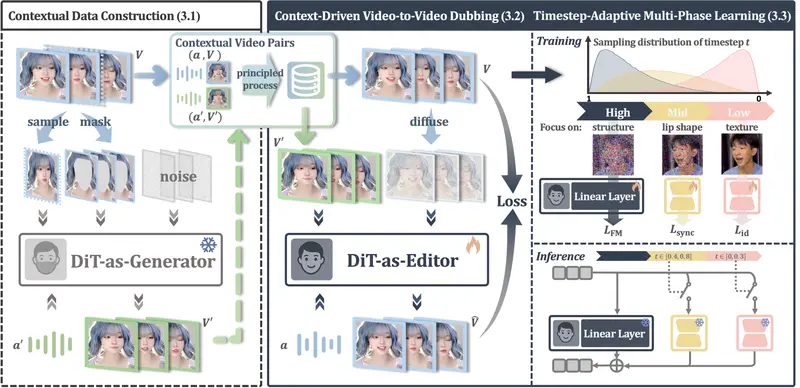
新X-Dub:告别“面具式”配音,AI 让视频唇同步更自然逼真在影视翻译、虚拟人互动和短视频创作中,音频驱动的视觉配音(Visual Dubbing)技术至关重要。然而,传统方法长期受困于一个核心难题:缺乏完美的成对训练数据(即除了嘴型不同,其他完全一致的视频...视频模型# X-Dub# 数字人# 配音3天前0110
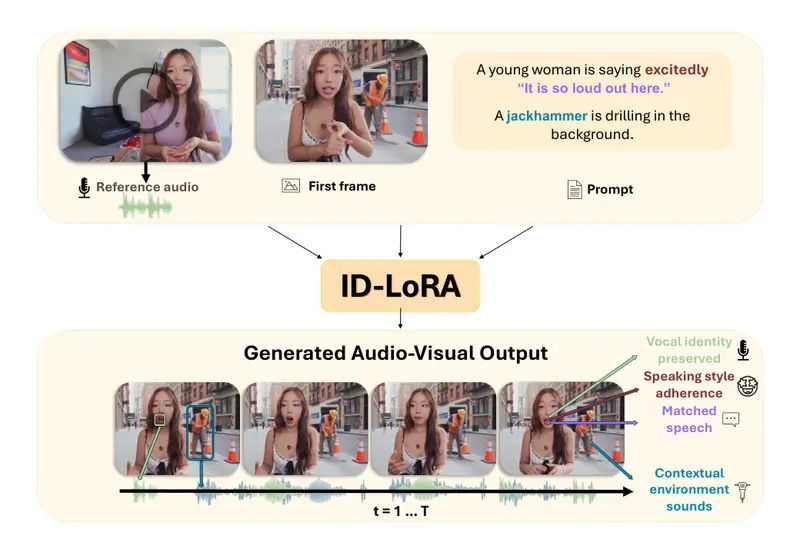
ID-LoRA:让AI同时“克隆”你的长相和声音,还能配合场景表演你有没有想过,如果AI能根据一张照片和一段声音,就能生成一个“数字分身”,让这个分身在任何场景中说话、表演,而且声音和口型都能完美匹配,这会带来什么可能? 这正是特拉维夫大学等研究机构最新发布的 ID...视频模型# ID-LoRA# 数字人2周前0280
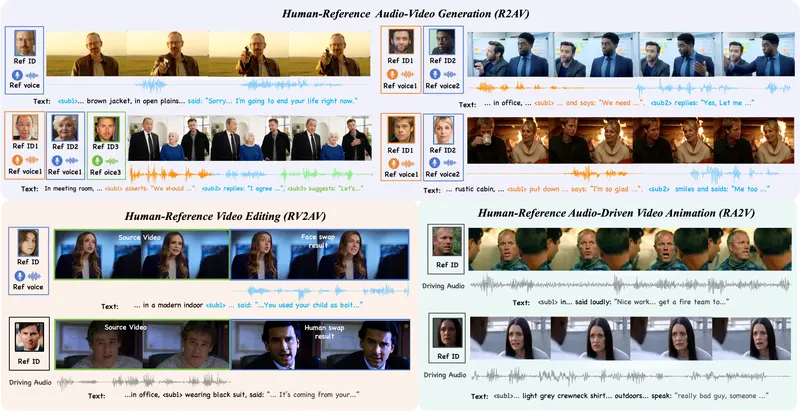
虚拟数字人项目DreamID-Omni:清华&字节联合发布统一框架,一人一模型搞定“换脸、变声、让照片说话”想象一下:你上传一张爱因斯坦的照片和一段录音,AI 就能生成他在办公室里发表演讲的完整视频,口型完美匹配,声音惟妙惟肖;或者,你想把电影片段中的主角换成自己,连声音也一并替换,动作表情却原汁原味。 这...视频模型# DreamID-Omni# 数字人1个月前0870
