
来自北京大学深圳研究生院、罗彻斯特大学、新加坡国立大学、广东工业大学和加州大学圣克鲁斯分校的研究人员推出新型时间延时视频生成模型MagicTime,这个模型的目标是学习现实世界中的物理知识,并能够生成展示这些知识的时间延时视频,也就是所谓的“变质视频”(metamorphic videos)。这些视频不仅记录了时间的流逝,还展示了物体或场景的完整变化过程,比如花朵的开放、建筑物的建造或者冰的融化。
- GitHub:https://github.com/PKU-YuanGroup/MagicTime
- Demo:https://huggingface.co/spaces/BestWishYsh/MagicTime
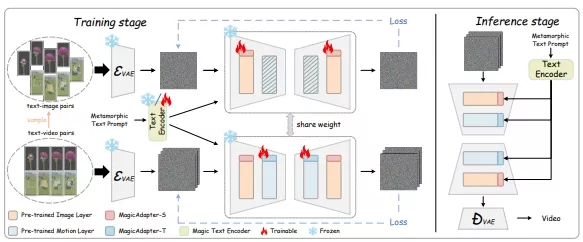
MagicTime能从时间流逝视频中学习现实世界的物理知识,并实现变形生成。首先,开发团队设计了一个MagicAdapter方案,用于解耦空间和时间训练,从变形视频中编码更多的物理知识,并将预训练的T2V模型转化为生成变形视频的模型。其次,引入了一种动态帧提取策略,以适应变形时间流逝视频,这类视频具有更广泛的变化范围,并涵盖了剧烈的对象变形过程,因此包含比通用视频更多的物理知识。最后,开发团队引入了一个Magic TextEncoder,以提升对变形视频提示的理解能力。此外,开发团队还创建了一个名为ChronoMagic的时间流逝视频-文本数据集,专门用于激发变形视频生成能力。大量实验表明,MagicTime在生成高质量、动态的变形视频方面具有优越性和有效性,表明时间流逝视频生成是构建现实世界变形模拟器的有前景的途径。
主要功能和特点:
- 生成高质量的变质视频: MagicTime能够根据文本描述生成具有物理知识、长时间连续性和强烈变化的变质视频。
- 物理知识的编码: 通过分析时间延时视频,模型学习并编码了现实世界的物理规律。
- 动态帧提取策略: 为了适应变化范围更广、包含戏剧性物体变化过程的视频,模型采用了动态帧提取策略。
- 文本编码器的改进: 通过Magic TextEncoder,模型能够更好地理解变质视频的文本提示。
工作原理:
MagicTime模型的工作原理基于扩散模型,它通过两个过程来生成视频:正向扩散和反向去噪。在正向扩散过程中,模型逐步向数据中添加噪声,直到数据变成随机噪声。在反向去噪过程中,模型学习如何逐步去除噪声,恢复出原始数据。MagicTime通过特别设计的MagicAdapter方案来解耦空间和时间训练,从而在预训练的文本到视频(T2V)模型的基础上生成变质视频。此外,它还引入了动态帧提取策略和Magic TextEncoder来提高模型对物理知识的理解。
具体应用场景:
- 教育和科普: MagicTime可以用于生成展示自然现象或科学实验的视频,帮助学生和公众更好地理解物理世界。
- 电影和游戏制作: 在电影和游戏产业中,这个模型可以用来创建具有高度现实感的特效场景,如建筑物的生长或自然灾害的模拟。
- 艺术创作: 艺术家和设计师可以使用MagicTime来创作展示物体变化过程的创新艺术作品。
- 数据增强: 在机器学习的训练过程中,MagicTime可以用来生成额外的训练样本,提高模型的泛化能力。
总的来说,MagicTime是一个强大的工具,它通过结合时间延时视频的物理知识和其他创新技术,提供了一种生成高质量、动态变质视频的新方法。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











