高丽大学、Adobe Research 与 KAIST AI 联合提出 VideoMaMa(Video Mask-to-Matte Model),一种基于 Stable Video Diffusion 的视频抠图新方法,专门解决从粗糙二进制掩码 → 高精度、时序连贯、带半透明细节的 Alpha Matte 这一核心难题。
- 项目主页:https://cvlab-kaist.github.io/VideoMaMa
- GitHub:https://github.com/cvlab-kaist/VideoMaMa
- 模型:https://huggingface.co/SammyLim/VideoMaMa
- Demo:https://huggingface.co/spaces/SammyLim/VideoMaMa
它不仅在多项基准上刷新 SOTA,还构建了目前规模最大的真实视频抠图数据集 MA-V,为整个视频抠图领域从“合成数据”走向“真实场景”提供了关键支撑。
研究背景与核心痛点
视频抠图(Video Matting)是影视后期、直播、虚拟背景、内容创作的基础技术,目标是提取带透明度的前景物体,保留发丝、绒毛、运动模糊、半透明边缘等精细结构。
传统方法面临三大瓶颈:
- 高质量 Alpha 数据极度稀缺:必须绿幕/专业设备拍摄,成本高、规模小。
- 合成→真实域差距巨大:多数模型在合成数据训练,真实场景光照、模糊、时序一致性都不自然。
- 粗糙掩码无法直接用:SAM2 等分割模型只能输出硬边界掩码,缺少透明度与细节。
VideoMaMa 的核心定位:
- 输入:任意粗糙掩码(下采样、多边形、SAM2 输出等)
- 输出:时序一致、像素精确、含半透明细节的视频 Alpha 遮罩
