
挚文集团推出HelloMeme,它通过在文本到图像的基础模型中集成空间编织注意力(Spatial Knitting Attentions, SK Attentions)来嵌入高水平和高保真度的条件,以执行复杂的下游任务,同时保持基础模型的泛化能力。这种方法在生成表情包视频(meme video)的任务中得到了验证,并取得了显著的成果。此外,由于这种方法与SD1.5衍生模型具有良好的兼容性,它对开源社区具有一定的价值。
- 项目主页:https://songkey.github.io/hellomeme
- GitHub:https://github.com/HelloVision/HelloMeme
- 模型:https://huggingface.co/songkey
- ComfyUI插件:https://github.com/HelloVision/ComfyUI_HelloMeme
例如,假设我们想要生成一个视频,其中的人物能够根据给定的文本提示或另一个视频的表情和头部姿势来做出反应。使用HelloMeme方法,我们可以将参考图像(包含人物的原始表情和姿势)和驱动图像(包含夸张的表情和头部姿势)作为输入,生成一个既保留了原始人物特征,又能够展现出夸张表情和姿势的新视频。

主要功能
- 特征提取与融合:通过HMReferenceNet和HMControlNet分别提取参考图像的高保真特征和头部姿势、面部表情等高级特征,然后使用SK Attentions机制将这些特征融合。
- 图像生成:HMDenoisingNet接收融合后的特征,并生成新的图像,赋予参考图像新的表情和姿势。
- 视频生成:通过帧到帧的生成,结合Animatediff的motion模块,提高视频帧之间的连续性。
主要特点
- 保持基础模型泛化能力:通过仅优化插入的适配器参数,而不是整个UNet的参数,保持与SD1.5衍生模型的兼容性。
- 空间编织注意力机制:通过行和列的注意力操作来融合2D特征图和线性特征,保留了2D布局中的空间结构信息。
- 轻量级插件:通过插入轻量级的适配器来实现复杂的下游任务,无需重新训练整个模型。
工作原理
HelloMeme方法包括三个主要模块:
- HMReferenceNet:从参考图像中提取高保真特征。
- HMControlNet:提取头部姿势和面部表情等高级特征。
- HMDenoisingNet:基于完整的SD1.5 UNet,接收来自HMReferenceNet和HMControlNet的特征,生成新的图像。
通过SK Attentions机制,这些特征被有效地融合,使得生成的图像既能够展现出夸张的表情和姿势,又能够保留参考图像的高保真特征。
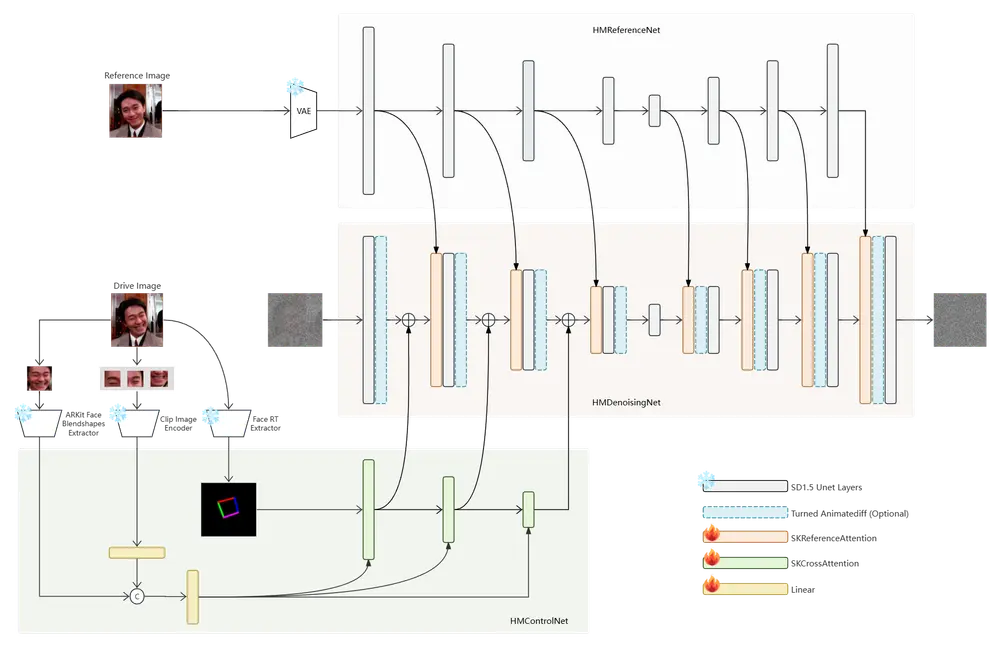
具体应用场景
- 梗视频生成:根据给定的文本提示或驱动视频生成具有夸张表情和姿势的视频内容。
- 虚拟试穿:在虚拟试穿应用中,根据用户的表情和姿势生成试穿效果。
- 面部重演:在影视制作中,用于根据演员的表演生成角色的面部表情和头部姿势。
- 个性化肖像动画:根据用户提供的音频或视频生成个性化的肖像动画。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










