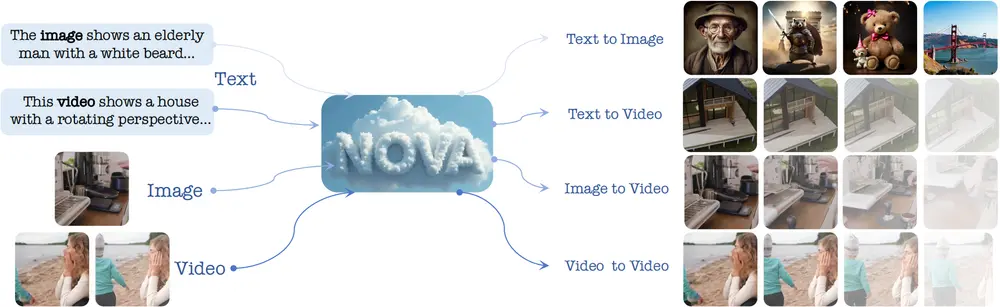
中山大学深圳校区、美团和香港科技大学的研究人员推出用于音频驱动的多人对话视频生成的新框架 MultiTalk,该框架能够根据多路音频输入和提示生成包含互动的视频,同时确保唇部动作与音频同步。
- 项目主页:https://meigen-ai.github.io/multi-talk
- GitHub:https://github.com/MeiGen-AI/MultiTalk
- 模型:https://huggingface.co/MeiGen-AI/MeiGen-MultiTalk
现有的音频驱动人类动画方法主要集中在单人动画生成,无法处理多路音频输入,且在遵循复杂指令生成视频时表现不佳。MultiTalk 则旨在解决这些问题,支持多人对话视频生成,具有广泛的应用前景。
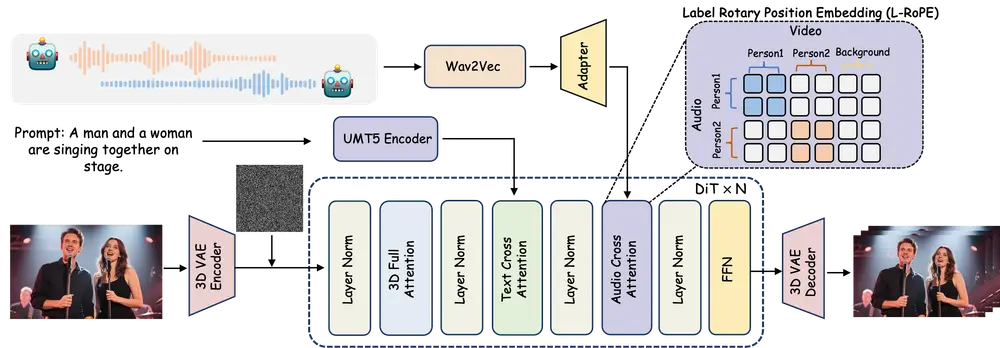
主要功能
- 多人对话视频生成:能够根据多路音频输入生成包含多人互动的视频。
- 音频与人物绑定:通过 Label Rotary Position Embedding (L-RoPE) 方法解决多音频流与人物的正确绑定问题。
- 指令遵循能力:在生成视频时能够准确遵循文本提示中的指令,生成符合要求的视频内容。
主要特点
- 音频注入策略:提出 L-RoPE 方法,有效解决多音频流与人物绑定问题,确保每个音频流只驱动相应的人物。
- 训练策略:采用部分参数训练和多任务训练策略,保留基础模型的指令遵循能力,尤其在计算资源和数据有限的情况下效果显著。
- 长视频生成:通过自回归方法实现长视频生成,支持更长时间的视频内容生成。
工作原理
- 视频扩散模型:采用基于 DiT(Diffusion-in-Transformer)架构的视频扩散模型,结合 3D 变分自编码器(VAE)实现视频生成。
- 音频交叉注意力机制:通过音频交叉注意力机制将音频条件整合到视频生成过程中,使视频帧与音频同步。
- L-RoPE 方法:通过为视频和音频嵌入分配标签,激活音频交叉注意力图中的特定区域,从而实现多音频流与人物的正确绑定。
- 自适应人物定位:利用自注意力图自适应定位视频中的每个人物,确保音频驱动的正确性。
- 训练策略:分为两个阶段,第一阶段训练单人动画能力,第二阶段使用双音频流数据训练多人动画能力。采用部分参数训练和多任务训练策略,保留模型的指令遵循能力。
测试结果
- 定量评估:在多个数据集上进行评估,包括单人对话头和对话身体数据集。MultiTalk 在多个指标上优于现有方法,特别是在唇部同步和视频质量方面表现出色。
- 定性评估:通过可视化结果展示 MultiTalk 在遵循复杂指令生成视频方面的优势,生成的视频更符合文本提示的要求,且质量更高。
- 多音频流与单音频流对比:多音频流训练的模型在性能上与单音频流训练的模型相当,表明多音频流训练不会导致模型性能下降。
- L-RoPE 标签选择:不同的标签选择对 L-RoPE 的效果影响不大,表明该方法对标签范围的选择不敏感。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...