核心思路:用扩散先验“补全”真实细节
VideoMaMa 不依赖复杂迭代去噪,而是直接复用预训练视频扩散模型(SVD)的强大生成先验,让模型“脑补”出真实世界的半透明区域、毛发细节、运动模糊。
典型例子:
- 输入:SAM2 给出的蒲公英粗糙掩码
- 输出:VideoMaMa 恢复每根绒毛的透明度与时序连贯性
它能处理:头发、胡须、羽毛、纱质、透明物体、高速运动模糊等传统方法极易失败的场景。

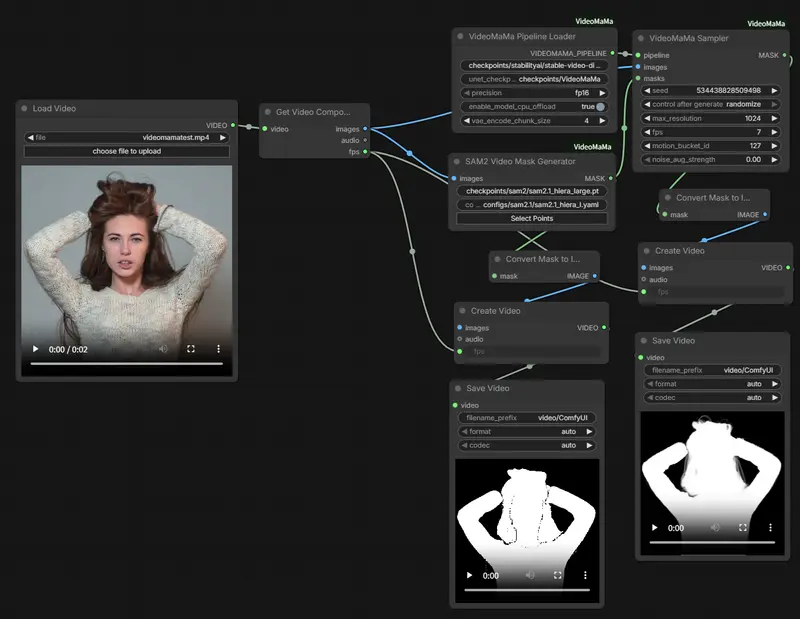
模型架构与关键技术
1. 基于 Stable Video Diffusion 的单步推理架构
- 直接在 SVD 隐空间做 mask → matte 转换
- 单步预测,无需多步去噪,速度远优于常规扩散抠图
- 输入:RGB 帧 + 二进制掩码 + 噪声
- 输出:高精度 Alpha 隐空间表示 → 解码为最终遮罩
2. 两阶段训练(兼顾高分辨率细节 + 时序一致性)
- 阶段1(空间层):冻结时序模块,在 1024×1024 单帧训练,学习像素级精细边缘。
- 阶段2(时序层):冻结空间模块,在低分辨率 3 帧视频训练,保证运动连贯、不闪烁。
3. 掩码增强(Mask Augmentation)
强制模型不能只抄输入掩码,必须从图像推理真实结构:
- 多边形退化:用粗糙多边形逼近边界
- 下采样退化:大幅降采样再上采样,抹除高频信息
- 让模型在极粗糙输入下仍能恢复精细 Matte
4. 语义知识注入(DINOv3)
- 提取 DINOv3 语义特征注入 SVD 解码器
- 提升复杂结构、重叠物体、关节类目标的边界一致性
5. MA-V:首个大规模真实视频抠图数据集
- 50,541 个真实视频(现有真实数据集的近 50 倍)
