
当前 AI 数字人技术面临一个根本矛盾:高保真生成与实时性难以兼得。顶尖模型虽能生成逼真口型与表情,但因依赖多步迭代去噪,生成一秒钟视频常需数秒甚至更久,无法用于视频通话、直播带货等实时交互场景。更严峻的是,长时间运行易导致画面退化、身份漂移或动作失真。
- 项目主页:https://soul-ailab.github.io/soulx-flashtalk
- GitHub:https://github.com/Soul-AILab/SoulX-FlashTalk
- 模型:https://huggingface.co/Soul-AILab/SoulX-FlashTalk-14B
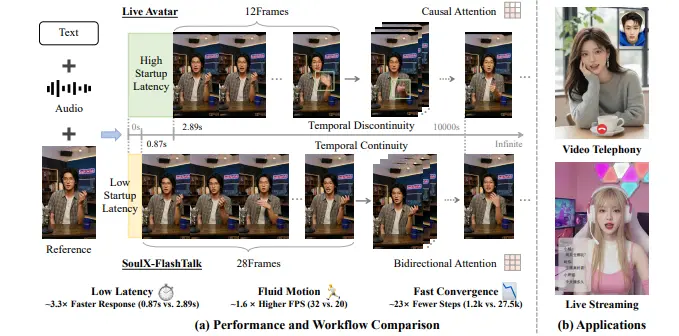
Soul AI Lab 推出 SoulX-FlashTalk——一个专为高保真流式传输优化的 140 亿参数系统。它首次在百亿级模型上实现 0.87 秒启动延迟 与 32 FPS 实时吞吐量,支持无限时长直播,且画质不随时间衰减。
核心突破:双向流式蒸馏 + 自校正机制
保留块内双向注意力
传统流式模型为追求低延迟,强制采用单向注意力(仅看历史帧),导致动作僵硬、手势缺失。SoulX-FlashTalk 创新性地保留块内双向注意力:在生成每一小段视频时,模型可同时访问该段内的前后帧,如同演员在说台词时已预演下一句的表情与手势,从而实现自然连贯的全身动作。
多步回顾自校正机制
为确保长期稳定性,系统引入多步回顾自校正机制:AI 在生成过程中持续回溯先前输出,检测身份漂移或结构失真,并主动修正。这使得即使连续运行 1000 秒,面部几何与背景细节仍保持清晰稳定,避免“越播越糊”的常见问题。
极简高效训练流程
得益于架构设计,SoulX-FlashTalk 的训练流程大幅简化:
- 第一阶段:1000 步监督微调,适应低分辨率实时场景
- 第二阶段:200 步蒸馏,学习快速生成策略
- 总计仅 1200 步,相比 LiveAvatar(27,500 步)效率提升 23 倍
主要功能与规格
| 功能 | 说明 |
|---|---|
| 实时音频驱动 | 输入语音,实时生成口型、表情与全身动作 |
| 无限时长直播 | 理论无时长限制,长期运行画质不衰减 |
| 低延迟启动 | 首帧生成仅需 0.87 秒 |
| 高画质输出 | 分辨率 720×416,动作流畅自然 |
| 身份一致性 | 基于单张参考图,全程保持人物样貌统一 |
| 中文语音优化 | 精准处理“上”“突”“法”等复杂发音 |
全栈硬件加速
为支撑 140 亿参数模型的实时推理,团队构建了端到端优化栈:
- 8×H800 GPU 并行:任务分片处理
- FlashAttention 技术:加速注意力计算
- 并行视频编解码:消除 VAE 瓶颈
- 代码级流水线优化:减少同步等待
端到端延迟实测(8×H800):
- 核心生成(DiT):154ms
- 视频解码(VAE):187ms
- 运动编码:14ms
- 总循环延迟:876ms(满足 <1 秒实时要求)
性能对比:全面超越现有方案
定量结果(实时系统中 SOTA)
| 方法 | 美学评分↑ | 图像质量↑ | 口型同步↑ | 帧率 (FPS) |
|---|---|---|---|---|
| Ditto | 3.10 | 4.37 | 1.04 | 21.80 |
| LiveAvatar | 3.10 | 3.25 | 1.01 | 20.88 |
| SoulX-FlashTalk | 3.51 | 4.79 | 1.47 | 32.00 |
注:非实时方法(如 EchoMimic-V3)帧率仅 0.53 FPS,无法用于直播。
定性优势
- 短期生成(5秒):手势清晰自然,无变形或过曝
- 长期稳定性(1000秒):面部结构与背景细节无退化
- 中文口型精度:复杂发音嘴型与真实视频高度一致
局限与未来方向
- 硬件门槛高:当前需 8 块 H800 GPU
- 分辨率待提升:720×416 有优化空间
未来工作将聚焦于:
- 模型压缩与量化,适配消费级显卡
- 注意力机制进一步轻量化
- 推动实时高保真数字人进入普通开发者与创作者工作流
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











