
韩国科学技术院和Naver的研究人员推出一种针对姿势引导的人像图像动画技术TCAN,该技术能有效抵抗姿态估计错误,并在时间维度上保持连贯。这是一个关于如何让静态图片中的人体动作起来的研究,具体来说,就是让图片中的人物根据某个动作序列(比如一个视频)来做出相应的动作。
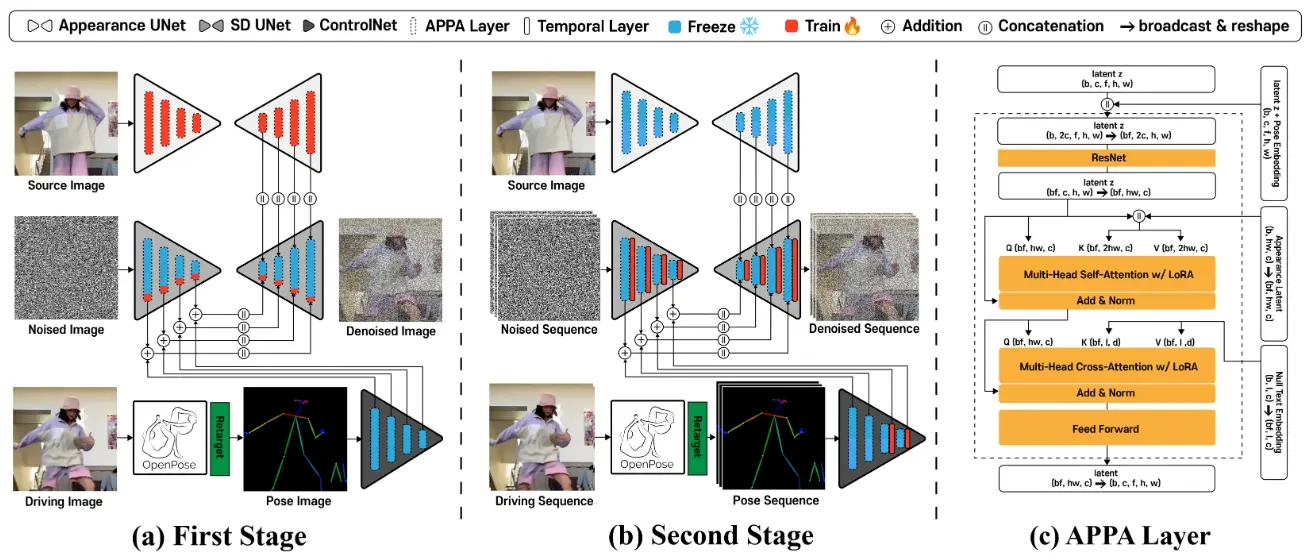
与先前技术相比,研究团队创新性地采纳了无需进一步调整的预训练ControlNet,借此利用其从大量姿态-图像-描述数据集中预先积累的深厚知识。为保持ControlNet的稳定状态,应用了LoRA至UNet架构的各层,从而使网络能有效协调姿态与外观特征的潜在表示空间。另外,增补一临时性层于ControlNet之中,增强了系统对姿态侦测器输出异常的抵抗能力。通过剖析跨时间轴的注意力图,研究团队独创了一种利用姿态资讯的温控图机制,有助于营造更稳定的背景效果。

例如,你有一个静态的图片,里面有一个卡通人物。你想让这个卡通人物在图片中跳舞。你可以使用TCAN技术,首先提取一个跳舞视频的姿势序列,然后将这些姿势信息输入到TCAN模型中。模型会根据这些姿势信息生成一个连贯的动画,让卡通人物在图片中跳起舞来。即使在姿势检测器出现错误的情况下,TCAN也能生成高质量的动画,保持动作的连贯性和自然性。
论文主题介绍
想象一下,你有一个静态的图片,里面有一个人,你想让这个人在图片中动起来,比如跳舞或者跑步。这就需要让图片中的人物根据某个动作序列来做出相应的动作。这就是TCAN技术要解决的问题。
主要功能
- 时间一致性:确保图片中的人物在动画过程中的动作是连贯的,不会因为时间的变化而出现动作的突变。
- 姿势引导:根据给定的姿势序列(比如从视频中提取的姿势)来生成动画。
- 鲁棒性:即使在姿势检测器出现错误的情况下,也能生成高质量的动画。
主要特点
- 预训练的ControlNet:使用预训练的ControlNet模型,而不是对其进行微调,以利用其从大量姿势-图像-标题对中获得的知识。
- LoRA适配:通过LoRA(Low-Rank Adaptation)技术适配UNet网络,使网络能够对齐姿势和外观特征的潜在空间。
- 时间层:在ControlNet中引入额外的时间层,增强对姿势检测器异常值的鲁棒性。
- 姿势驱动的温度图:设计了一种利用姿势信息的新型温度图,允许背景更加静态。
工作原理
TCAN的工作流程如下:
- 第一阶段:将源图像转换为与驱动视频的每个帧的姿势相匹配的图像。使用OpenPose提供驱动帧中的姿势信息作为ControlNet的输入。
- 第二阶段:通过添加时间层将图像生成模型扩展为视频生成模型。时间层帮助模型理解姿势序列的时间信息。
具体应用场景
- 社交媒体:用户可以上传静态图片,然后生成动态的个人资料视频。
- 娱乐和电影行业:可以用于生成电影或视频中的特效场景,比如让静态的海报中的人物动起来。
- 游戏开发:在游戏角色设计中,可以使用这种技术来生成角色的动作动画。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











