北京大学和香港中文大学的研究人员推出先进统一视觉自回归模型VARGPT-v1.1 ,该模型在多模态理解和文本到图像生成任务中表现出色。它通过迭代指令微调和强化学习等创新训练策略,显著提升了模型的性能。
- 项目主页:https://vargpt1-1.github.io
- GitHub:https://github.com/VARGPT-family/VARGPT-v1.1
- 模型:https://huggingface.co/VARGPT-family/VARGPT-v1.1
VARGPT-v1.1 是一种基于自回归架构的多模态大语言模型(MLLM),旨在统一视觉理解和图像生成任务。它继承了前代模型 VARGPT 的架构,通过预测下一个标记(token)实现视觉理解,通过预测下一个尺度(scale)实现图像生成。VARGPT-v1.1 的核心目标是通过改进训练策略和数据集,提升模型在多模态任务中的表现,同时保持架构的一致性。

主要功能
- 多模态理解:能够处理文本和图像的混合输入,并输出相应的文本或图像。
- 文本到图像生成:根据用户提供的文本指令生成高质量的图像。
- 图像编辑:通过指令微调,模型能够对图像进行风格转换等编辑操作,而无需额外的架构修改。
- 指令遵循:能够理解并遵循复杂的文本指令,生成符合要求的图像或回答问题。
主要特点
- 迭代指令微调与强化学习:结合迭代视觉指令微调和通过直接偏好优化(DPO)的强化学习,提升模型的生成质量和指令遵循能力。
- 大规模训练数据:使用了包含 830 万视觉生成指令对的扩展训练语料库,数据量是前代模型的 6 倍。
- 升级的语言模型骨干:采用 Qwen2 作为语言模型骨干,提升模型的性能和效率。
- 增强的图像生成分辨率:支持从 256×256 到 512×512 的分辨率提升,生成更高质量的图像。
- 无需架构修改的图像编辑能力:通过指令微调,模型能够实现图像编辑功能,而无需对架构进行修改。
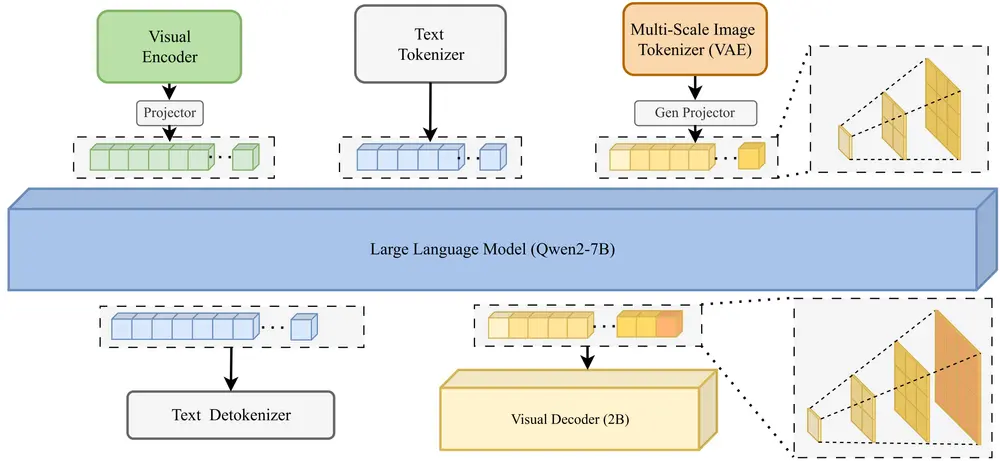
工作原理
VARGPT-v1.1 的工作原理基于以下关键组件:
- 模型架构:
- 视觉理解:使用 Qwen2 作为语言模型骨干,结合视觉编码器和投影器,通过预测下一个标记实现视觉理解。
- 图像生成:采用多尺度图像标记器和视觉解码器,通过预测下一个尺度生成图像。
- 训练策略:
- 预训练:在大规模数据上进行预训练,学习基本的视觉和语言表示。
- 指令微调:通过监督学习对模型进行微调,使其能够遵循文本指令生成图像。
- 强化学习:使用 DPO 对模型进行强化学习,优化生成图像的质量和用户偏好。
- 数据集:
- 视觉生成数据集:包含 830 万对真实世界和合成数据的指令对。
- 视觉理解数据集:使用 LLaVA-1.5 和 LLaVA-OneVision 等高质量数据集进行微调。
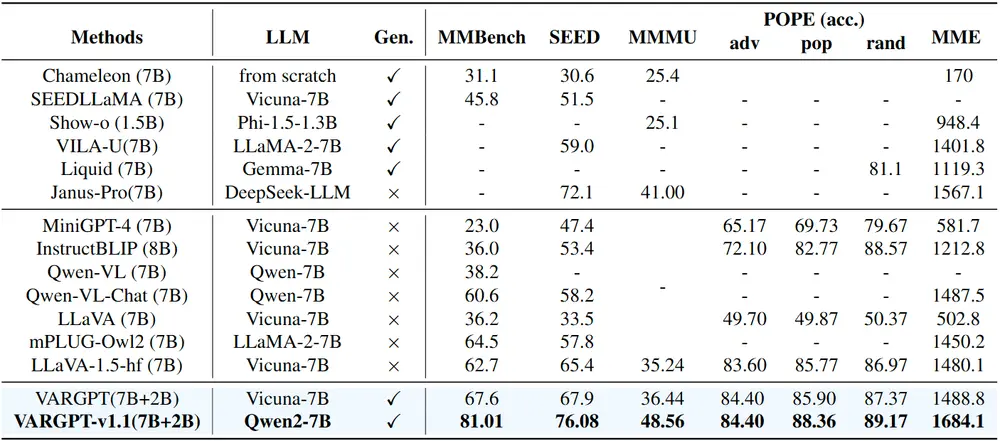
实验结果
VARGPT-v1.1 在多个多模态基准测试中表现出色,例如在 MMBench 上达到了 81.01% 的准确率,在 SEED 上达到了 76.08%。在图像生成任务中,它在 GenEval 和 DPG-Bench 上的性能也优于现有的生成模型。此外,VARGPT-v1.1 还展示了强大的图像编辑能力,能够根据用户指令对图像进行风格转换等操作。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











