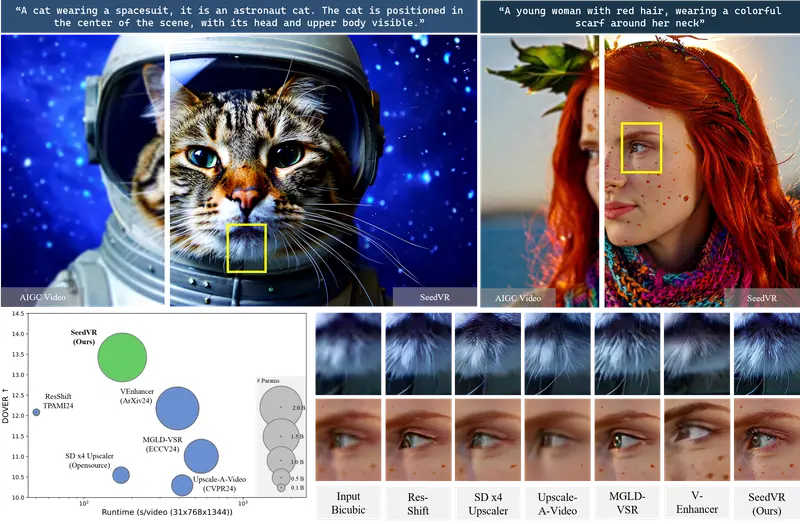
来自南洋理工大学、腾讯AI实验室、香港科技大学和克莱姆森大学的研究人员提出了一种名为自级联扩散模型(Self-Cascade Diffusion Model)的新方法,该方法利用了低分辨率模型的丰富知识,通过调整或微调(tuning)来快速适应高分辨率的图像和视频生成。‘
该模型能够生成高质量的高分辨率图像和视频。它不仅可以处理不同尺寸的图像,还能在保持原有图像内容的基础上,增加更多的细节和清晰度。
主要功能:
- 提供了一种无需调整(tuning-free)或低成本调整(cheap tuning)的策略,使大型预训练的扩散模型能够快速适应高分辨率的图像和视频生成。
- 通过引入多尺度上采样模块,模型能够在保持原有构图和生成能力的同时,高效地适应更高分辨率。
主要特点:
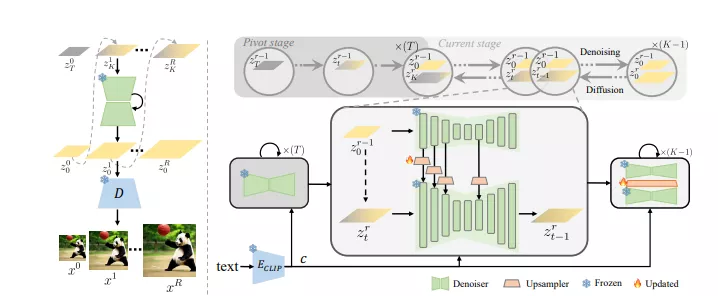
- 自级联策略: 通过循环重用低分辨率模型,模型能够逐步适应更高分辨率的生成任务。
- 时间感知特征上采样器: 在调整版本中,引入了一系列可插拔的、可学习的、时间感知的特征上采样器,这些上采样器能够从少量高质量数据中学习,以增强模型在新分辨率下的适应性。
- 训练加速: 与完全微调相比,该方法实现了5倍的训练加速,并且只需要额外0.002M的可训练参数。

工作原理:
- 自级联策略: 首先,模型在低分辨率下生成图像,然后这个低分辨率图像作为“支点”(pivot),用于指导更高分辨率图像的生成。这个过程是通过在低分辨率图像上添加噪声并逐步去除来实现的。
- 时间感知特征上采样器: 在生成过程中,模型会根据当前步骤的时间信息,调整上采样器的参数,以确保在去除噪声的同时,能够保留和增强图像的细节结构。
- 微调: 对于需要更精细调整的模型,可以通过微调少量的上采样器参数,使用少量高质量数据来进一步提升模型在新分辨率下的表现。
应用场景:
- 图像超分辨率:用于将低分辨率的图像转换为高分辨率的图像,这在图像处理、计算机视觉和医学影像分析等领域都有广泛的应用。
- 视频增强:可以用于提高视频的质量和清晰度,特别是在视频编辑、监控和安全等领域。
- 虚拟现实和增强现实:在生成逼真的虚拟场景或增强现实内容时,该模型可以提供高质量的高分辨率图像和视频。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











