% 的准确率。 在哈佛-麻省理工学院数学竞赛 (HMMT) 2024-25 中表现出色,在多项基准测试中均取得了最先进的结果。
三种推理模式:
思维链 (CoT):通过生成中间推理步骤来提高透明性,在 AIME24 上实现了 76.5% 的 pass@1 准确率。 工具集成推理 (TIR):结合外部工具进行验证和增强,在 AIME24 上达到 78.4% 的 pass@1 准确率。 生成式解选择 (GenSelect):通过生成多个候选解决方案并选择最一致的答案,准确率进一步提升至 93.3%。
这些配置使 OpenMath-Nemotron-32B 能够灵活适应不同的应用场景,既满足研究环境中对解释性的需求,也适合生产环境中对速度和可靠性的要求。
2. OpenMath-Nemotron-14B-Kaggle:高效且高精度的轻量级模型
参数规模:148 亿个参数 训练数据:针对 AIMO-2 Kaggle 竞赛的特定子集进行了针对性微调,以优化其在竞赛中的表现。
性能表现:
在 AIME24 基准测试中,实现了 73.7% 的 pass@1 准确率,并通过 GenSelect 协议提高到 86.7%。 在 AIME25 和 HMMT-24-25 基准测试中,分别达到了 57.9% 和 50.5% 的 pass@1 准确率,并在多数投票机制下进一步提升至 73.3% 和 64.8%。
尽管参数规模较小,但 OpenMath-Nemotron-14B-Kaggle 在资源受限或推理延迟是关键因素的场景中表现出色,成为 AIMO-2 Kaggle 竞赛中排名第一的解决方案。
开源管道与框架支持
OpenMath-Nemotron 系列附带一个完整的开源管道,允许研究人员和开发者重现数据生成、训练过程和评估协议。这些工作流程已集成到英伟达的 NeMo-Skills 框架 中,为以下推理模式提供参考实现:
思维链 (CoT) 工具集成推理 (TIR) 生成式解选择 (GenSelect)
此外,英伟达还提供了示例代码片段,帮助开发者快速构建应用程序原型,例如查询模型以获取逐步解决方案或简化的最终答案。
硬件优化与部署支持
两款模型均经过优化,可在英伟达 GPU 架构(从 Ampere 到 Hopper 微架构)上高效运行,利用以下技术实现低延迟和高吞吐量:
BF16 张量运算:在数值精度和内存占用之间取得平衡,确保大规模模型能够在 GPU 内存限制内运行。 CUDA 库和 TensorRT:通过高度优化的库加速推理过程。 Triton Inference Server:支持在 Web 服务或批处理管道中实现低延迟、高吞吐量的部署。
潜在应用与未来方向
OpenMath-Nemotron 系列的推出为多个领域带来了新的可能性,包括:
AI 驱动的辅导系统:为学生提供个性化的数学学习支持。 学术竞赛准备工具:帮助参赛者练习和提高数学解题能力。 科学计算工作流程:将形式化或符号推理集成到复杂的科学研究中。
未来的研究可能会扩展到更高级的大学水平数学、支持多模态输入(如手写方程式)以及与符号计算引擎的深度集成,以验证和增强生成的解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











