
强化学习(RL)在大语言模型(LLM)的后续训练中已被广泛应用,尤其是在提升模型的推理能力方面。然而,如何在各种领域中为LLM获得准确的奖励信号,仍然是一个关键挑战。
DeepSeek与清华大学计算机科学与技术系和清华大学AI产业研究院(AIR)的研究团队合作,提出了一种新的方法,通过增加推理计算来改进奖励建模(RM),并提高性能计算的可扩展性。
研究背景
背景介绍
强化学习(RL)在大语言模型(LLMs)的后训练中得到了广泛应用,尤其是在提升模型的推理能力方面。然而,如何在各种领域中获得准确的奖励信号仍然是一个挑战。现有的研究主要集中在特定领域的奖励生成上,而在一般领域的奖励生成更具挑战性。
研究内容
该研究的核心内容包括如何通过增加推理计算来提高通用奖励建模的质量和可扩展性,并提出了一种新的学习方法——自我原则的批评调整(Self-Principled Critique Tuning,SPCT),以促进生成式奖励模型(GRMs)的推理时间可扩展性。
文献综述
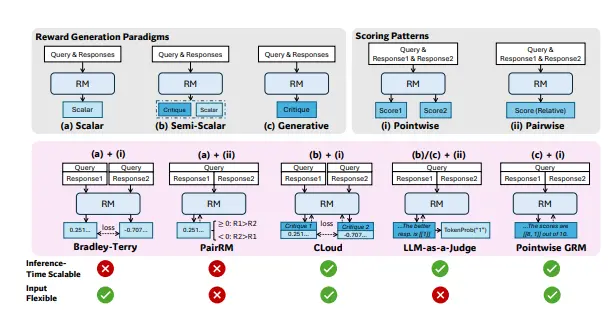
相关工作包括标量、半标量和生成式奖励建模方法。现有研究主要集中在如何通过增加训练计算来提高奖励质量,但很少关注推理时间的可扩展性。
研究方法
点对点生成式奖励建模(GRM)
研究团队采用逐点生成性奖励建模(GRM),以实现不同输入类型的灵活性和推理时间缩放的潜力。GRM能够为每个输入生成一个奖励信号,而不是依赖于单一的标量奖励。
自我原则的批评调整(SPCT)
SPCT是一种新的学习方法,通过规则基础的在线强化学习来优化原则和批评的生成。SPCT包括两个阶段:
- 拒绝性微调:用于冷启动,帮助模型初步适应任务。
- 规则基础RL:用于增强一般奖励生成,通过在线学习不断优化奖励信号。
并行采样
为了提高推理时间的可扩展性,研究团队引入了并行采样。通过并行采样,模型可以生成多个原则和批评集,然后对最终奖励进行投票,从而提高奖励信号的准确性和稳定性。
元奖励建模
为了进一步提升扩展性能,研究团队训练了一个元奖励模型(元RM)。元RM是一个点对标的标量RM,用于识别DeepSeek-GRM生成的原则和批评的正确性,从而指导投票过程。
实验设计
数据收集
数据集包括来自内部数据和开源数据集的偏好数据,涵盖了单响应、成对响应和多响应的偏好数据。
实验设置
实验使用了Gemma-2-27B作为基线模型,并在多个LLM上进行实验,包括DeepSeek-V2-Lite(16B MoE)、Gemma-2-27B、DeepSeek-V2.5(236B MoE)和DeepSeek-V3(671B MoE)。
评估指标
使用标准评估指标,包括选择最佳响应的准确性和ROC-AUC。对于多个响应的情况,每个数据点的正确性取决于是否正确识别出最佳响应。
结果与分析
基准测试
在多个奖励建模(RM)基准测试中,DeepSeek-GRM-27B在整体性能上优于基线方法和一些强大的公共模型。通过推理时间扩展,DeepSeek-GRM-27B进一步提高了性能,达到了最佳的整体结果。
推理时间可扩展性
通过最多32个样本的并行采样,DeepSeek-GRM-27B显示出较高的性能提升潜力。元RM在过滤低质量的轨迹方面表现出有效性,进一步提升了扩展性能。
消融研究
消融研究表明,即使在没有原则生成和拒绝性采样的情况下,模型的性能仍然有所提高,这表明在线训练的重要性。
结论
这篇论文提出了自我原则的批评调整(SPCT)方法,显著提高了通用奖励建模的质量和推理时间可扩展性。实验结果表明,DeepSeek-GRM在多个基准测试中表现优异,并且通过推理时间扩展可以进一步提高性能。未来的研究方向包括将GRMs集成到在线RL管道中,探索与策略模型的推理时间共扩展,或作为基础模型的鲁棒离线评估器。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











