
Hedra
Hedra 是一个人工智能创作实验室,通过尖端的视频模型,赋能人类讲故事的能力。只需几秒钟,即可将您的角色变成富有表现力的说话者、歌手和说唱歌手。
OpenAI正式推出了全新的音频模型,涵盖了文本转语音(Text-to-Speech, TTS)和语音转文本(Speech-to-Text, STT)两大核心功能,为语音交互领域带来了重大突破。
OpenAI于2025年3月20日发布了两款全新的音频模型,分别专注于文本转语音(Text-to-Speech, TTS)和语音转文本(Speech-to-Text, STT),旨在为开发者提供更加智能、准确且个性化的语音代理解决方案。
在过去的几个月中,我们致力于提升基于文本的代理——即代表用户独立完成任务的系统——的智能、能力和实用性,推出了如 Operator、Deep Research、Computer-Using Agents 以及内置工具的 Responses API 等版本。然而,为了让代理真正发挥作用,人们需要与代理进行更深入、更直观的互动,超越单纯的文本交流——使用自然的口语进行有效沟通。

今天,我们在 API 中推出了新的语音转文本和文本转语音音频模型,使开发者能够构建更强大、可定制且智能的语音代理,为用户提供真正的价值。我们最新的语音转文本模型树立了新的行业标杆,在准确性和可靠性上超越了现有解决方案,尤其是在涉及口音、嘈杂环境和不同语速等具有挑战性的场景中。这些改进提升了转录的可靠性,使模型特别适用于客户呼叫中心、会议笔记转录等用例。
首次,开发者还可以指示文本转语音模型以特定方式说话,例如“像一个富有同情心的客服代理那样说话”,从而为语音代理解锁了新的定制化水平。这支持了从更具同理心和动态的客服声音到创意故事叙述的表达性旁白等广泛的定制化应用。
我们在 2022 年推出了首个音频模型,此后我们一直致力于提升这些模型的智能性、准确性和可靠性。有了这些新音频模型,开发者可以在 API 中构建更准确、更稳健的语音转文本系统以及富有表现力、个性化的文本转语音声音。
我们推出了新的 gpt-4o-transcribe 和 gpt-4o-mini-transcribe 模型,相较于原始 Whisper 模型,这些模型在词错率、语言识别和准确性方面都有所改进。
gpt-4o-transcribe 在多个既定基准测试中展示了对现有 Whisper 模型的词错率 (WER) 性能改进,反映了我们在语音转文本技术上的重大进步。这些进步直接源于强化学习的针对性创新以及使用多样化、高质量音频数据集进行的广泛中期训练。
因此,这些新的语音转文本模型能够更好地捕捉语音细微差别,减少误识别,并提升转录可靠性,尤其是在涉及口音、嘈杂环境和不同语速的挑战性场景中。这些模型现已在语音转文本 API 中可用(在新窗口中打开)。
最新的语音转文本模型在FLEURS上减少了转录错误

