
韩国科学技术研究院和OMNIOUS.AI的研究人员提出了BootComp——一种用于可控人类图像生成的新框架,特别适用于包含多个参考服装的情况。这一创新解决了训练数据获取的主要瓶颈,即为每个人类主体收集大规模高质量参考服装图像数据集的挑战。通过引入一种新颖的数据生成管道和高效的过滤策略,BootComp构建了一个大型合成数据集,并训练了一个具有两条并行去噪路径的扩散模型,从而实现了高质量的人类图像生成。
这个框架的主要特点是能够处理和生成包含复杂服装组合的人物图像,例如游泳衣搭配足球鞋,同时保持服装的细节。例如,你是一名时尚设计师,想要快速预览服装设计在模特身上的效果。通过BootComp,你只需提供模特的图片和服装设计图,该框架就能生成模特穿着这些服装的逼真图像,帮助你在实际制作之前评估和调整设计。

主要功能:
- 多服装生成:能够生成穿着多件参考服装的人物图像。
- 虚拟试穿:用户可以上传自己的图片,框架会将参考服装“试穿”在用户身上。
- 姿势控制:生成的人物图像可以根据给定的姿势进行调整。
- 风格化:能够生成不同风格(如卡通风格)的人物图像。
- 文本控制:通过文本提示控制生成图像的风格和内容。
主要特点:
- 数据生成管道:提出了一个数据生成管道,通过从人物图像中提取服装图像来构建大规模合成数据集。
- 过滤策略:为了确保数据质量,提出了一种基于感知相似度的过滤策略,以移除不理想的生成数据。
- 双路径扩散模型:训练了一个具有两个并行去噪路径的扩散模型,使用多件服装图像作为条件生成人物图像,同时保留细节。
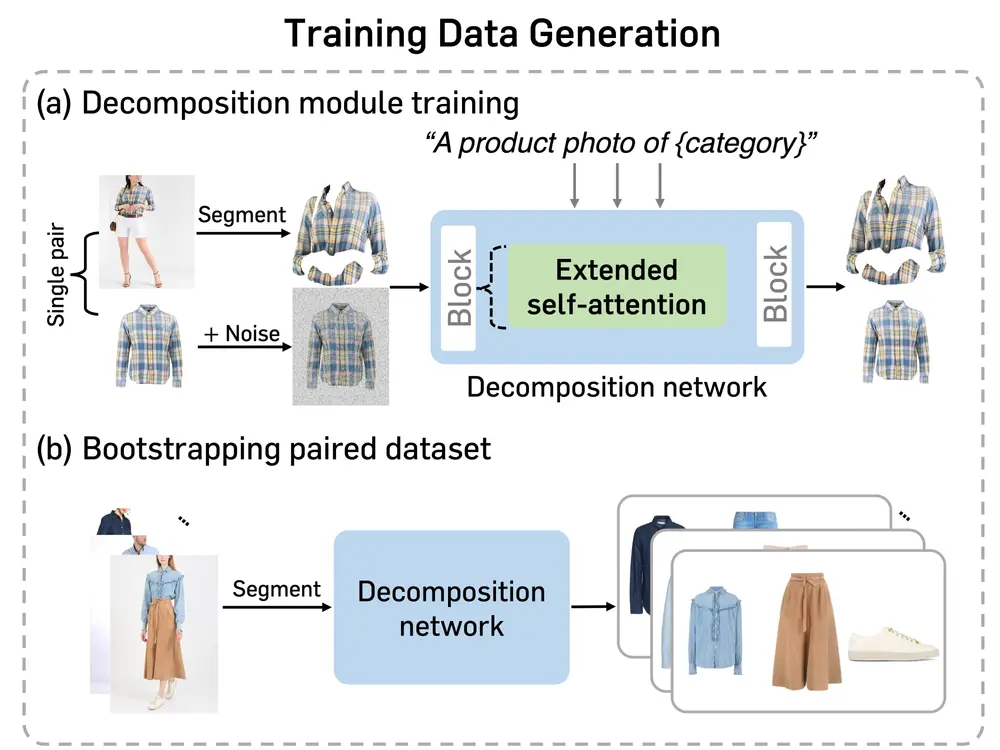
数据生成管道
为了克服大规模高质量参考服装图像数据集的获取难题,研究人员设计了一种数据生成管道,能够从每个输入的人类图像中自动提取任意参考服装图像。具体步骤如下:
- 服装提取:利用计算机视觉技术,从每张人类图像中识别并提取出穿着的服装。这一步骤大大减少了手动收集每件服装照片的工作量。
- 合成数据集构建:将提取的服装图像与原始人类图像配对,构建一个包含人类和多服装对的大型合成数据集。这种方法不仅提高了数据集的规模,还确保了多样性和代表性。
- 感知相似性过滤:为了保证合成数据的质量,研究人员提出了一种过滤策略,根据测量人类图像中呈现的服装与提取的服装之间的感知相似性来去除不理想生成的数据。这种策略确保了最终数据集的高质量,避免了低质量样本对模型训练的负面影响。
双路径扩散模型
基于构建的合成数据集,研究人员训练了一个具有两条并行去噪路径的扩散模型。该模型的设计特点如下:
- 多服装条件:模型使用多服装图像作为条件,生成对应的人类图像,同时保留细粒度细节。这使得生成的图像不仅在整体上符合预期,还在细节上表现出高度的真实感。
- 并行去噪路径:两条并行的去噪路径分别处理人体结构和服装细节,确保生成的图像在保持人体姿态和面部特征的同时,精确地反映了服装的纹理和颜色。
- 细粒度细节保留:通过优化去噪路径的设计,模型能够在生成过程中保留更多细粒度的细节,如衣物的褶皱、纹理和装饰,从而使生成的图像更加逼真。
广泛适用性
BootComp不仅在可控人类图像生成方面表现出色,还展示了其在时尚领域的广泛应用潜力。具体应用包括但不限于:
- 虚拟试穿:用户可以通过上传自己的照片和选择喜欢的服装,即时生成穿着新服装的效果图,实现虚拟试穿体验。
- 姿态控制:除了服装,BootComp还可以根据用户指定的姿态生成相应的人类图像,使生成的内容更加个性化和多样化。
- 面部和其他条件控制:模型支持多种条件控制,如面部表情、背景等,进一步增强了生成图像的灵活性和可控性。
实验结果
实验结果表明,BootComp在多个任务中均取得了优异的表现。特别是在生成高质量、细粒度细节丰富的人类图像方面,BootComp显著优于现有方法。此外,其在虚拟试穿和可控人类图像生成等应用中的表现也证明了其广泛的适用性和强大的生成能力。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











