ComfyUI官方宣布,高性能音频驱动视频生成模型Wan2.2-S2V已实现原生适配——无需额外插件,即可直接在ComfyUI中调用该模型,将静态图片与音频结合,生成对话、唱歌、角色表演等动态视频内容。无论是追求电影级画质,还是需要分钟级长视频创作,这个工作流都能满足多场景需求。

本文将从“模型亮点”“资源准备”“分步操作”三个维度,详细拆解Wan2.2-S2V在ComfyUI中的使用流程,帮你快速上手音频驱动视频生成。
- Hugging Face:https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged
- 魔塔:https://www.modelscope.cn/models/Comfy-Org/Wan_2.2_ComfyUI_Repackaged
- GGUF版:https://www.modelscope.cn/models/QuantStack/Wan2.2-S2V-14B-GGUF
国内用户请从魔塔下载所需模型,显存不足的用户可下载GGUF版本模型
Wan2.2-S2V模型的核心优势
在开始操作前,先明确该模型的核心能力,以便根据需求调整参数:
- 音频驱动精准同步:能将音频的节奏、语调与静态图片中的角色动作、表情联动,比如让角色“开口说话”的口型匹配语音,或让动作跟随音乐节拍;
- 画质与效率兼顾:生成视频具备电影级细节(如自然的面部表情、流畅的肢体动作),同时支持“分钟级”长视频输出,避免传统模型“短片段、低效率”的问题;
- 多场景适配:既支持半身角色(如主播、虚拟人),也能生成全身角色视频,还可通过文本指令额外控制动作风格(如“优雅地挥手”)或环境氛围(如“暖色调室内场景”);
- 显存友好:提供不同精度的模型版本,低显存设备也能流畅运行,无需高端GPU即可尝试。
前期准备:下载工作流与所需模型
要运行Wan2.2-S2V工作流,需先获取“工作流文件”和“四类核心模型”,所有资源均来自官方渠道,确保兼容性:
1. 下载官方工作流文件
无需手动搭建节点,直接加载官方预设模板即可:
- 打开ComfyUI,在“工作流模板库”中搜索“Wan2.2-S2V 原生工作流”(或从ComfyUI官方社区下载对应JSON文件);

