
近年来,多模态大语言模型(MLLMs)在图像理解、生成和编辑任务中取得了显著进展。然而,现有的统一模型在同时处理这三种任务时面临挑战。例如,早期的模型(如 Chameleon 和 EMU3)使用 VQGAN 进行图像离散化,但在视觉理解任务中表现不佳。后来的模型(如 LaViT 和 ILLUME)引入了语义编码器来提升图像-文本对齐,但在图像编辑任务中由于缺乏纹理保留而表现欠佳。此外,Janus 系列通过解耦视觉输入和输出表示来处理图像理解与生成任务,但这种方法限制了模型在多轮对话和交错生成任务中的灵活性。
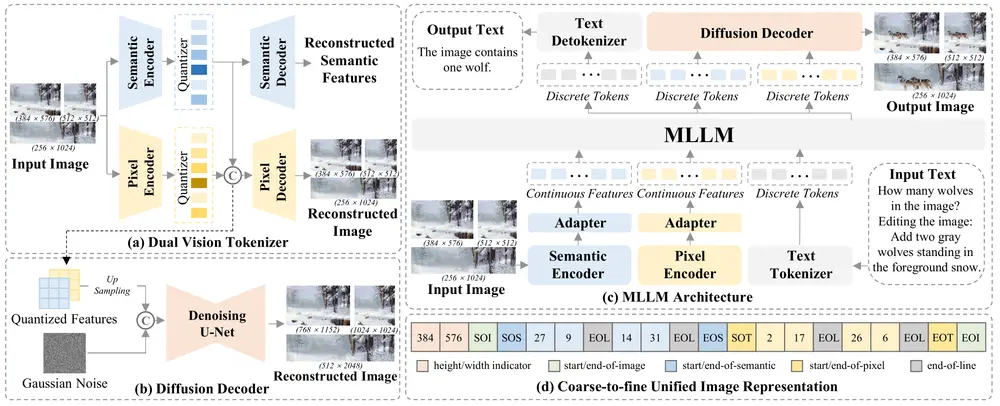
华为诺亚方舟实验室和香港大学的研究人员推出增强版多模态大语言模型(MLLM)ILLUME+ ,它通过双视觉标记化(Dual Visual Tokenization)和扩散解码器(Diffusion Decoder)来提升深度语义理解和高保真图像生成的能力。ILLUME+ 在统一模型中整合了图像理解、生成和编辑的能力,支持任意分辨率的视觉输入和输出,并在多种多模态任务中表现出色。
主要功能
- 多模态理解:ILLUME+ 能够准确理解图像内容,并在多种视觉理解任务中表现出色,例如图像问答(VQA)和文档理解。
- 图像生成:ILLUME+ 支持高分辨率图像生成,能够根据文本描述生成高质量的图像,支持多种分辨率的输出。
- 图像编辑:ILLUME+ 能够根据指令对图像进行编辑,例如添加、删除或修改图像中的对象,同时保留图像的其他部分不变。
- 灵活的分辨率支持:ILLUME+ 支持任意分辨率的视觉输入和输出,能够处理从低分辨率到高分辨率的图像。

主要特点
- 双视觉标记化(DualViTok):通过语义分支和像素分支捕获深度语义和细粒度纹理信息,确保图像的语义和纹理在标记化过程中得到保留。
- 扩散解码器:用于从离散标记解码图像,提升生成质量,并支持高效的超分辨率。
- 统一的图像表示:采用从粗到细的图像表示策略,先生成语义标记,再生成像素标记,支持统一的文本和图像头。
- 动态分辨率训练:通过逐步增加分辨率和任务复杂性,确保模型在不同分辨率下的稳定训练和最终性能。

工作原理
- 双视觉标记化(DualViTok):语义分支利用预训练的文本对齐视觉编码器提取高级语义特征,像素分支则通过量化特征来增强像素级重建。训练时引入噪声注入,通过随机扰动视觉标记来提高解码器对错误标记预测的鲁棒性。
- 统一的多模态大语言模型(MLLM):采用连续输入、离散输出方案,使用预量化连续特征作为输入,生成离散标记用于图像合成。通过统一的 LM 头和简单的词汇扩展,支持语义视觉标记作为文本和视觉纹理对齐的桥梁。
- 扩散解码器:作为可选的图像解码器,扩散模型在解码过程中细化细节,减少伪影,提升生成质量和鲁棒性。同时,通过在解码过程中进行图像上采样,缓解了自回归高分辨率生成中的标记爆炸问题。
- 动态分辨率训练:通过逐步增加分辨率和任务复杂性,确保模型在不同分辨率下的稳定训练和最终性能。训练过程包括视觉嵌入初始化、统一图像-文本对齐和监督微调三个阶段。
应用场景
- 图像理解:在文档理解、图像问答等任务中,ILLUME+ 能够准确理解图像内容并提供相关答案。例如,在文档图像问答任务中,模型可以理解文档内容并回答相关问题。
- 图像生成:根据文本描述生成高质量图像,支持多种分辨率输出。例如,用户可以输入“一只在雪山上奔跑的棕色狗”来生成相应的图像。
- 图像编辑:根据用户指令对图像进行编辑,例如添加、删除或修改图像中的对象。例如,用户可以要求模型“将背景改为雪山”或“删除墙上的画”。
- 多轮对话:在多轮对话中,ILLUME+ 能够处理交错的图像和文本任务,支持灵活的交互。例如,在对话中用户可以先上传一张图像,然后要求模型对其进行编辑,接着继续对话。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











