
JINA AI推出新型多任务对比训练方法及其模型JINA CLIP,旨在解决现有CLIP(Contrastive Language-Image Pretraining,对比语言-图像预训练)模型在文本检索任务中性能不佳的问题。CLIP模型通常用于将图像和文本映射到一个共同的嵌入空间中,使得它们能够通过固定大小的向量进行比较和检索。但CLIP在处理只有文本的任务时,相比专门的文本模型,性能上会有所不足。
对比语言-图像预训练(Contrastive Language-Image Pretraining, 简称CLIP)被广泛应用于通过将图像和文本映射到固定尺寸的向量中,从而在一个共享嵌入空间里对齐它们,以此来训练模型。这些模型对于多模态信息检索及相关任务至关重要。然而,CLIP模型在仅文本任务上的表现通常不如专门的文本模型,这导致了信息检索系统中的效率问题,这类系统需要为仅文本任务和多模态任务分别维护独立的嵌入和模型。针对这一问题,JINA AI提出了一种新颖的多任务对比训练方法,并利用该方法训练了jina-clip-v1模型,使其在文本-图像及文本-文本检索任务上均达到了最先进的性能水平。例如,你正在寻找与某个历史事件相关的图片和文章,JINA CLIP可以帮助你通过输入相关的描述或问题,快速从庞大的数据集中找到匹配的图像和文本资料。这在学术研究、内容创作或教育领域都非常有用。
主要功能:
JINA CLIP的主要功能是提高模型在文本-图像检索和纯文本检索任务上的表现。它通过一种新颖的多任务学习方法,使得模型能够同时处理文本-图像对和文本-文本对,从而在两种任务上都取得良好的性能。
主要特点:
- 多任务学习: JINA CLIP通过同时优化文本-图像和文本-文本的表示对齐,使得模型可以处理多种类型的任务。
- 对比训练: 利用大规模的图像-标题对和文本对进行对比训练,提升模型对语义相似性的理解。
- 长文本支持: 特别优化了对长文本的处理能力,使其在文本检索任务上表现更佳。
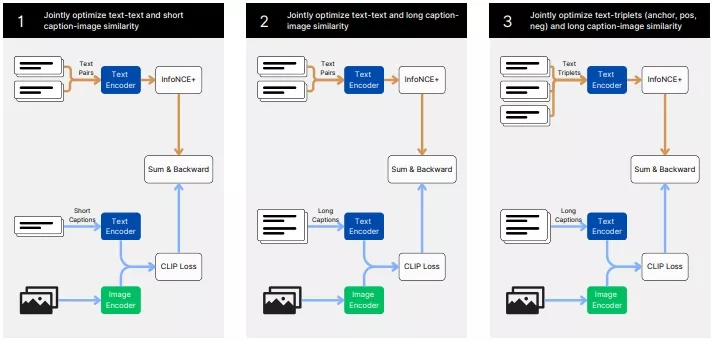
工作原理: JINA CLIP的训练分为三个阶段:
- 第一阶段: 模型学习对齐图像和文本的表示,同时最小化文本-文本匹配的损失。
- 第二阶段: 引入更长的、合成的图像标题,继续训练文本-文本对。
- 第三阶段: 使用困难负样本来进一步提升文本编码器区分相关和不相关文本的能力,同时继续训练长图像标题以保持文本-图像对齐。
具体应用场景:
- 图像检索: 利用文本描述来检索相关图像,比如在拥有大量图片库的网站上根据用户输入的关键词找到图片。
- 文本检索: 在大量文档中根据用户的查询快速找到相关文本,适用于搜索引擎和信息检索系统。
- 多模态信息检索: 结合图像和文本数据,提供更丰富的检索体验,比如在社交媒体平台中同时根据图片和文字内容检索帖子。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











