
上海人工智能实验室、马克斯普朗克信息研究所和南洋理工大学的研究人员推出视频流翻译方法Live2Diff(LIVE2DIFF),它利用了单向注意力机制在视频扩散模型中,专门为直播视频流设计。这种方法的核心是在保持视频的实时处理能力的同时,确保视频内容的连贯性和流畅性。
- 项目主页:https://live2diff.github.io
- GitHub:https://github.com/open-mmlab/Live2Diff
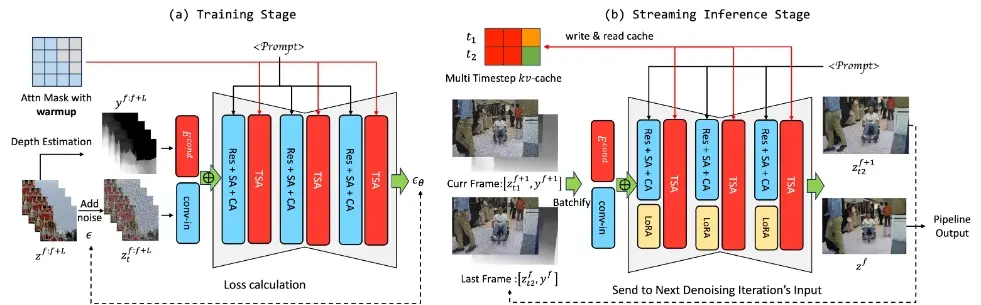
LIVE2DIFF是首个专为直播视频转换设计的时间单向注意力视频扩散模型。与以往方法相比,LIVE2DIFF通过仅考虑当前帧与之前的帧以及少数启动帧的关系,摒弃了对未来帧的依赖,从而确保了时间上的一致流畅性。此外,研究人员采纳了一项高效去噪策略,该策略融入了KV缓存机制和管道技术,旨在实现在交互式帧率下流畅进行直播视频转换。全面的实验结果证明了研究人员提出的注意力机制及处理流程的优越性,在时间平滑度和处理效率方面均超越了以往技术。

例如,你正在观看一场足球比赛的直播,你突然想要把这场比赛的直播视频转换成卡通风格或者任何其他风格,而且要立刻看到效果。Live2Diff就是能够实现这种即时变换的技术。它能够一边接收视频流,一边将视频转换成你想要的风格,而且转换后的视频看起来既连贯又平滑。
主要功能:
- 实时视频流翻译:将直播视频实时转换成目标风格。
- 保持视频的时序连贯性和空间结构一致性。
主要特点:
- 单向时间注意力机制:与传统的双向注意力机制不同,Live2Diff只关注当前帧与之前帧的关系,而不依赖未来帧,这使得模型能够处理实时视频流。
- 高效的去噪方案:通过KV-cache机制和流水线处理,提高了视频翻译的效率。
- 交互式帧率:在高端GPU上,Live2Diff能够以每秒16帧的速度处理512×512分辨率的视频流。
工作原理:
- 数据预处理:首先对输入视频帧添加高斯噪声,然后通过编码器转换成潜在表示。
- 单向注意力:利用单向注意力机制,模型只考虑当前帧之前的帧,忽略后续帧,以保持处理的实时性。
- 去噪和翻译:使用去噪自编码器(U-Net)逐步去除噪声,并根据文本提示生成目标风格的视频帧。
- KV-cache机制:通过缓存和重用之前帧的键(K)和值(V)矩阵,减少重复计算,提高处理速度。
具体应用场景:
- 直播场景:如在线游戏直播、体育赛事直播等,观众可以实时看到不同风格的视频效果。
- 虚拟现实:在虚拟现实或增强现实中,用户可以体验到根据个人偏好实时变换的环境风格。
- 视频编辑:提供一种快速的视频风格转换工具,用于视频制作和后期编辑。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











