阿里Wan团队正式开源音频驱动视频生成模型Wan2.2-S2V-14B。这款模型打破了传统视频生成对复杂输入的依赖——用户仅需提供一张静态图像与一条音频,即可生成面部表情自然、口型精准同步、肢体动作流畅的电影级数字人视频,且单次生成时长可达分钟级,为数字人直播、影视制作、AI教育等行业的视频创作效率带来显著提升。
- GitHub:https://github.com/Wan-Video/Wan2.2
- Hugging Face:https://huggingface.co/Wan-AI/Wan2.2-S2V-14B
- 魔塔:https://www.modelscope.cn/models/Wan-AI/Wan2.2-S2V-14B
体验地址:
- 通义万相官网:https://tongyi.aliyun.com/wanxiang/generate
- 阿里云百炼:https://bailian.console.aliyun.com/?tab=api#/api/?type=model&url=2978215
- Demo:https://huggingface.co/spaces/Wan-AI/Wan2.2-S2V

核心能力:覆盖多场景,支持多维度控制
Wan2.2-S2V-14B的核心优势在于“低门槛输入、高灵活适配”,能应对不同类型主体、画幅与创作需求,具体能力可概括为三点:
1. 多主体+多画幅,适配全场景
模型不局限于单一主体类型,可驱动真人、卡通形象、动物、数字人等各类静态图像;同时支持肖像、半身、全身等任意画幅,无论是短视频中的人物特写,还是影视场景中的全身表演,都能精准适配。
2. 音频驱动+文本控制,创作更自由
- 音频驱动核心:上传音频后,模型可让图像主体完成说话、唱歌、表演等动作,且口型、表情与音频节奏高度同步;
- 文本控制拓展:输入Prompt(文本提示)即可进一步控制视频画面,例如调整主体运动轨迹、优化背景动态变化,让视频内容更丰富。
3. 分钟级长视频,满足工业化需求
区别于多数模型“秒级生成”的局限,Wan2.2-S2V-14B通过技术优化实现稳定的分钟级视频生成,可直接应用于数字人直播(如长时间虚拟主播带货)、影视片段制作(如短剧情内容)等工业化场景。
举个实例:若上传一张人物弹钢琴的照片、一段歌曲音频,再搭配“镜头缓慢推进,背景呈现暖光舞台效果”的文本提示,模型能生成一段完整的钢琴演奏视频——人物形象与原图完全一致,面部表情、嘴部动作与歌曲同步,手指的手型、按键力度、弹奏速度也能精准匹配音频节奏,实现“声情并茂”的效果。
技术解析:三大关键设计,撑起高性能表现
Wan2.2-S2V-14B的优秀表现,源于底层技术架构与训练策略的精心设计,核心可拆解为三部分:
1. 混合控制架构:音频细控+文本全局,兼顾精度与灵活
模型基于通义万相视频生成基础模型,融合两种核心控制机制:
- 音频驱动细粒度局部运动:通过Wav2Vec提取音频特征,再结合AdaIN(自适应实例归一化)和CrossAttention(交叉注意力)机制,让音频信号精准控制主体的口型、表情、肢体小动作(如手指按键、头部随节奏晃动);
- 文本引导全局运动:文本Prompt负责调控全局动态,如镜头平移/缩放、背景变化、主体整体运动轨迹(如钢琴演奏者身体的轻微前倾),实现“局部精准、全局协调”的效果。
