
由抖音 SAIL 团队与新加坡国立大学 LV-NUS 实验室联合研发,SAIL-VL2 是一款全新的开源视觉语言基础模型(Vision-Language Model, LVM),在 2B 和 8B 参数规模下均实现当前最先进的性能表现,涵盖从 OCR 识别到数学推理等多类任务。
- GitHub:https://github.com/BytedanceDouyinContent/SAIL-VL2
- 模型:https://huggingface.co/collections/BytedanceDouyinContent/sail-vl2-68bc50cf86b8d6943ae83523
作为 SAIL-VL 的升级版本,SAIL-VL2 不仅提升了通用多模态理解能力,更通过创新训练范式,在细粒度感知与复杂推理两个关键维度上树立了新标杆。
核心能力概览
| 能力 | 示例 |
|---|---|
| 细粒度感知 | 准确识别图像中的文字内容并理解语义,适用于文档分析、OCR 场景 |
| 复杂推理 | 解析几何图形题、代数方程,并逐步推导出答案 |
| 高效架构设计 | 在 2B 小模型上达到甚至超越更大闭源模型的表现 |
| 开箱即用性 | 无需特殊提示,基础模型在 MMMU、MathVista 等高难度基准上具备强竞争力 |
关键亮点
✅ 强大而高效的 2B 模型
- 基于 7760 亿 token 的高质量多模态数据训练
- 在 106 个公开数据集 上验证有效性
- 即使不使用思维链(CoT)提示,也能在 MMMU、MathVista 等挑战性基准中取得领先结果
- 展现出卓越的“零样本迁移”能力
✅ SAIL-VL2-Thinking:专为复杂推理设计
针对标准 LVM 难以处理多步逻辑的问题,团队推出专用变体 SAIL-VL2-Thinking,采用:
- 高级 Chain-of-Thought(CoT)策略
- 强化学习(RL)优化最终答案正确率与输出格式一致性
该版本在多项推理任务中表现媲美甚至超过参数量更大的模型,重新定义了小模型在高级推理上的潜力。
✅ 细粒度视觉理解领先同级
在以下任务中显著优于同规模模型:
- 文本识别(OCR)
- 高分辨率文档布局解析
- 复杂图表与示意图理解
- 视觉 grounding(定位描述对应区域)
其对细节的捕捉能力和上下文关联建模能力尤为突出。
训练策略详解
1. 数据构建:高质量多模态语料库
SAIL-VL2 的训练依赖于系统化的数据管道,包含:
- 开源数据集的清洗与筛选
- 合成数据生成(用于增强稀有场景覆盖)
- 分阶段组织数据以匹配不同训练阶段需求
确保输入数据在多样性、准确性和分布合理性方面达到高标准。
2. 预训练阶段
(1)基础多模态对齐
- 使用 SAIL-ViT 作为视觉编码器
- LLM 主干 + 随机初始化 MLP 适配器连接视觉与语言空间
- 训练样本:64M
- 批次大小:2048
- 优化器:AdaLRS
(2)多任务预训练
- 解锁所有参数
- 加入指令微调数据
- 扩展至 180M 样本
- 停用 AdaLRS,进入全模型训练阶段
此阶段显著增强模型的视觉理解与指令遵循能力。
3. 后训练(Post-Training)
(1)基本监督微调(SFT)
四阶段渐进式微调,结合 Model Soup 技术融合多个同构模型,提升稳定性与泛化能力。
(2)LongCoT SFT
专门训练模型应对长链条推理问题,提升分步思考能力。