2. 下载四类核心模型(附官方仓库链接)
所有模型需放入ComfyUI对应的文件夹中,避免路径错误导致工作流报错。官方仓库地址:点击进入Wan2.2-S2V官方模型仓库,需下载以下四类模型:
| 模型类型 | 模型文件名 | 存放路径 | 核心作用 |
|---|---|---|---|
| Diffusion模型 | wan2.2_s2v_14B_fp8_scaled.safetensors | models/checkpoints | 视频生成的核心模型,FP8精度显存占用低 |
| Diffusion模型 | wan2.2_s2v_14B_bf16.safetensors | models/checkpoints | BF16精度,画质损失更少(显存需求高) |
| 音频编码器 | wav2vec2_large_english_fp16.safetensors | models/audio_encoders | 解析输入音频,提取节奏、语调特征 |
| VAE模型 | wan_2.1_vae.safetensors | models/vae | 优化视频画面细节,减少模糊和噪点 |
| 文本编码器 | umt5_xxl_fp8_e4m3fn_scaled.safetensors | models/text_encoders | 解析文本指令,控制动作、环境等 |
| Lightning LoRA | wan2.2_t2v_lightx2v_4steps_lora _v1.1_high_noise.safetensors | models/loras | 加速生成(4步完成采样),需权衡质量 |
模型选择建议:
- 显存<16GB:优先用
wan2.2_s2v_14B_fp8_scaled.safetensors(FP8精度),搭配Lightning LoRA减少显存占用; - 显存≥24GB:可选
wan2.2_s2v_14B_bf16.safetensors(BF16精度),关闭LoRA以获得最佳画质。
分步操作:Wan2.2-S2V工作流运行全流程
加载工作流和模型后,按以下步骤配置参数、输入素材,即可生成音频驱动视频:
