
在计算机视觉领域,深度估计是许多应用(如3D重建、机器人导航和增强现实)的基础。然而,传统的单目深度估计方法虽然可以生成高分辨率的深度图,但在提供一致的度量尺度信息方面存在困难,即使经过LiDAR对齐后也难以保证精度。另一方面,密集LiDAR虽然能够提供精确的深度信息,但其高昂的成本限制了广泛应用。低成本LiDAR虽然更受欢迎,但由于功率有限,其深度分辨率较低且噪声较大。
为了解决这些问题,浙江大学、字节跳动、上海交通大学和苏黎世联邦理工学院的研究人员提出了Prompt Depth Anything(PDA),这是一种新的度量深度估计范式,利用低成本的LiDAR(光检测和测距)数据作为提示,引导深度模型输出精确的度量深度信息,实现高达4K分辨率的准确度量深度估计。
- 项目主页:https://promptda.github.io
- GitHub:https://github.com/DepthAnything/PromptDA
- Demo:https://huggingface.co/spaces/depth-anything/PromptDA
例如,我们有一张室内场景的照片,需要估计照片中各个物体的精确深度信息。使用“Prompt Depth Anything”方法,我们可以将这张照片和相应的低成本LiDAR深度图作为输入,模型将输出一个高分辨率的深度图,其中包含了照片中每个像素点的精确深度信息。这可以帮助进行更精确的3D重建、机器人抓取物体等应用。
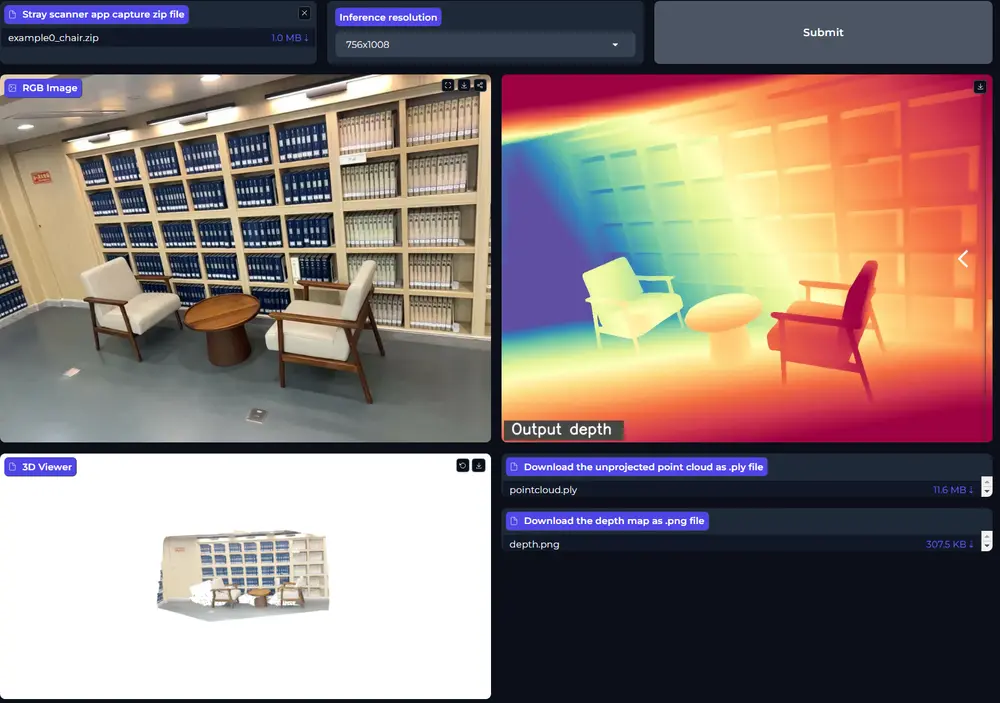
主要功能和特点
- 度量深度估计:与传统的相对深度估计不同,该方法能够提供具有实际尺度信息的度量深度图。
- 高分辨率输出:能够生成高达4K分辨率的深度图,提供更精细的深度信息。
- 多尺度提示融合:通过在深度解码器的多个尺度上融合LiDAR深度信息,提高了深度估计的准确性。
- 边缘感知深度损失:为了更好地利用伪GT(Ground Truth)深度和FARO标注的GT深度,提出了一种边缘感知的深度损失函数,以提高纹理区域和边缘区域的深度估计质量。

PDA的核心创新
1. 提示融合设计
PDA借鉴了视觉-语言模型(VLM)和大型语言模型(LLM)中提示(prompting)的成功经验,将低成本LiDAR作为提示,指导Depth Anything模型输出精确的度量深度。具体来说,PDA采用了一个简洁的提示融合设计,将LiDAR数据在深度解码器中以多尺度集成。这种设计确保了LiDAR提示能够在不同层次上影响模型的预测,从而提高深度估计的准确性和分辨率。
2. 可扩展的数据管道
为了应对包含LiDAR深度和精确GT深度的有限数据集带来的训练挑战,研究人员提出了一种可扩展的数据管道,包括:
- 合成数据LiDAR模拟:通过模拟低成本LiDAR的噪声特性,生成大量的合成数据,用于训练模型。
- 真实数据伪GT深度生成:利用现有的RGB-D数据集(如ScanNet++),通过后处理生成伪GT深度图,扩大训练数据的规模。
此外,研究团队还发布了ScanNet++数据集的更详细深度标注,进一步丰富了可用的训练资源。
与现有方法的对比
1. 与单目深度方法的对比
单目深度方法虽然可以生成高分辨率的深度图,但在一致的度量尺度信息方面存在困难,即使在与LiDAR对齐后也无法保证足够的精度。相比之下,PDA通过引入低成本LiDAR作为提示,能够生成具有精确度量尺度的深度图,解决了单目方法的局限性。
2. 与ARKit LiDAR深度的对比
ARKit LiDAR深度是由ARKit API使用iPhone LiDAR的24x24点数据和RGB图像生成的低分辨率深度图。尽管ARKit LiDAR提供了相对准确的深度信息,但其分辨率较低且噪声较大。PDA通过将低成本LiDAR作为提示,结合深度基础模型的强大泛化能力,能够在保持高分辨率的同时显著提高深度估计的精度。
应用场景
1. 街道重建
PDA在街道重建任务中表现出色,能够生成高分辨率、精确的深度图,帮助构建详细的3D城市模型。这对于自动驾驶、城市规划和虚拟现实等应用具有重要意义。
2. 通用机器人抓取
PDA不仅在漫反射物体上表现优异,还能有效处理透明和镜面物体的抓取任务。实验结果显示,即使在抓取策略仅在漫反射物体上训练的情况下,PDA生成的深度图也能帮助机器人更准确地抓取这些复杂物体,优于传统的RGB和LiDAR方法。
性能与效率
PDA的ViT-Small模型可以在单个RTX 4090 GPU上以94+ FPS的速度运行,视频演示中加速了2倍。这表明PDA不仅在精度上达到了新的高度,还在实时性能上具备很强的竞争力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











