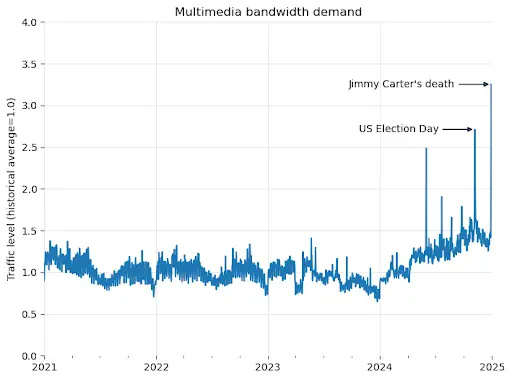
维基媒体基金会本周三披露了一个令人关注的现象:其旗下的多媒体资源库维基共享资源(Wikimedia Commons)自2024年1月以来下载带宽消耗飙升了50%。然而,这一流量激增并非来自人类用户,而是源于训练AI模型的自动化爬虫程序。
基础设施面临巨大压力
维基媒体基金会是一个运营维基百科等众包知识项目的非营利组织。该组织在博客中指出,其基础设施原本是为了应对人类用户的突发流量而设计的,但如今爬虫程序产生的数据需求已经超出了预期,带来了日益增长的风险和成本。
作为开放许可和公共领域多媒体资源的集散地,维基共享资源正面临前所未有的压力。深入分析数据显示,在最消耗资源的流量中,近65%来自爬虫程序,但这些自动化访问仅占总页面浏览量的35%。
爬虫与人类用户的不同访问模式
维基媒体解释称,这种差异源于内容分发机制。人类用户通常会访问热门内容,而这些内容会被缓存在离用户较近的服务器上,从而降低带宽消耗。然而,爬虫程序则会批量抓取大量页面,包括冷门内容,这些内容需要从核心数据中心调取,运营成本显著更高。
博客中写道:“人类读者通常聚焦于特定主题,而爬虫会批量抓取大量页面,包括冷门内容。这类请求更可能触发核心数据中心的响应,极大加重了资源负担。”目前,维基媒体技术团队不得不投入大量精力拦截恶意爬虫,以保障普通用户能够正常访问。然而,这还尚未计入因此产生的云服务成本激增。
全球性趋势与行业反应
这一现象实际上反映了威胁开放互联网存续的全球性趋势。上个月,开源倡导者 Drew DeVault 曾批评 AI 爬虫无视阻拦自动化访问的 robots.txt 协议;工程师 Gergely Orosz 也指控 Meta 等公司的爬虫导致其项目带宽成本暴涨。
面对这一挑战,开发者正在展开反击。部分科技公司已经采取行动,例如 Cloudflare 近期推出了“AI 迷宫”系统,利用 AI 生成内容来拖慢爬虫速度。然而,这场“猫鼠游戏”可能会迫使更多内容平台转向登录墙和付费墙,最终损害所有网络用户的利益。
维基媒体的警示
正如维基媒体所警示的那样:“当开放资源被过度索取,互联网的共享精神正面临严峻考验。” 维基共享资源作为一个重要的公共资源库,其面临的挑战凸显了在 AI 技术快速发展的同时,如何平衡技术创新与公共资源保护的重要性。(来源)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