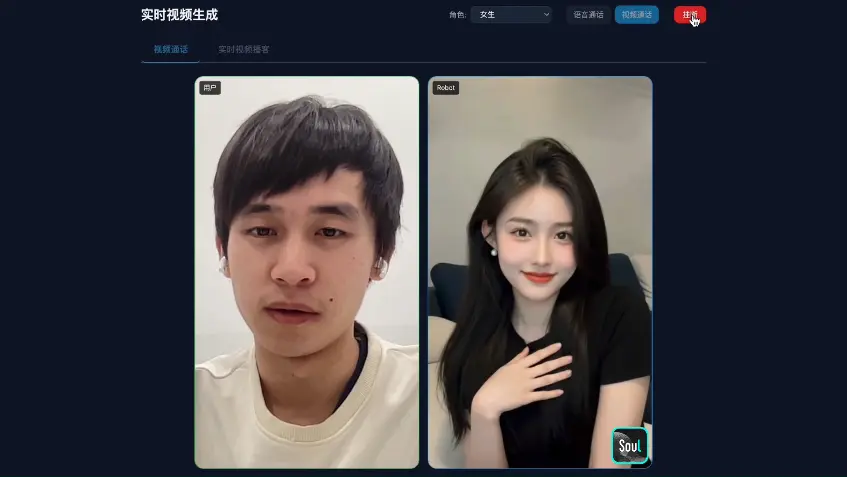
Soul AI Lab推出SoulX-FlashTalk :140 亿参数模型实现 0.87 秒启动、32 FPS 实时数字人直播当前 AI 数字人技术面临一个根本矛盾:高保真生成与实时性难以兼得。顶尖模型虽能生成逼真口型与表情,但因依赖多步迭代去噪,生成一秒钟视频常需数秒甚至更久,无法用于视频通话、直播带货等实时交互场景。更严...视频模型# Soul AI Lab# SoulX-FlashTalk# 数字人2个月前0310
InteractAvatar:文本驱动的可控说话化身框架,实现高保真场景化人-物交互清华大学联合腾讯混元项目组研发的InteractAvatar,是一款创新的双流DiT(扩散变换器)框架,首次让说话虚拟化身突破简单手势局限,实现基于静态场景的文本驱动可控人-物交互。该模型能从参考图像...视频模型# InteractAvatar# 数字人2个月前0560
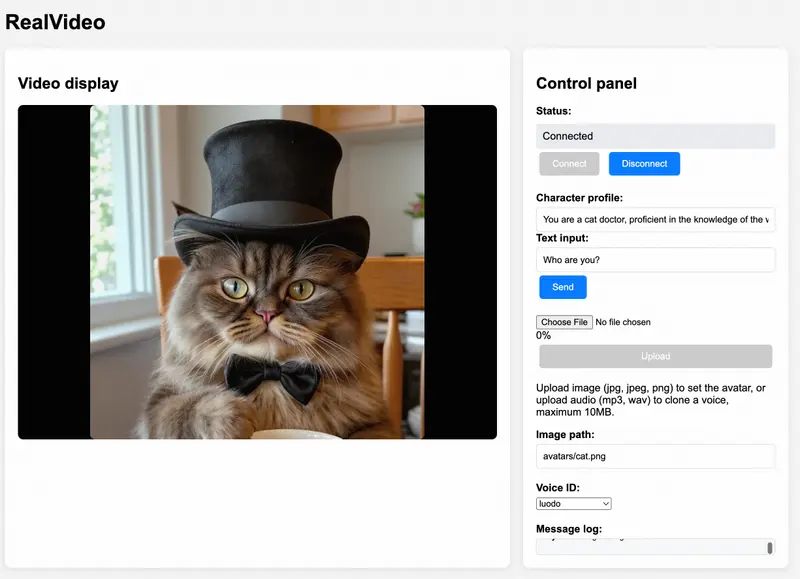
