
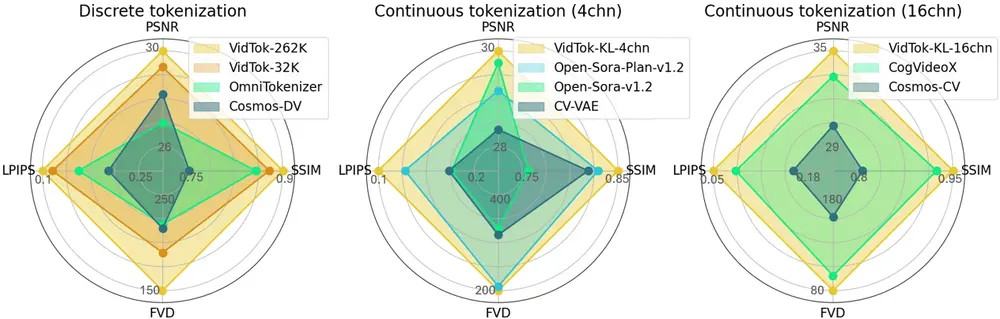
微软研究院、上海交通大学和北京大学的研究人员推出视频分词器VidTok,它是一个多功能且开源的工具,用于将视频内容编码成紧凑的潜在标记(latent tokens)。VidTok在连续和离散标记化方面都达到了最先进的性能。这个工具的开发是为了应对像素级表示中固有的冗余问题,并满足视频生成和理解领域日益增长的研究需求。
例如,我们有一段4K分辨率的视频,需要将其压缩以便更高效地存储和处理。使用VidTok,我们可以将这段视频转换成一系列紧凑的潜在标记,这些标记捕捉了视频的关键信息,并且可以在后续的步骤中用于视频生成或理解任务。例如,VidTok可以用于虚拟现实(VR)应用中,将现实世界的场景实时转换成数字内容,或者在视频编辑软件中用于提高视频处理的效率。
主要功能和特点
- 多模态输入支持:VidTok可以接受文本提示、参数化人体模型、服装图像和面部图像等多种输入,支持个性化的人物外观、姿势和体型调整。
- 连续和离散标记化:VidTok支持连续和离散两种类型的视频标记化,提供了灵活的输出选项。
- 高效的模型架构:通过使用2D和3D卷积层以及上/下采样模块,VidTok在不牺牲重建质量的同时减少了计算复杂度。
- 先进的量化技术:引入了有限标量量化(FSQ)技术,提高了离散视频标记化的性能。
- 改进的训练策略:采用两阶段训练过程和降低帧率的训练数据,提高了模型的训练效率和动态表示能力。
工作原理
VidTok的核心是一个编码器-解码器架构,其中编码器将输入视频压缩成潜在标记,而解码器则将这些标记重新构建成像素空间中的视频。VidTok通过以下几个关键步骤实现:
- 模型架构:使用2D卷积进行空间上/下采样,AlphaBlender操作符进行时间上/下采样,以及3D卷积进行信息融合。
- 有限标量量化(FSQ):在离散视频标记化中,FSQ通过将潜在表示中的每个标量条目独立量化到预定义的标量值,从而避免了传统向量量化(VQ)中的训练不稳定性和码本崩溃问题。
- 改进的训练策略:包括在低分辨率视频上预训练完整模型,然后在高分辨率视频上仅微调解码器,以及使用降低帧率的训练数据来提高模型对运动动态的表示能力。
具体应用场景
- 视频生成:使用VidTok生成新的视频内容,例如虚拟现实(VR)和增强现实(AR)应用。
- 视频理解:在视频分析任务中,如动作识别、视频分类等,使用VidTok提取的视频特征进行更有效的分析。
- 视频编辑和后期制作:在视频编辑软件中,使用VidTok提高视频处理和编辑的效率。
- 视频压缩和存储:将视频内容转换成紧凑的潜在标记,以减少存储空间和传输带宽需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











