
来自特拉维夫大学和英伟达的研究人员提出了一种创新方法ConsiStory,它允许用户通过自然语言描述生成一系列图像,这些图像不仅能够保持一致的主题,而且能够遵循文本提示。ConsiStory的核心目标是在不进行任何优化或预训练的情况下,实现这一目标。
- 项目主页:https://research.nvidia.com/labs/par/consistory
- GitHub:https://github.com/NVlabs/consistory
- Demo:https://build.nvidia.com/nvidia/consistory
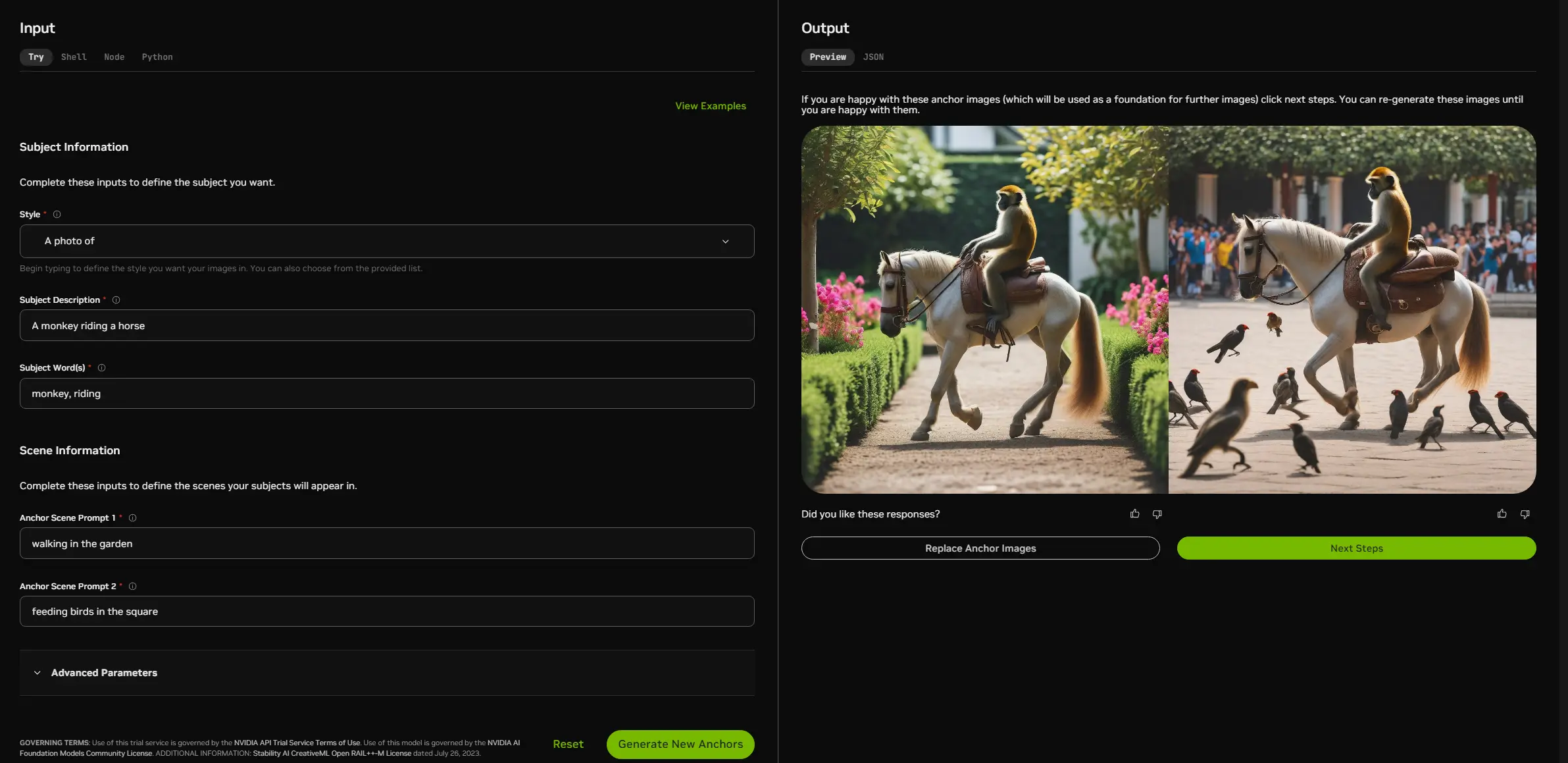
现有的文本到图像生成方法在保持生成的图像与文本提示的一致性方面存在挑战。现有的方法要么需要对每个主体进行优化,要么需要大规模的预训练。而且,他们很难将生成的图像与文本提示对齐,并在描绘多个主体时面临困难。ConsiStory通过在生成过程中共享预训练模型的内部激活,利用内部特征表示来使生成的图像保持一致。

主要功能:
ConsiStory的主要功能是生成一系列图像,这些图像在视觉上保持一致的主题,同时与提供的文本描述紧密对齐。它能够处理单主题和多主题的场景,并且能够在不牺牲图像多样性的情况下,保持主题的一致性。

主要特点:
- 无需训练: ConsiStory不需要对预训练模型进行任何调整或优化,即可实现一致性生成。
- 跨帧一致性: 它通过共享预训练模型的内部激活来促进图像之间的一致性。
- 多样性保持: 通过引入注意力机制的dropout和特征注入,ConsiStory在保持主题一致性的同时,也鼓励布局多样性。
- 多主题支持: ConsiStory可以自然地扩展到多主题场景,甚至实现常见对象的训练无关个性化。
工作原理:
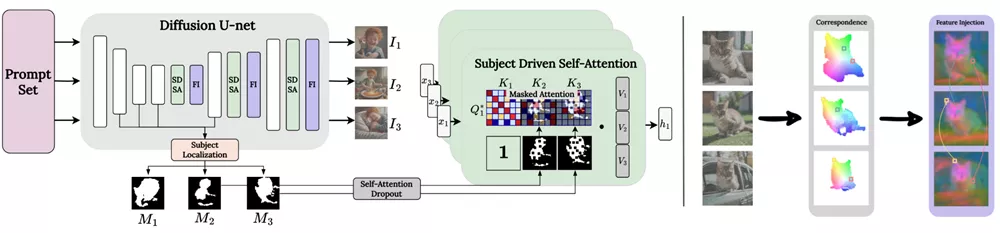
ConsiStory的工作原理分为三个主要步骤:
- 主题定位: 在生成的一系列图像中定位主题。
- 共享注意力机制: 通过扩展自注意力机制,允许生成的图像相互关注,从而在不同图像之间共享主题信息。
- 特征注入: 使用基于扩散特征的密集对应图来对齐图像中的主题像素,进一步细化细节一致性。
应用场景:
ConsiStory的应用场景非常广泛,包括但不限于:
- 故事书生成: 创建一系列具有一致角色的插图。
- 虚拟资产设计: 在游戏或虚拟现实中创建一致的角色和环境。
- 图形小说创作: 生成一系列风格统一的漫画或插画。
- 合成数据生成: 为机器学习模型提供一致性训练数据。
- 个性化内容创作: 用户可以根据自己的描述生成具有特定主题的图像序列。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...