
近年来,预训练扩散Transformer(DiTs)在上下文生成能力方面展现了巨大的潜力,能够以最小的架构修改或无需修改的情况下无缝适应多样化的视觉任务。这些能力通过跨多个输入和目标图像的自注意力令牌拼接、分组和掩码生成管道来解锁。基于这一基础,通义实验室提出了ChatDiT——一个零样本、通用且交互式的视觉生成框架。ChatDiT直接利用预训练的扩散Transformer,无需额外的微调、适配器或修改,用户可以通过自由形式的自然语言与之交互,完成复杂的视觉生成任务。ChatDiT允许用户通过自由形式的自然语言指令与系统交互,创建交织文本-图像文章、多页画册、编辑图像、设计IP衍生品或开发角色设计设置等,全部通过一个或多个对话轮次完成。
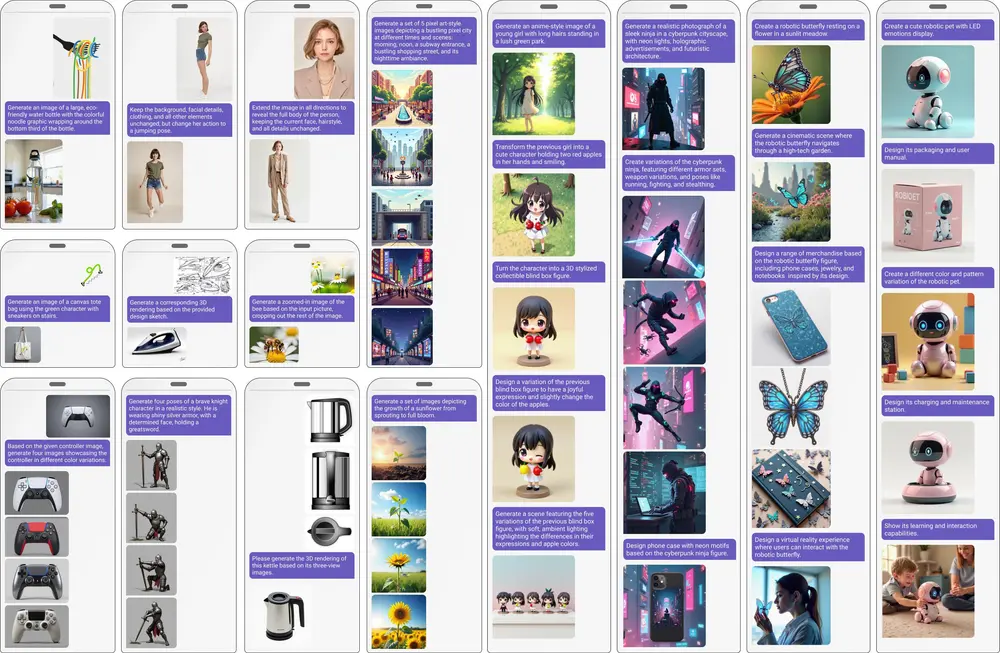
例如,一个用户想要创建一个关于未来运动赛事的插图文章,其中包含使用悬浮滑板和外骨骼技术的高科技运动员。用户可以通过自然语言向ChatDiT描述这个场景,并提供一些参考图像。ChatDiT将理解用户的指令,并生成一系列符合描述的图像,同时保持文本和图像内容的一致性。
ChatDiT的核心特点
1. 零样本与通用性
ChatDiT的最大亮点在于其零样本学习能力。它能够在没有任何额外训练的情况下,处理多种视觉生成任务,如创建交错的图文文章、多页图画书、编辑图像、设计IP衍生品或开发角色设计设定。这种通用性使得ChatDiT适用于广泛的场景,而无需为每个特定任务进行定制化调整。
2. 交互式多轮对话
ChatDiT支持与用户的多轮交互,允许用户通过自然语言指令动态调整生成内容。用户可以在一轮或多轮对话中提供不同的指令和输入图像,ChatDiT会根据上下文自动生成相应的视觉输出。这种交互式设计使得用户可以更灵活地控制生成过程,获得更加个性化和满意的结果。
3. 多智能体系统
ChatDiT的核心是一个多智能体系统,包含三个关键组件:
- 指令解析智能体(Instruction-Parsing Agent):负责解释用户上传的图像和指令,分析输入内容并提取关键信息。
- 策略规划智能体(Strategy-Planning Agent):根据指令解析智能体提供的信息,制定单步或多步生成动作的策略。它能够动态调整生成过程,确保输出符合用户的期望。
- 执行智能体(Execution Agent):使用预训练扩散Transformer的上下文工具包执行策略规划智能体制定的动作。它能够高效地生成高质量的视觉内容,同时保持与用户指令的一致性。
