复旦大学自然语言处理实验室近期推出了SpeechGPT 2.0-preview,这是他们为实现情景智能而开发的第一个拟人化实时交互系统。基于百万小时级别的语音数据训练而成,这款端到端的语音大模型不仅能够实现低至百毫秒级的响应延迟,支持自然流畅的实时打断交互,还能在语音和文本模态之间达到良好的对齐。
- 项目主页:https://www.open-moss.com/cn/speechgpt2-preview
- GitHub:https://github.com/OpenMOSS/SpeechGPT-2.0-preview
- 模型:https://huggingface.co/fnlp
主要特性
- 拟人口语化表达与低延迟响应:SpeechGPT 2.0-preview 支持多情感、多风格、多音色的控制与智能切换,并能模拟各类角色的语气和情感状态。
- 多种语音才艺:包括诗歌朗诵、故事讲述以及方言说唱等。
- 出色的智商与文本能力:除了强大的语音表现力外,还支持工具调用、联网搜索及外挂知识库等功能。但需注意的是,目前该模型仅在中文语音数据上进行了训练,因此不具备英文对话能力。
技术方法简介
为了构建这样一个高度复杂的系统,研究团队采取了多项创新技术:
- 自研语义-声学联合建模的超低比特率流式语音Codec:实现了24kHz语音输入,750bps的低比特率,同时支持流式输入输出。
- 高效的语音数据爬取与清洗系统:通过多功能高效率的语音数据清洗pipeline和全方面多粒度的语音数据标注系统,积累了大量高质量的语音数据。
- 高度口语化的对话语音合成系统:能够生成数十万小时的多角色多风格语音对话数据,进一步增强了模型的学习能力。
- 新的语音文本混合建模模型架构:结合多阶段训练流程,确保模型在保持语音能力的同时不失文本理解能力。
实验观察与结论
实验过程中发现,通过充分的语音文本对齐预训练,模型能够自发地展现出语音风格的泛化性,如无需专门调整语速的数据训练即可实现语速控制,或扮演未曾见过的角色与风格。此外,语音数据合成引擎的质量对于提升各训练阶段的能力至关重要。
设计亮点
- Codec Patchify:通过将相邻时间步的RVQ codec token聚合为一个patch来减小语音和文本序列之间的差异,从而缓解跨模态建模中的冲突问题。
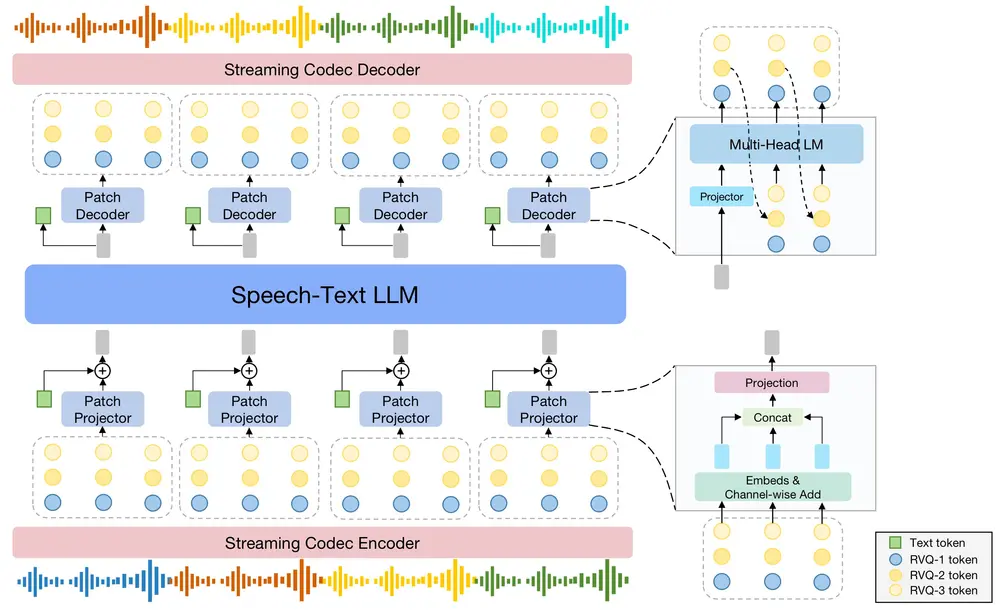
- 多解码头自回归语言模型作为Patch Decoder:这种设计使得模型能够以自回归的方式逐步解码,每次生成一个时间步的多个RVQ codec token,进而输出语音。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...