(3)可验证奖励强化学习(RL)
引入双目标奖励机制:
- 答案准确性
- 输出格式合规性(如 JSON 结构、步骤编号)
确保模型不仅“答得对”,还能“说得清”。
(4)Think-Fusion SFT 与混合奖励 RL
进一步融合推理能力与通用知识,通过 SFT 与 RL 的交替训练,实现推理深度与广度的平衡。
架构与工作原理
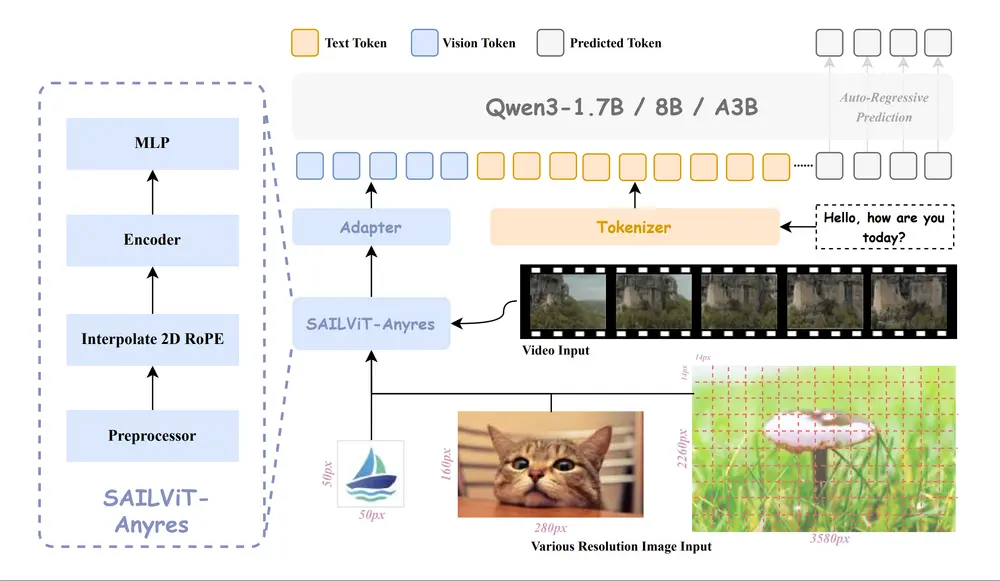
1. 视觉编码器:SAIL-ViT
将图像/视频编码为视觉 token 序列,与语言模型共享表示空间,支持高分辨率输入。
2. 多模态融合机制
- 通过轻量级适配器将视觉嵌入转换为语言空间中的标记
- 与文本嵌入联合输入 LLM 进行端到端推理
3. 渐进式训练流程
| 阶段 | 目标 | 参数更新范围 |
|---|---|---|
| 初始适应 | 粗粒度对齐视觉与语言 | 仅适配器 |
| 细粒度对齐 | 提升跨模态语义匹配 | 适配器 + 视觉编码器 |
| 世界知识注入 | 泛化能力提升 | 全参数解锁 |
4. 推理增强:MoE 与 Thinking 变体
- 支持稀疏 Mixture-of-Experts (MoE) 架构,在激活参数更少的情况下维持高性能
- SAIL-VL2-Thinking 专用于复杂任务,支持多步拆解与自我修正
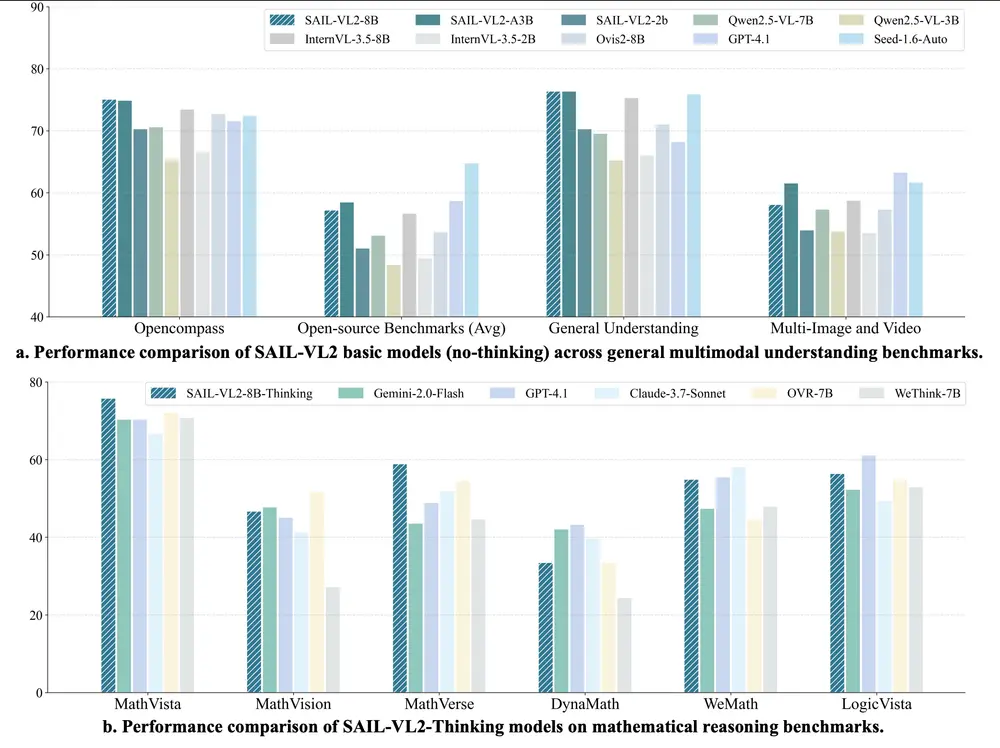
性能测试结果
多模态理解能力(MMBench-v1.1)
| 模型 | 分数 |
|---|---|
| SAIL-VL2-2B | 86.77 |
| SAIL-VL2-8B | 90.16 |
在同类规模中处于领先地位。
复杂推理能力(MathVista)
| 模型 | Zero-shot Score |
|---|---|
| SAIL-VL2-8B-Thinking | 75.8 |
| GPT-4V | 74.6 |
| Gemini Pro | 68.5 |
表现优于多个主流闭源模型。
效率与性能平衡(OpenCompass 多模态推理)
| 模型 | 激活参数 | 分数 |
|---|---|---|
| SAIL-VL2-MoE-Thinking | ~3B | 53.6 |
在较低计算成本下实现高效推理,适合部署场景。
主要功能总结
| 功能 | 说明 |
|---|---|
| 多模态理解 | 支持图像与视频输入,结合语言描述完成综合判断 |
| 复杂推理 | 可处理数学题、逻辑谜题、因果推断等需多步思考的任务 |
| 高效训练与推理 | 创新的数据筛选、渐进式训练框架与 MoE 设计降低资源消耗 |
| 完全开源 | 提供完整模型权重、推理代码与训练配置,支持社区二次开发 |
主要技术特点
- 高质量数据筛选机制
通过评分与过滤策略构建高信噪比语料库,提升训练效率。 - 渐进式训练框架
从 ViT 编码器预训练开始,经多模态对齐、指令微调,最终通过 Think-Fusion 与 RL 强化推理能力。 - 架构创新:稀疏 MoE
扩展传统密集 LLM 为 MoE 结构,在保持性能的同时减少实际激活参数量。 - 专为推理优化的变体设计
SAIL-VL2-Thinking 通过 CoT 与 RL 联合训练,显著提升解决复杂问题的能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











