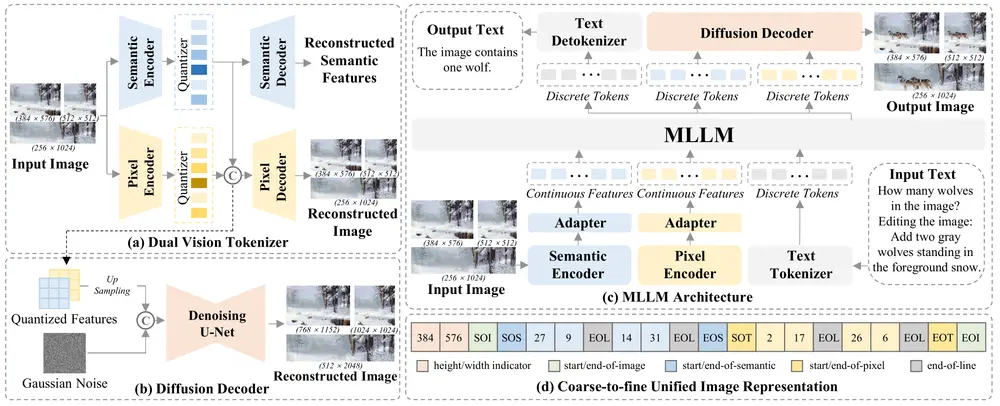
增强版多模态大语言模型ILLUME+ :通过双视觉标记化和扩散解码器来提升深度语义理解和高保真图像生成的能力近年来,多模态大语言模型(MLLMs)在图像理解、生成和编辑任务中取得了显著进展。然而,现有的统一模型在同时处理这三种任务时面临挑战。例如,早期的模型(如 Chameleon 和 EMU3)使用 VQ...多模态模型# ILLUME# 图像生成# 多模态大语言模型1年前05700