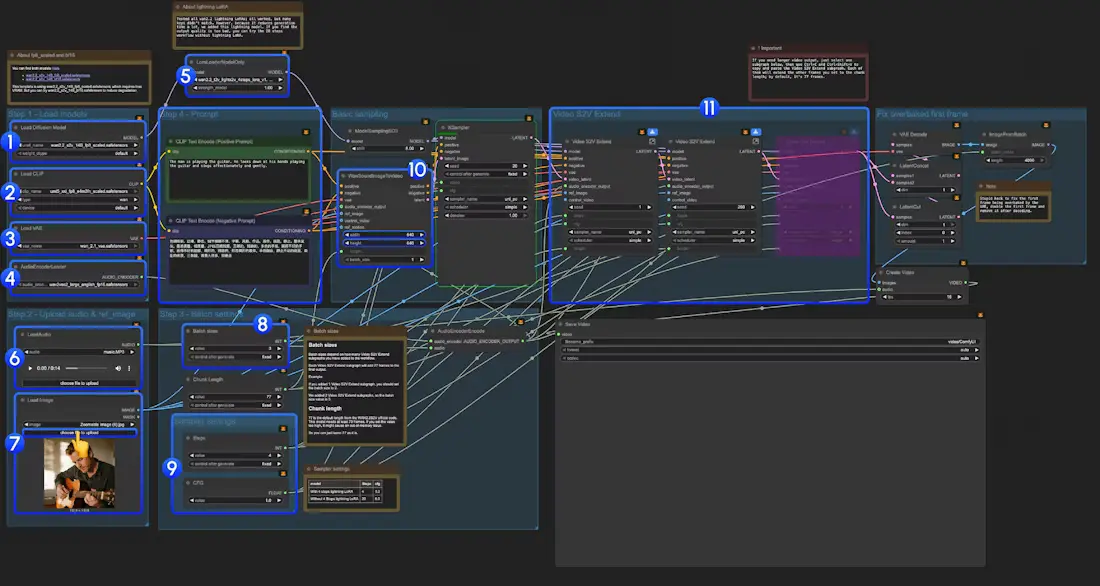
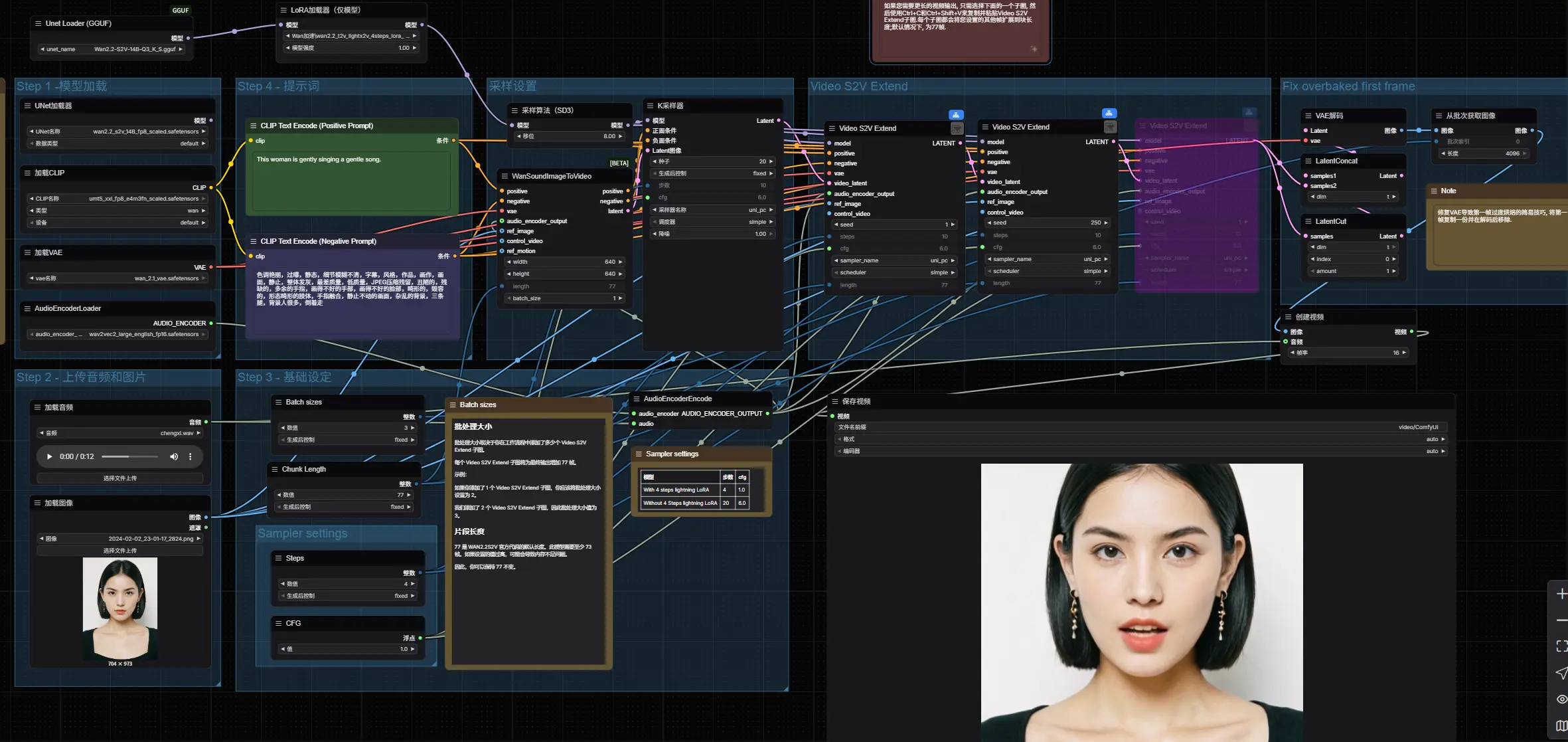
1. 加载核心模型(6个关键节点)
在工作流界面中,找到对应节点,选择已下载的模型文件:
- Load Diffusion Model:点击“模型路径”下拉框,选择
wan2.2_s2v_14B_fp8_scaled.safetensors(或BF16版本); - Load CLIP:选择
umt5_xxl_fp8_e4m3fn_scaled.safetensors(文本编码器); - Load VAE:选择
wan_2.1_vae.safetensors; - AudioEncoderLoader:选择
wav2vec2_large_english_fp16.safetensors; - LoraLoaderModelOnly:若需加速,选择
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors;若追求画质,删除该节点或选择“无”; - LoadAudio:点击“上传”按钮,导入音频文件(支持WAV、MP3格式,建议时长10-30秒,避免过长导致显存不足)。
2. 导入静态图片与设置视频参数
- Load Image:上传作为“视频主体”的静态图片(建议分辨率1024×1024,支持人物、动物等主体,背景简洁更佳);
- Batch sizes(批处理大小):根据“Video S2V Extend子图节点数量”设置,公式为:
批处理大小 = 子图节点数量 + 1(例:2个Extend节点,批处理大小设为3); - Chunk Length(帧块长度):保持默认77(模型固定帧块,无需修改);
- 尺寸设置:在“Video S2V”节点中设置输出分辨率(如512×768,半身角色)或1024×1024(全身角色),建议不超过1024,避免显存溢出。
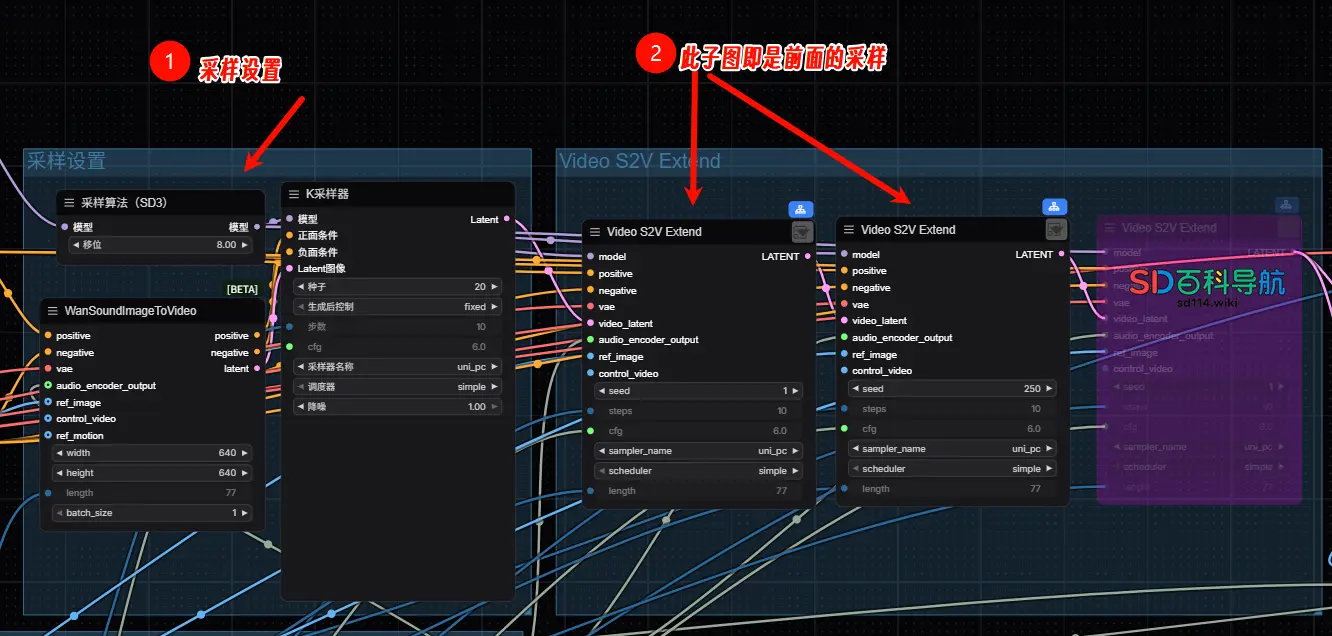

3. 关键配置:Video S2V Extend节点数量(控制视频时长)