词错率 (WER) 通过计算与参考转录相比的错误转录词百分比来衡量语音识别模型的准确性——WER 越低越好,意味着错误越少。我们最新的语音转文本模型在包括 FLEURS(语音通用表征的少样本学习评估)在内的基准测试中实现了更低的 WER,这是一个涵盖 100 多种语言的多语种语音基准,使用手动转录的音频样本。这些结果展示了更强的转录准确性和更广泛的语言覆盖。如图所示,我们的模型在所有语言评估中始终优于 Whisper v2 和 Whisper v3。
比较领先模型在FLEURS上的单词错误率
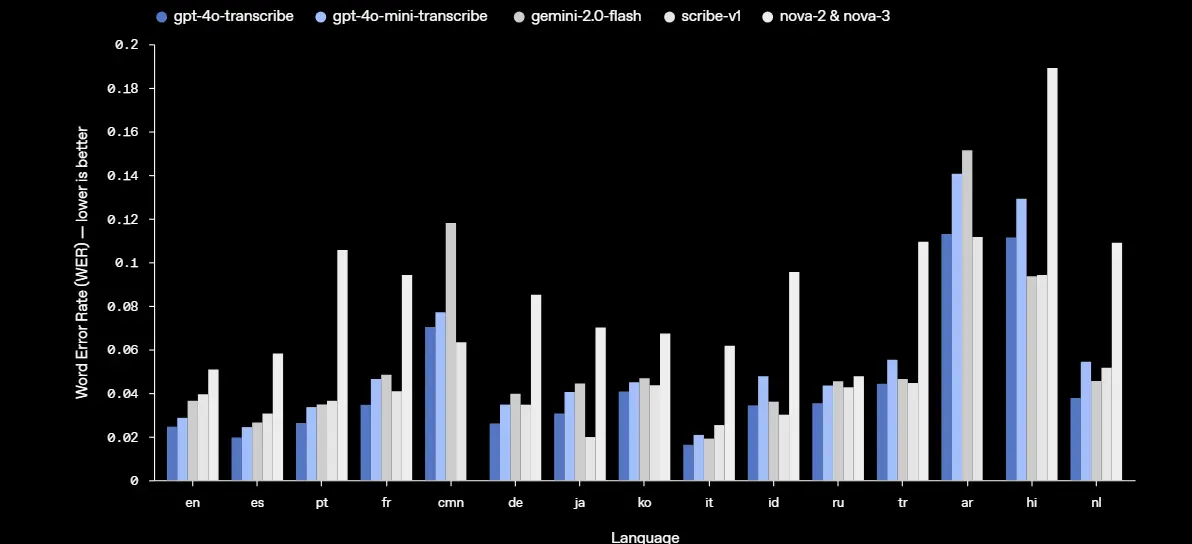
在 FLEURS 上,我们的模型提供了更低的 WER 和强大的多语言性能。WER 越低越好,意味着错误越少。如图所示,我们的模型在大多数主要语言中匹配或优于其他领先模型。
我们还推出了新的 gpt-4o-mini-tts 模型,具有更好的可控性。首次,开发者不仅可以“指示”模型说什么,还可以指示“如何说”——为从客户服务到创意故事叙述的用例提供更定制化的体验。该模型现已在文本转语音 API 中可用(在新窗口中打开)。请注意,这些文本转语音模型仅限于人工预设的声音,我们会对其进行监控,以确保它们始终与合成预设一致。
我们的新音频模型基于 GPT-4o 和 GPT-4o-mini 架构,并在专门的音频中心数据集上进行了广泛预训练,这对优化模型性能至关重要。这种针对性方法提供了对语音细微差别的更深入洞察,并实现了音频相关任务的卓越性能。
我们改进了蒸馏技术,实现了从最大音频模型到更小、更高效模型的知识转移。利用先进的自博弈方法,我们的蒸馏数据集有效捕捉了真实的对话动态,复制了真正的用户-助手互动。这帮助我们的小型模型提供出色的对话质量和响应能力。
对于我们的语音转文本模型,我们集成了强化学习 (RL) 为主的范式,将转录准确性推向了最先进的水平。这种方法显著提高了精度并减少了幻觉,使我们的语音转文本解决方案在复杂语音识别场景中极具竞争力。
这些发展代表了音频建模领域的进步,结合创新方法和实用增强,为语音应用提供了更高的性能。
这些新音频模型现已对所有开发者开放——更多关于使用音频构建的信息请点击这里(在新窗口中打开)。对于已经使用基于文本模型构建对话体验的开发者来说,添加我们的语音转文本和文本转语音模型是构建语音代理的最简单方式。我们发布了与 Agents SDK 的集成(在新窗口中打开),简化了这一开发过程。对于希望构建低延迟语音到语音体验的开发者,我们建议在 Realtime API 中使用我们的语音到语音模型构建。
展望未来,我们计划继续投资于提升音频模型的智能性和准确性,并探索允许开发者引入自定义声音的方式,以符合我们安全标准的方式构建更个性化的体验。此外,我们正在继续与政策制定者、研究人员、开发者和创意人士就合成声音可能带来的挑战和机遇进行对话。我们很兴奋能看到开发者利用这些增强的音频功能构建出创新且富有创意的应用。我们还将投资于其他模态——包括视频——以使开发者能够构建多模态代理体验。