2. 长视频优化技术:73帧历史参考帧,解决稳定性难题
为避免长视频生成中的“画面抖动、主体形变”,模型引入层次化帧压缩技术:
- 传统模型受限于计算负载,历史参考帧(motion frames)通常仅为数帧;
- 该技术通过压缩历史帧的Token数量,将历史参考帧长度拓展至73帧,大幅提升长视频的运动连贯性与画面稳定性。
3. 大规模训练策略:60万+数据集+混合并行,挖掘模型潜力
- 数据基础:构建超60万个片段的音视频数据集,覆盖真人、卡通、数字人等多场景,确保模型泛化能力;
- 训练方式:采用FSDP(全分片数据并行)+上下文并行的混合并行策略,支持全参数化训练,充分释放模型性能;
- 多阶段优化:分“音频处理模块预训练→全数据集预训练→高质量数据微调”三阶段训练,同时支持多分辨率训练与推理,可适配竖屏短视频(如9:16)、横屏影视剧(如16:9)等不同需求。
性能验证:核心指标同类最优,定性表现更胜一筹
无论是定量数据还是定性效果,Wan2.2-S2V-14B都展现出同类模型中的领先水平:
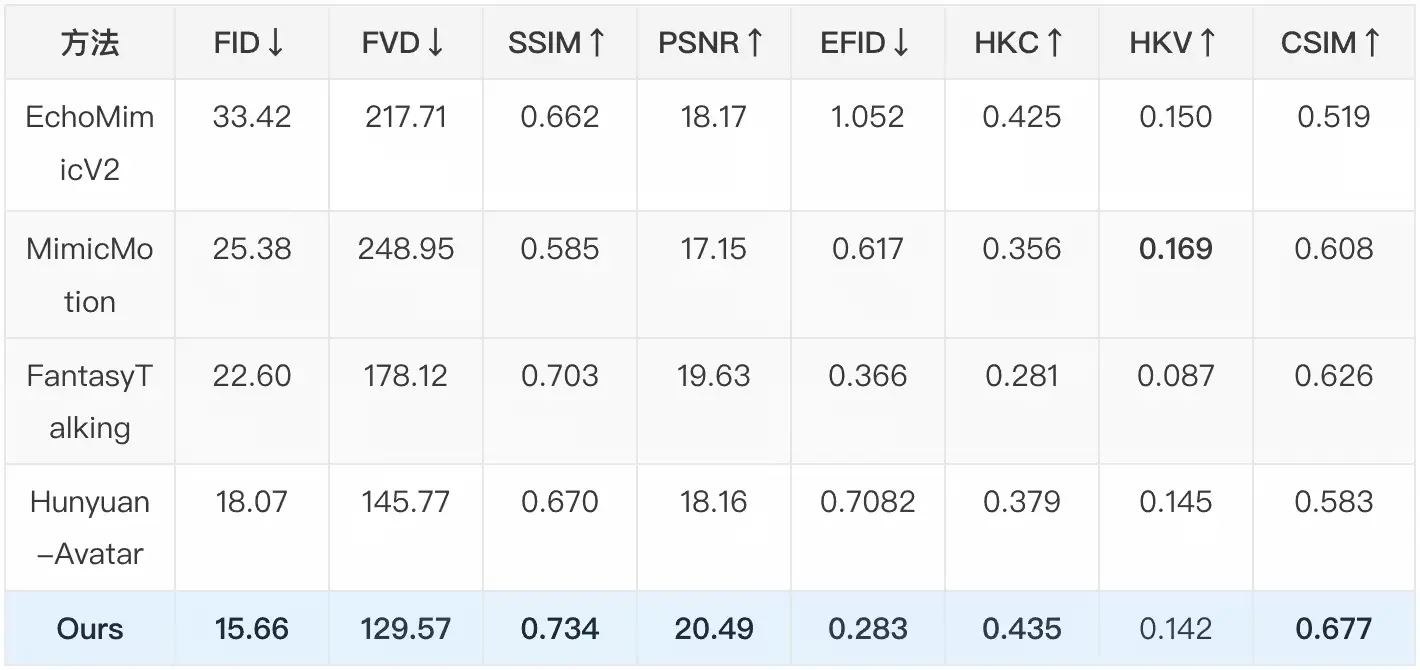
1. 定量指标:三大核心维度表现优异
在FID(视频质量,数值越低越好)、EFID(表情真实度,数值越低越好)、CSIM(身份一致性,数值越高越好)等关键指标上,模型取得同类最优成绩。具体在EMTD数据集上的测试结果如下:
| 指标 | 数值 | 指标说明 |
|---|---|---|
| FID | 15.66 | 视频质量,越低越接近真实 |
| EFID | 0.283 | 表情真实度,越低越自然 |
| CSIM | 0.677 | 身份一致性,越高越贴合原图 |
| FVD | 129.57 | 视频帧间一致性,越低越稳定 |
| SSIM | 0.734 | 结构相似性,越高画面越连贯 |
| PSNR | 20.49 | 峰值信噪比,越高画质越清晰 |
| Sync-C | 4.51 | 口型同步度,数值越优越同步 |
| HKC | 0.435 | 手部动作一致性,越高越精准 |
| HKV | 0.142 | 头部动作一致性,越高越自然 |
2. 定性对比:表达性与真实性领先
与Ominihuman、Hunyuan-Avatar等主流音频驱动视频生成模型相比,Wan2.2-S2V-14B的优势主要体现在两点:
- 身份一致性更强:即使在动态运动(如肢体大幅度摆动、表情夸张变化)中,也能保持主体形象与原图高度一致,避免“形变”问题;
- 运动范围更广泛:可支持更复杂的动作生成(如钢琴演奏的手指精细动作、唱歌时的肢体配合),表达性更丰富。
开源生态:通义万相持续发力,下载量超2000万
阿里云表示,自今年2月起,通义万相已陆续开源文生视频、图生视频、首尾帧生视频、全能编辑、音频生视频等多款模型,形成覆盖多场景的视频生成开源矩阵。截至目前,这些模型在开源社区与第三方平台的累计下载量已超2000万,为开发者提供了丰富的视频生成技术工具。
此次Wan2.2-S2V-14B的开源,进一步完善了“音频驱动”这一关键场景的能力,不仅降低了数字人视频、影视片段等内容的创作门槛,也为AI视频生成技术的工业化应用提供了新的可能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