- 自然前景+背景,非合成粘贴
- 可显著提升真实场景泛化能力
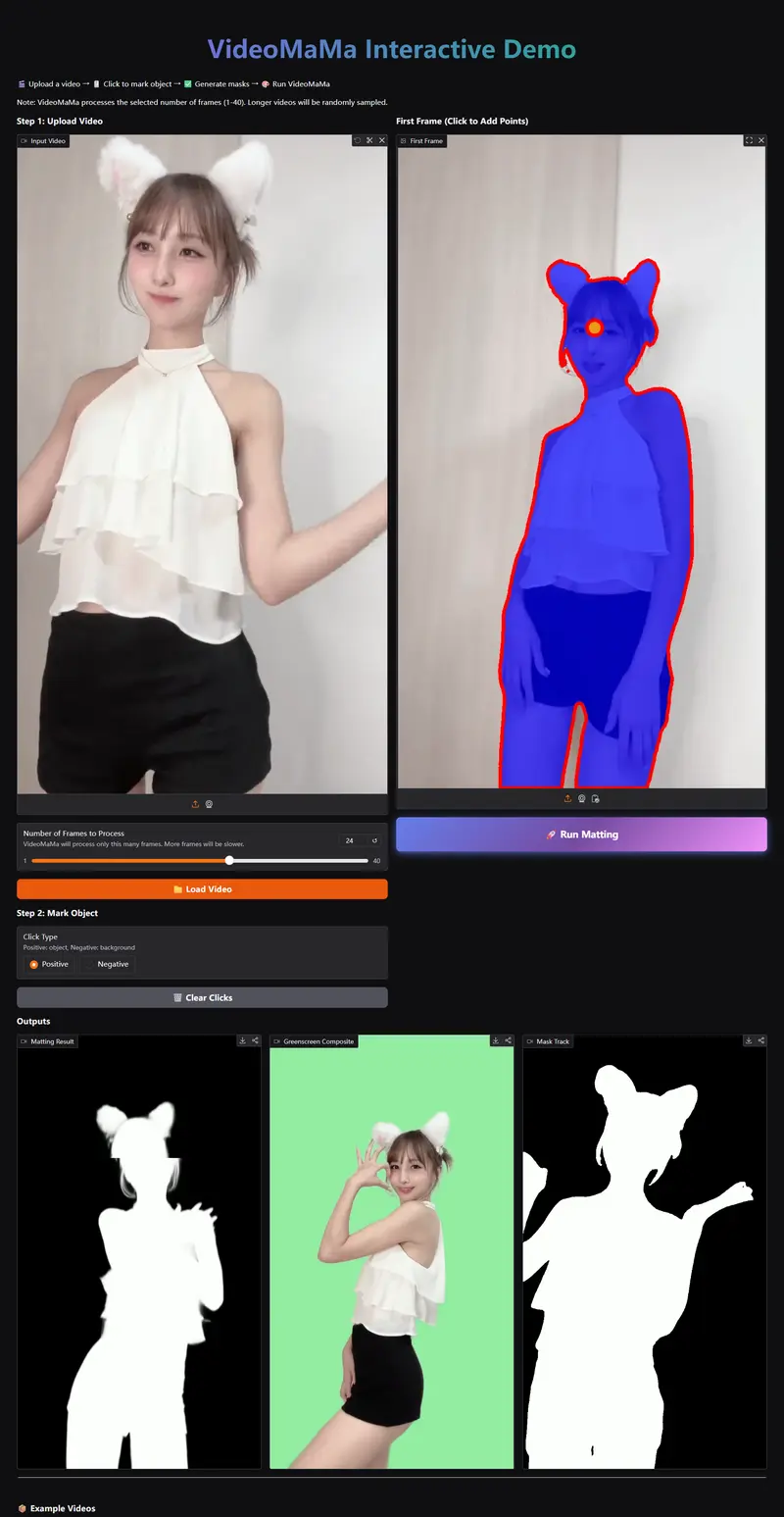
主要功能与模式
- Mask-to-Matte 核心转换
粗糙掩码 → 精细 Alpha 遮罩 - 零样本真实视频泛化
仅合成数据训练,真实场景依然超强 - 两大工作模式
- 全帧掩码引导(all-frame mask-guided)
- 首帧掩码引导(first-frame mask-guided)+ 时序传播
- 大规模伪标签生成引擎
为无标注视频自动生成高质量抠图数据
实验结果:全面超越现有 SOTA
1. 全帧掩码引导(V-HIM60 / YouTubeMatte 1080P)
无论输入掩码质量如何(8×下采样、32×下采样、多边形、SAM2),VideoMaMa 在 MAD、Grad 等关键指标均大幅领先 MGM、MaGGIe 等方法。
尤其在极粗糙掩码下,优势更加明显。
2. 首帧掩码引导(仅第一帧标注)
SAM2-Matte(VideoMaMa + MA-V 微调) 显著超越 SAM2 原生、MatAnyone,实现长时间跟踪不漂移、细节稳定。
3. 消融关键结论
- 两阶段训练 + DINOv3 = 最优性能
- 仅用 MA-V 训练即可超越传统 SOTA
- 纯合成数据集反而带来域偏移,真实场景性能下降
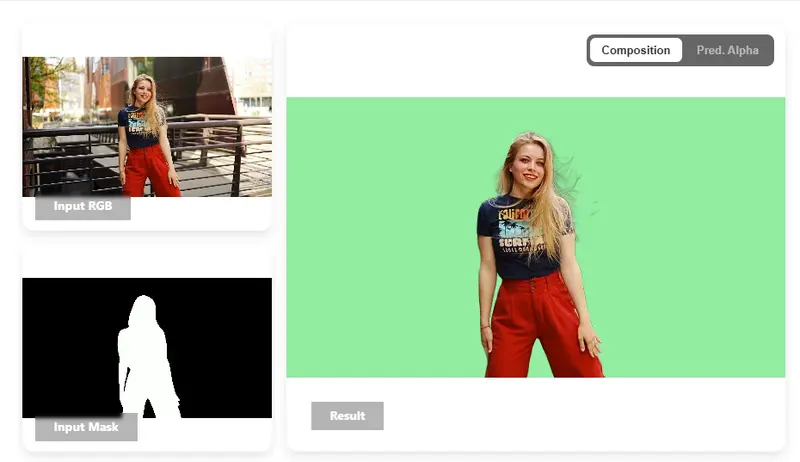
4. 定性效果
- 毛发、绒毛、透明织物、运动模糊全面领先
- 时序更稳定、无闪烁、边缘更自然
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











