
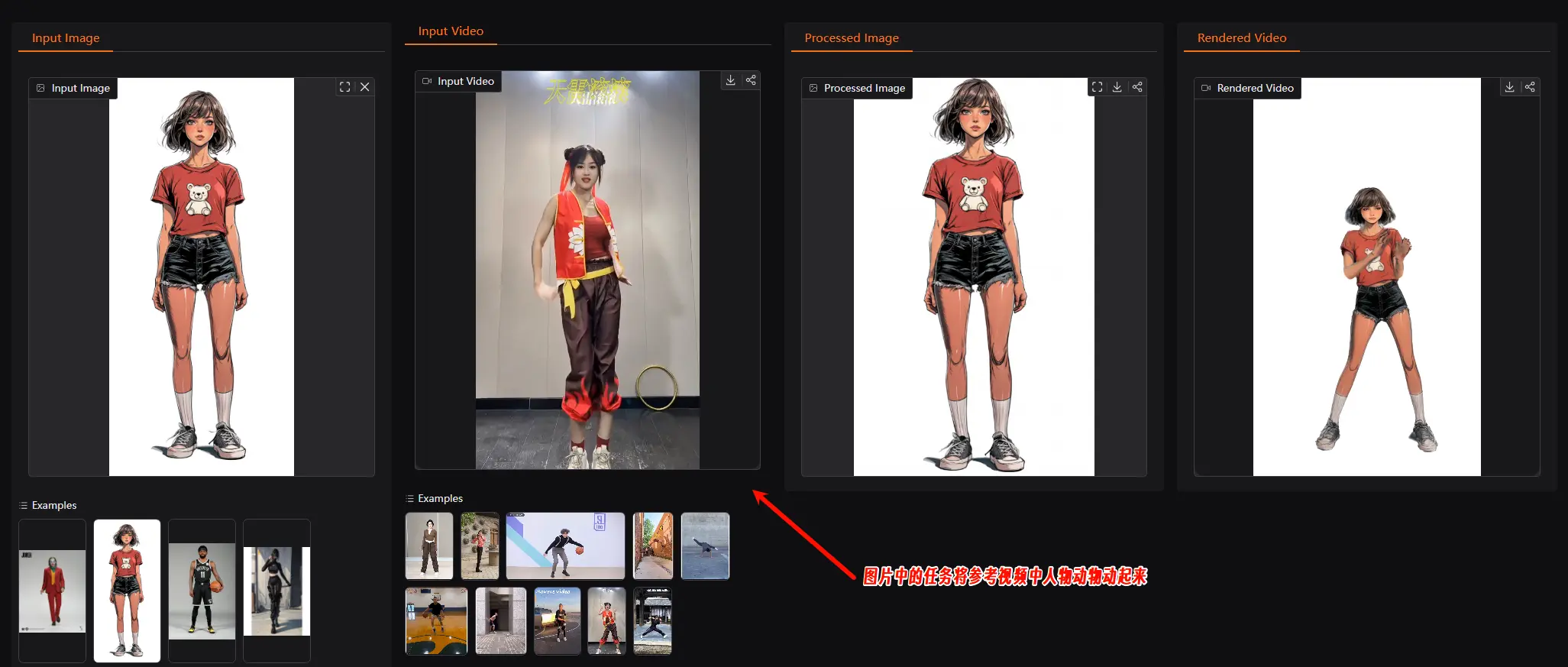
阿里通义实验室推出新型模型LHM,能够在几秒钟内从单张图像重建出可动画化的人体三维模型。该模型利用多模态变换器架构,有效融合了人体位置特征和图像特征,通过注意力机制实现了几何和视觉领域的联合推理。
- 项目主页:https://lingtengqiu.github.io/LHM
- GitHub:https://github.com/aigc3d/LHM
- 模型:https://huggingface.co/DyrusQZ/LHM_Runtime
- Demo:https://huggingface.co/spaces/DyrusQZ/LHM
例如,假设你有一张人物的单张照片,你希望将其转换为一个可以实时渲染和控制姿势的3D人物模型。使用LHM模型,你只需将这张照片输入到模型中,模型会在几秒钟内生成一个高质量的3D人物模型,并且可以对其进行实时渲染和姿势控制。这种技术在虚拟现实(VR)、增强现实(AR)和游戏开发等领域具有广泛的应用前景。
主要功能
- 单图像输入:仅需一张人物的单张图像,即可在几秒钟内生成高质量的3D人物模型。
- 实时渲染和姿势控制:生成的3D人物模型支持实时渲染和姿势控制,能够实时响应用户输入。
- 高保真度重建:通过多模态变换器架构,模型能够详细地保留服装的几何形状和纹理,同时在面部和手部细节上表现出色。
- 强大的泛化能力:模型在大规模视频数据集上进行训练,能够适应各种真实世界场景,具有很强的泛化能力。
- 动画一致性:生成的3D人物模型在不同姿势下保持一致的外观和细节,适合用于动画制作。

主要特点
- 多模态变换器架构:利用多模态变换器(Multimodal Transformer)有效融合3D几何特征和2D图像特征,通过注意力机制实现几何和视觉领域的联合推理。
- 头部特征金字塔编码:通过头部特征金字塔编码(Head Feature Pyramid Encoding, HFPE)方案,聚合多尺度视觉特征,显著提高面部细节的恢复能力。
- 自监督学习:模型通过自监督学习策略,利用大规模视频数据而非稀缺的3D扫描数据进行训练,提高了模型的泛化能力。
- 高效训练和推理:模型在大规模数据集上进行训练,能够在几秒钟内完成推理,适合实时应用。
- 无需后处理:与现有方法相比,LHM无需复杂的后处理步骤,即可生成高质量的3D人物模型。
工作原理
- 输入图像处理:输入一张RGB图像,模型首先提取图像中的身体和头部特征。
- 几何和图像特征编码:
- 几何特征编码:利用SMPL-X模板网格,初始化3D查询点,并通过多层感知机(MLP)投影到变换器的令牌通道维度。
- 图像特征编码:利用预训练的视觉变换器(如Sapiens-1B)提取图像中的语义特征。
- 头部特征编码:通过头部特征金字塔编码(HFPE)方案,聚合多尺度视觉特征,提高面部细节的恢复能力。
- 多模态变换器融合:将几何特征和图像特征通过多模态变换器(MBHT)进行融合,通过注意力机制实现几何和视觉领域的联合推理。
- 3D高斯点云参数预测:通过MLP预测3D高斯点云的参数,包括位置、旋转、缩放和外观特征。
- 训练和优化:
- 视图空间监督:通过线性混合蒙皮(LBS)将预测的3D高斯点云变换到目标视图空间,并通过可微分渲染生成RGB图像和掩码。
- 正则化约束:在规范空间中引入正则化项,包括形状正则化和位置锚定,以保持几何一致性。
- 自监督学习:模型通过自监督学习策略,利用大规模视频数据进行训练,无需3D扫描数据。
应用场景
- 虚拟现实(VR)和增强现实(AR):在VR和AR应用中,用户可以通过单张照片生成自己的3D虚拟形象,并实时控制其动作和表情。
- 游戏开发:在游戏开发中,LHM可以快速生成高质量的3D角色模型,减少美术资源的制作成本和时间。
- 电影和动画制作:在电影和动画制作中,LHM可以用于快速生成角色的3D模型,提高制作效率。
- 社交媒体和内容创作:用户可以在社交媒体平台上使用LHM生成自己的3D虚拟形象,并进行各种创意内容的创作。
- 教育和培训:在教育和培训领域,LHM可以用于生成虚拟教师或培训角色,提供更加生动和互动的学习体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











