
旨在解决从简短的用户输入脚本生成多镜头、电影风格视频的挑战,通过一个协作的、无需训练的架构,专门针对多镜头视频生成任务设计。
例如,用户给出了一个简单的输入脚本:“描述三个化身(两个朋友Mike和Jane,一个坏蛋Tom)在古老金字塔中的奇幻冒险。”VGoT能够将这个简短的描述转换成详细的分镜头脚本,然后生成一系列既符合逻辑又视觉连贯的视频镜头,最终形成一个完整的叙事视频。
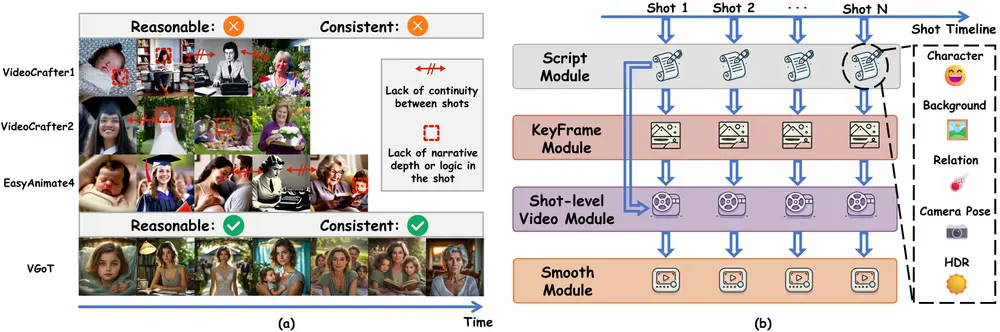
主要功能:
- 多镜头视频生成:将简单的故事情节转化为详细的分镜头描述,并生成相应的视频内容。
- 合理性叙事设计:模仿电影剧本创作,确保视频在逻辑上连贯,角色发展和叙事流程合理。
- 跨镜头一致性:通过身份保持(IP)嵌入和跨镜头平滑机制,确保视频在不同镜头间保持时间和身份的连贯性。
主要特点:
- 模块化设计:VGoT由四个协作模块组成,包括剧本生成、关键帧生成、镜头级视频生成和平滑机制。
- 无需训练:作为一个即插即用的框架,VGoT不需要额外的训练,可以直接应用于现有的视频生成模型。
- 叙事合理性:通过结构化的提示设计,VGoT生成的视频具有深度和逻辑性,每个镜头都能为故事线做出有意义的贡献。
工作原理:
- 剧本生成模块:使用预训练的大型语言模型(LLM)将用户输入的简短故事转化为详细的分镜头脚本。
- 关键帧生成模块:根据剧本生成视觉一致的关键帧,确保角色和环境的外观一致性。
- 镜头级视频生成模块:将关键帧和文本提示转化为代表每个镜头的视频潜在表示,然后生成视频内容。
- 平滑机制:在镜头之间实现平滑过渡,通过重置边界和跨镜头平滑机制,确保视频的整体连贯性。
具体应用场景:
- 电影和视频制作:用于快速生成电影预览或故事板,帮助导演和制片人在实际拍摄前可视化故事。
- 广告和营销:根据产品描述快速生成吸引人的视频广告,提高营销效率。
- 教育和培训:创建教育内容,如历史事件或科学实验的模拟视频,增强学习体验。
- 游戏开发:生成游戏预告片或动态故事情节,提升玩家的沉浸感。
- 社交媒体内容创作:用户可以根据自己的创意快速生成视频内容,用于社交媒体平台分享。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