- 可选的Markdown智能体(Markdown Agent):将生成的图像和文本整合为连贯的插图文章,方便用户查看和分享。
工作原理
ChatDiT的核心是一个多智能体系统,包括:
- 指令解析智能体:解释用户指令和上传的图像,确定期望的输出图像数量,并为每个输入和目标图像生成详细描述。
- 策略规划智能体:根据解析的指令制定一步一步的生成计划,包括多面板提示、选定的参考图像ID和图像生成的必要参数。
- 执行智能体:使用上下文工具包执行计划的步骤,通过上下文操作生成所有目标图像。
此外,还有一个可选的Markdown智能体,用于将生成的图像和描述格式化为插图文章。
应用场景
1. 单轮对话
用户可以通过自然语言指令以及零或多张上传的图像作为输入,ChatDiT会自动生成一组图像,动态确定输出的数量和内容。例如,用户可以要求生成一幅描绘“日落时的海滩”的图像,ChatDiT会根据用户的描述生成相应的视觉内容。
2. 多轮对话
ChatDiT支持多轮交互,用户可以在不同轮次中提供新的指令或调整现有指令,逐步完善生成的内容。例如,用户可以先生成一幅“日落时的海滩”图像,然后在下一轮中要求添加“一艘帆船”或“一群海鸥”,ChatDiT会根据用户的反馈不断优化生成结果。
3. 插图文章生成
ChatDiT还可以用于生成完整的插图文章。用户可以提供一系列自然语言指令,ChatDiT会根据指令生成一系列相关的图像,并将其整合为一篇连贯的文章。例如,用户可以要求生成一篇关于“旅行日记”的文章,ChatDiT会根据用户的描述生成每一页的插图,形成一个完整的视觉故事。
与现有方法的对比
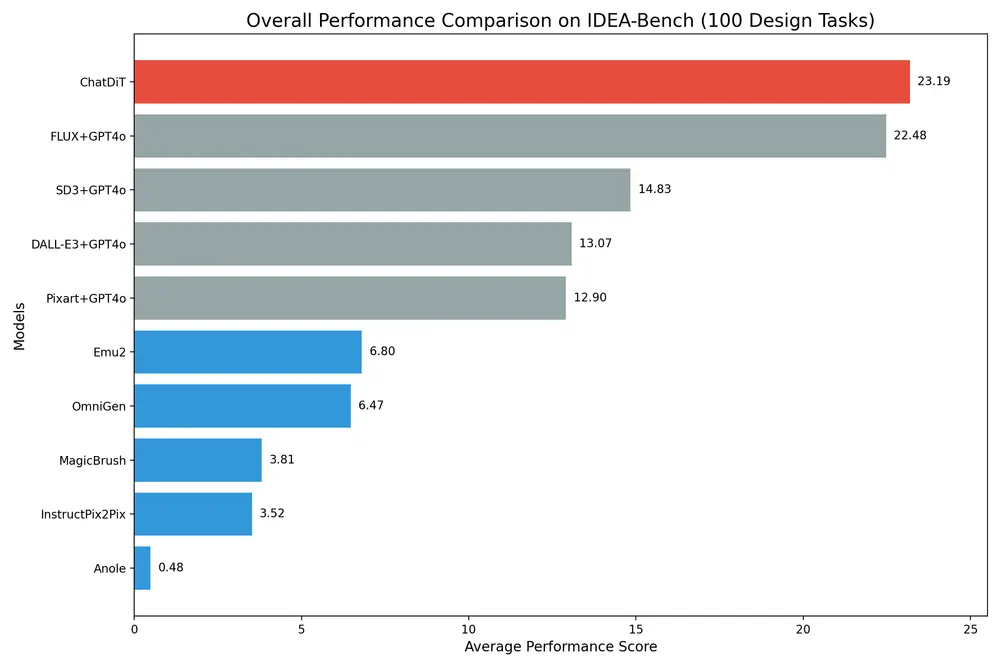
在IDEA-Bench基准测试中,ChatDiT的表现超越了所有竞争对手,包括那些专门设计和训练于广泛多任务数据集的模型。尽管其方法简单且无需训练,ChatDiT仍然能够在多样化的指令和输入-输出设置下取得优异的成绩。具体来说,ChatDiT在Top-1表现得分为23.19分(满分100分),反映了其在零样本任务泛化方面的强大能力。
然而,研究团队也指出了ChatDiT在某些任务上的局限性。例如,预训练DiTs在适应某些特定任务时可能面临挑战,特别是在需要高度专业化的视觉生成任务中。未来的研究将继续探索如何进一步提升ChatDiT的性能,尤其是在复杂任务上的表现。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











