
来自字节跳动、清华大学和香港大学的研究团队共同推出了一款名为 DAPO(动态采样策略优化)的开源系统,旨在提升大语言模型(LLM)的推理能力。DAPO 的发布标志着在强化学习(RL)技术应用于大规模语言模型训练方面的重大进展,同时也强调了科研透明度和协作的重要性。
- 项目主页:https://dapo-sia.github.io
- GitHub:https://github.com/BytedTsinghua-SIA/DAPO
- 数据:https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k
核心创新与技术基础
DAPO 系统集成了四项核心技术创新,针对强化学习中的关键挑战提供了具体的解决方案:
- Clip-Higher:通过谨慎管理策略更新中的裁剪比率,解决了熵崩溃问题,即模型过早陷入有限探索模式的情况,鼓励模型输出更大的多样性。
- 动态采样:根据样本的有用性动态过滤样本,以应对训练过程中的低效问题,确保更一致的梯度信号。
- 基于令牌的政策梯度损失:提供一种精细的损失计算方法,强调基于令牌而非样本级别的调整,更好地适应推理序列长度的变化。
- 超长回报塑造:对过长响应施加受控惩罚,温和引导模型走向简洁高效的推理。
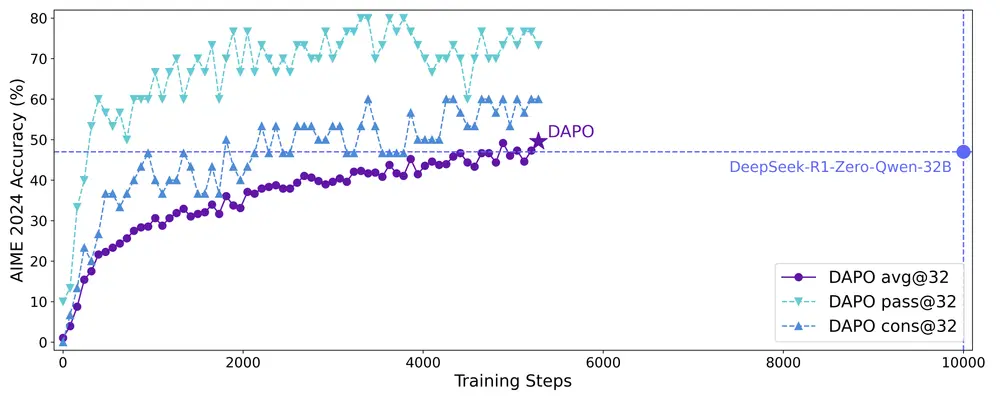
实验成果
在实际测试中,DAPO 展现了显著的优势。使用 Qwen2.5-32B 基础模型训练的 DAPO 模型在美国邀请数学考试(AIME)基准测试上取得了 50 分的成绩,超越了 DeepSeek-R1-Zero-Qwen-32B 方法的 47 分,并且仅用了约一半的训练步骤。此外,随着训练的深入,模型逐渐表现出更多的反思行为,显示了其认知策略的发展潜力。
开源贡献
DAPO 基于 verl 框架构建,包括训练代码及专门为数学推理任务设计的数据集 DAPO-Math-17K。通过公开分享所有算法细节、训练过程和数据集,DAPO 力求弥合可重现性的差距,促进更广泛的科学努力和协作研究的进展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











