新GreenBoost:Linux 下的“显存无限”魔法,让 12GB 显卡跑 32GB 大模型你是否拥有一张消费级显卡(如 RTX 4070/5070 12GB),却眼馋那些需要 24GB 甚至 48GB 显存才能运行的超大语言模型(如 GLM-4-Flash, Llama-3-70B)? 传...新技术# GreenBoost# 大语言模型14小时前050
新FastVideo 里程碑:单卡 4.5 秒生成 1080p 视频,AI 视频创作进入“实时交互”时代“灵感稍纵即逝,但生成却要等几分钟。” 这是当前 AI 视频创作者最大的痛点。当生成速度慢于构思速度时,创意的反馈循环就被彻底打破了。 FastVideo 团队宣布了一项突破性进展:他们成功将开源模型...新技术# FastVideo# LTX-2.322小时前030
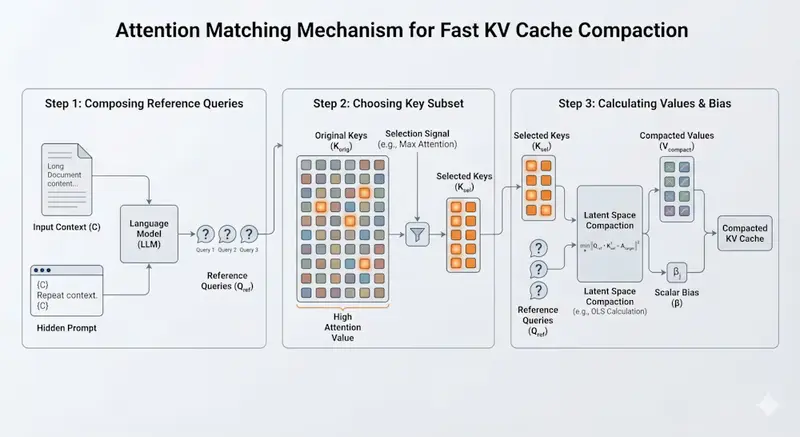
麻省理工突破:Attention Matching 技术让 LLM 内存需求骤降 50 倍,精度无损在企业级 AI 应用中,长上下文处理一直是个昂贵的痛点。分析数百页的法律合同、维护跨天的客户对话、或运行自主编码智能体时,KV 缓存(Key-Value Cache)的内存占用往往成为瓶颈,单个请求即...新技术# Attention Matching# 麻省理工学院3天前0130
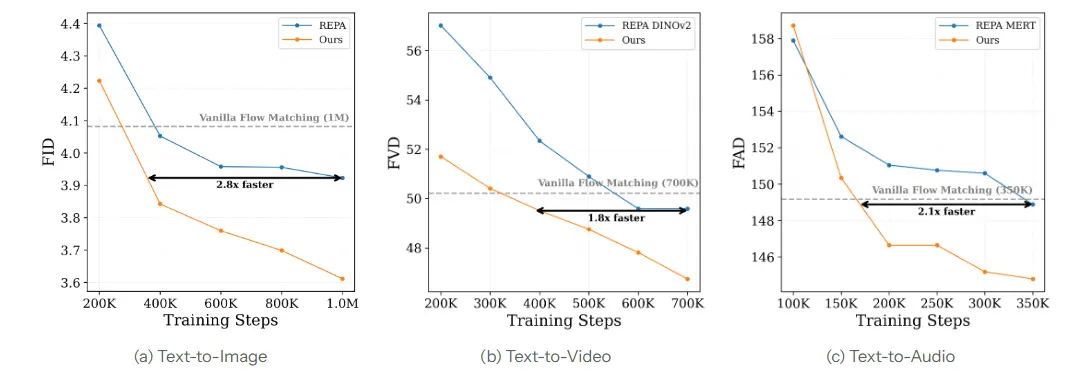
Black Forest Labs 发布 Self-Flow:训练效率提升 2.8 倍,终结多模态 AI 的“教师依赖”时代在生成式 AI 领域,扩散模型(如 Stable Diffusion、FLUX)长期面临一个结构性瓶颈:它们自身缺乏深层的语义理解能力,必须依赖外部“教师”模型(如 CLIP、DINOv2)来提供指导...新技术# Black Forest Labs# Self-Flow# 黑森林实验室3天前090
WILDACTOR:告别 AI 视频“变脸”噩梦,港科大团队实现任意视角下的全身身份严格一致“现在的 AI 视频生成越来越逼真,但往往‘见光死’:镜头一转,主角换了张脸;动作一大,身体变了模样。这种‘身份漂移’让 AI 视频难以真正用于影视制作。” “WILDACTOR 的出现,就是为了让数...新技术# WILDACTOR# 身份一致6天前0200
Databricks 推出 FlashOptim:显存占用直砍 50%,70 亿参数模型训练门槛从 112GB 骤降至 35GB在 AI 模型参数规模迈向万亿级的今天,“显存焦虑”已成为制约创新的最大瓶颈。训练一个 70 亿参数的语言模型,仅参数和优化器状态就需要 112GB 显存,这让拥有 24GB 消费级显卡的绝大多数开发...新技术# FlashOptim# 显存优化2周前0250
CUDA Agent:字节与清华联手打造,AI 首次超越工业级编译器,自动编写高性能 GPU 内核在现代人工智能的基石——GPU 加速计算领域,编写高性能 CUDA 内核 一直是一项只有少数人类专家才能掌握的“黑魔法”。尽管大语言模型在普通编程上表现优异,但在涉及底层硬件架构、内存管理和并行计算的...新技术# CUDA Agent# CUDA 内核2周前0320
微软发布 OPCD 新框架:告别冗长系统提示,将企业知识“烧录”进模型参数,推理速度倍增在构建企业级大语言模型应用时,开发者们往往面临一个两难困境:为了让模型懂业务、守规矩,必须编写长达数千字的系统提示(System Prompt),注入公司政策、领域知识和安全约束;但这些冗长的上下文不...新技术# OPCD# 微软2周前0160
DeepSeek 联手清北发布 DualPath:破解 AI 智能体长上下文推理的存储带宽瓶颈,吞吐量提升 87%来自北京大学、清华大学和DeepSeek的研究团队发布论文,研究的是AI智能体(Agent)推理时的存储瓶颈问题。 背景是这样的:现在的AI不再只是简单的一问一答,而是变成了能自主规划、调用工具、多轮...新技术# DeepSeek# DualPath2周前0180
SeaCache:利用“光谱演化”原理重构扩散模型缓存,实现推理速度与画质的双重突破扩散模型(Diffusion Models)无疑是当前视觉生成的基石,但其固有的顺序去噪过程导致推理速度缓慢,成为大规模应用的瓶颈。现有的加速方法多采用“缓存策略”,即重用相邻时间步的中间输出。然而...新技术# SeaCache2周前0220
当AI学会"分工合作":谷歌DeepMind提出智能AI委托框架想象一个场景:你有一个非常复杂的任务,比如策划一场跨国会议、开发一款新软件,或者管理一家公司的供应链。这个任务太复杂了,一个人(或一个AI)无法独立完成,需要拆分成许多小任务,分配给不同的人或AI来完...新技术# DeepMind# 智能AI委托框架3周前0220
Vec2Pix:用 SVG 矢量图“操控”FLUX.1,实现像素级精准编辑与重绘在当前的 AI 绘图领域,我们往往面临一个尴尬的困境:生成容易,修改难。想要移动图中的物体、改变某个局部的颜色,或者调整形状,通常只能依赖复杂的 Inpainting(重绘)、繁琐的 ControlN...新技术# FLUX.1-dev# Vec2Pix4周前01250