该模型默认生成16fps的视频,每个“Video S2V Extend子图节点”可增加77帧,需根据音频时长计算节点数量,确保视频与音频同步:
- 计算公式:
总帧数 = 音频时长(秒)× 16;所需子图节点数量 = 总帧数 ÷ 77(向上取整); - 示例:音频时长14秒 → 总帧数=14×16=224 → 224÷77≈2.9 → 需3个Video S2V Extend子图节点(在工作流中复制节点即可增加)。
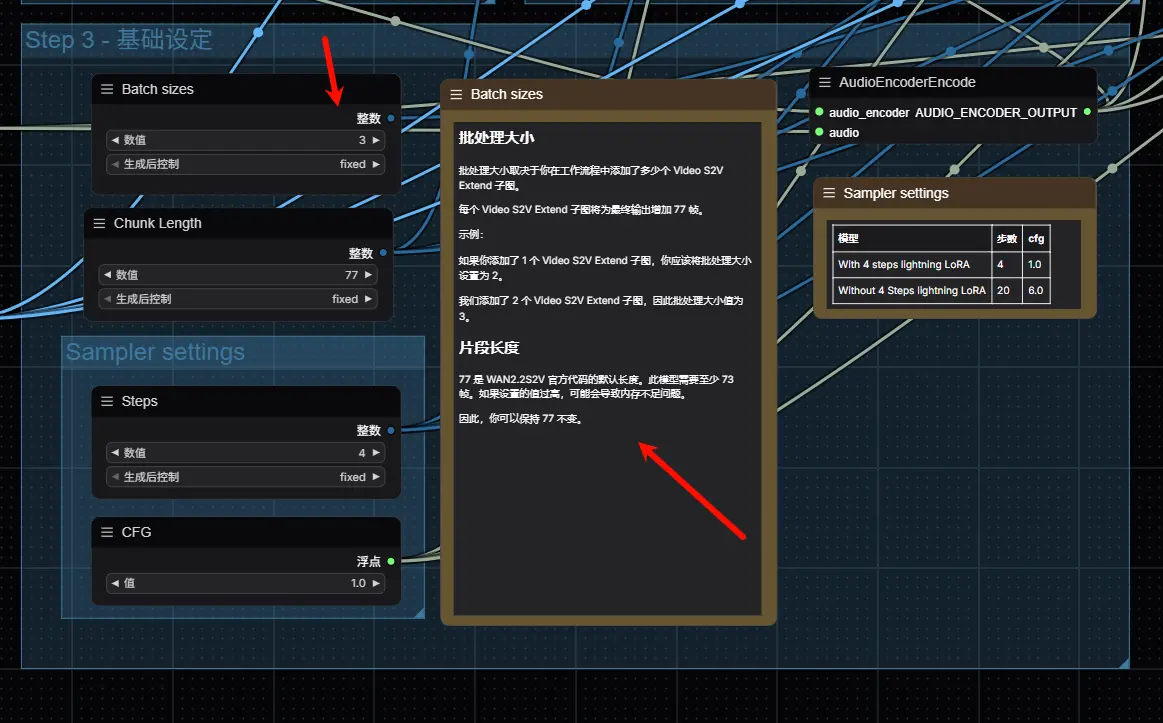
4. 采样器设置(根据是否用LoRA调整)
- 使用Lightning LoRA(4步加速):在“Sampler”节点中设置
steps=4,cfg=1.0( cfg值越低,生成速度越快,受文本指令影响越小); - 不使用LoRA(20步画质优先):设置
steps=20,cfg=6.0( cfg值越高,画面越贴合文本指令,但生成时间更长)。
5. 运行工作流,生成视频
- 点击ComfyUI界面底部的“运行”按钮,或按快捷键
Ctrl+Enter; - 生成过程中,可在“预览”节点查看实时帧画面;生成完成后,视频文件会自动保存到ComfyUI的“output”文件夹(格式为MP4)。
常见问题与优化建议
1. 加载模型时报“路径错误”?
- 检查模型是否放入对应文件夹(如Diffusion模型需在
checkpoints文件夹,LoRA需在loras文件夹); - 重启ComfyUI,让系统重新扫描模型路径。
2. 生成视频画面模糊?
- 切换为BF16精度的Diffusion模型(
wan2.2_s2v_14B_bf16.safetensors); - 关闭Lightning LoRA,用20步采样(steps=20);
- 确保VAE模型加载正确(
wan_2.1_vae.safetensors,避免用默认VAE)。
3. 音频与视频不同步?
- 重新计算“Video S2V Extend子图节点数量”,确保总帧数≥音频时长×16;
- 检查音频文件是否有卡顿、变速,建议用剪辑工具预处理音频(如剪去空白片段)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