智谱AI开源 RealVideo:基于自回归扩散的实时流式对话视频系统随着多模态生成技术的发展,用户对虚拟角色的期待已从“能说话”升级为“能自然表达、实时互动、持续存在”。为此,智谱AI推出了 RealVideo —— 一个端到端实时流式视频对话系统,能够将文本对话实时...视频模型# RealVideo# 数字人# 智谱AI4个月前01870
阿里开源 Wan2.2-S2V-14B:输入一张图 + 一段音频,生成电影级数字人视频阿里Wan团队正式开源音频驱动视频生成模型Wan2.2-S2V-14B。这款模型打破了传统视频生成对复杂输入的依赖——用户仅需提供一张静态图像与一条音频,即可生成面部表情自然、口型精准同步、肢体动作流...视频模型# Wan2.2-S2V-14B# 数字人# 阿里7个月前05380
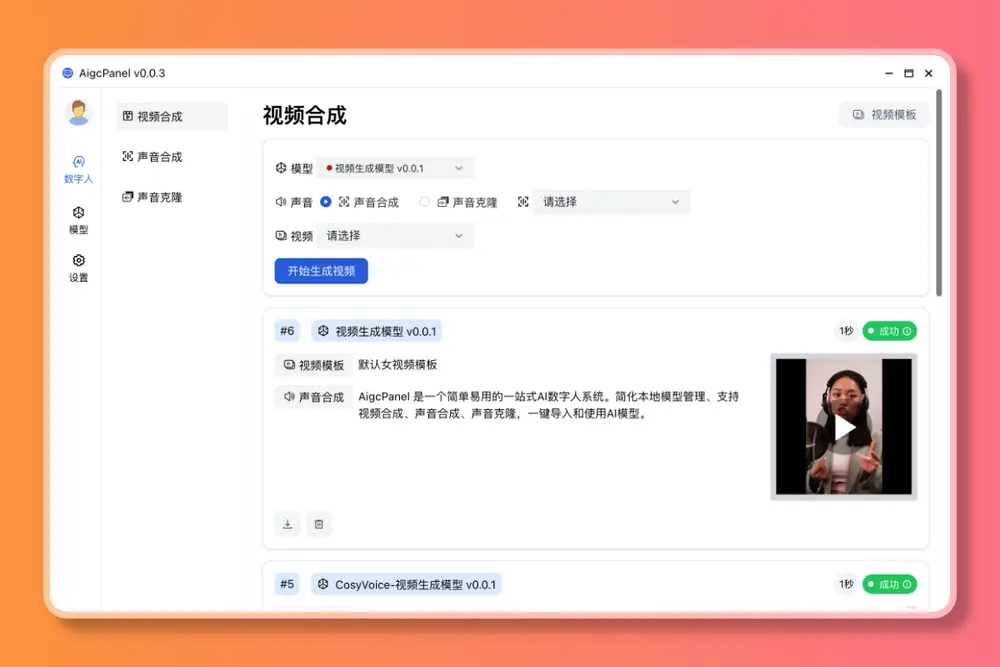
一站式 AI 数字人生成软件AigcPanel:基于阿里开源语音生成模型CosyVoice和腾讯开源视频生成模型的MusePose打造AigcPanel 是一个基于阿里开源的语音生成模型CosyVoice和腾讯开源视频生成模型MusePose的一站式 AI 数字人生成软件,支持视频合成、声音合成、声音克隆,简化本地模型管理、一键导入...工具# AigcPanel# CosyVoice# MusePose1年前04490